找到
556
篇与
酷游
相关的结果
-
 Java 14 发布了,再也不怕 NullPointerException 了! 2020年3月17日发布,Java正式发布了JDK 14 ,目前已经可以开放下载。在JDK 14中,共有16个新特性,本文主要来介绍其中的一个特性:JEP 358: Helpful NullPointerExceptions null何错之有? 对于Java程序员来说,null是令人头痛的东西。时常会受到空指针异常(NullPointerException)的骚扰。相信很多程序员都特别害怕出现程序中出现NPE,因为这种异常往往伴随着代码的非预期运行。 在编程语言中,空引用(Null Reference)是一个与空指针类似的概念,是一个已宣告但其并未引用到一个有效对象的变量。 在Java 1 中就包含了了Null引用和NPE了,但是其实,Null引用是伟大的计算机科学家Tony Hoare 早在1965年发明的,最初作为编程语言ALGOL W的一部分。 1965年,英国一位名为Tony Hoare的计算机科学家在设计ALGOL W语言时提出了null引用的想法。ALGOL W是第一批在堆上分配记录的类型语言之一。Hoare选择null引用这种方式,“只是因为这种方法实现起来非常容易”。虽然他的设计初衷就是要“通过编译器的自动检测机制,确保所有使用引用的地方都是绝对安全的”,他还是决定为null引用开个绿灯,因为他认为这是为“不存在的值”建模最容易的方式。 但是在2009年,很多年后,他开始为自己曾经做过这样的决定而后悔不已,把它称为“一个价值十亿美元的错误”。实际上,Hoare的这段话低估了过去五十年来数百万程序员为修复空引用所耗费的代价。因为在ALGOL W之后出现的大多数现代程序设计语言,包括Java,都采用了同样的设计方式,其原因是为了与更老的语言保持兼容,或者就像Hoare曾经陈述的那样,“仅仅是因为这样实现起来更加容易”。  相信很多Java程序员都一样对null和NPE深恶痛绝,因为他确实会带来各种各样的问题(来自《Java 8 实战》)。如: 它是错误之源。 NullPointerException是目前Java程序开发中最典型的异常。它会使你的代码膨胀。 它让你的代码充斥着深度嵌套的null检查,代码的可读性糟糕透顶。 它自身是毫无意义的。 null自身没有任何的语义,尤其是是它代表的是在静态类型语言中以一种错误的方式对缺失变量值的建模。 它破坏了Java的哲学。 Java一直试图避免让程序员意识到指针的存在,唯一的例外是:null指针。 它在Java的类型系统上开了个口子。 null并不属于任何类型,这意味着它可以被赋值给任意引用类型的变量。这会导致问题, 原因是当这个变量被传递到系统中的另一个部分后,你将无法获知这个null变量最初赋值到底是什么类型。 其他语言如何解决NPE问题 我们知道,出了Java语言外,还有很多其他的面向对象语言,那么在其他的一些语言中,是如何解决NPE的问题的呢? 如在Groovy中使用安全导航操作符(Safe Navigation Operator)可以访问可能为null的变量: def carInsuranceName = person?.car?.insurance?.name Groovy的安全导航操作符能够避免在访问这些可能为null引用的变量时发生NullPointerException,在调用链中的变量遭遇null时将null引用沿着调用链传递下去,返回一个null。 其实这个功能曾经考虑过增加一个类似的功能,但是后来又被舍弃了。 另外,在Haskell和Scala也有类似的替代品,如Haskell中的Maybe类型、Scala中的Option[T]。 在 Kotlin 中,其类型系统严格区分一个引用可以容纳 null 还是不能容纳。也就是说,一个变量是否可空必须显示声明,对于可空变量,在访问其成员时必须做空处理,否则无法编译通过: var a: String = "abc" a = null // 编译错误 果允许为空,可以声明一个可空字符串,写作 String?: var b: String? = "abc" //String? 表示该 String 类型变量可为空 b = null // 编译通过 看到这个?的时候,是不是发现和Groovy有点像?不过还是有一定区别的,这里就不展开了。 好了,书归正传,我们来看看作为一个TOIBE编程语言排行榜第一名的语言,Java语言对于NPE做出了哪些努力! Java做了哪些努力 一直以来对于null和NPE的改进还是做出了一些努力的。 首先在Java 8中提供了Optional,其实在Java 8 推出之前,Google的Guava库中就率先提供过Optional接口来使null快速失败。 Optional在可能为null的对象上做了一层封装,Optional对象包含了一些方法来显式地处理某个值是存在还是缺失,Optional类强制你思考值不存在的情况,这样就能避免潜在的空指针异常。 但是设计Optional类的目的并不是完全取代null,它的目的是设计更易理解的API。通过Optional,可以从方法签名就知道这个函数有可能返回一个缺失的值,这样强制你处理这些缺失值的情况。 关于Optional的用法,不是本文的重点,就不在这里详细介绍了,笔者在日常开发中经常结合Stream一起使用Optional,还是比较好用的。 另外一个值得一提的就是最近(2020年03月17日)发布的JDK 14中对于NPE有了一个增强。那就是JEP 358: Helpful NullPointerExceptions 更有帮助的NPE JDK 14中对于NEP有了一个增强,既然NPE暂时无法避免,那么就让他对开发者更有帮助一些。  每个Java开发人员都遇到过NullPointerExceptions (NPEs)。由于NPEs可以发生在程序的几乎任何地方,试图捕获并从它们中恢复通常是不切实际的。因此,开发人员通常依赖于JVM来确定NPE实际发生时的来源。例如,假设在这段代码中出现了一个NPE: a.i = 99; JVM将打印出导致NPE的方法、文件名和行号: Exception in thread "main" java.lang.NullPointerException at Prog.main(Prog.java:5) 通过以上堆栈信息,开发人员可以定位到a.i= 99这一行,并推断出a一定是null。 但是,对于更复杂的代码,如果不使用调试器,就不可能确定哪个变量是null。假设在这段代码中出现了一个NPE: a.b.c.i = 99; 我们根本无法确定到底是a还是b或者是c在运行时是个null值。 但是,在JDK14以后,这种窘境就有解了。 在JDK14中,当运行期,试图对一个null对象进行应用时,JVM依然会抛出一个NullPointerException (NPE),除此之外,还会通过通过分析程序的字节码指令,JVM将精确地确定哪个变量是null,并且在堆栈信息中明确的提示出来。 在JDK 14中,如果上文中的a.i = 99发生NPE,将会打印如下堆栈: Exception in thread "main" java.lang.NullPointerException: Cannot assign field "i" because "a" is null at Prog.main(Prog.java:5) 如果是a.b.c.i = 99;中的b为null导致了空指针,则会打印以下堆栈信息: Exception in thread "main" java.lang.NullPointerException: Cannot read field "c" because "a.b" is null at Prog.main(Prog.java:5) 可见,堆栈中明确指出了到底是哪个对象为null而导致了NPE,这样,一旦应用中发生NPE,开发者可以通过堆栈信息第一时间定位到到底是代码中的那个对象为null导致的。 这算是JDK的一个小小的改进,但是这个改进对于开发者来说确实是非常友好的。真的希望这些小而美的改动可以在JDK中越来越多。 参考资料: https://openjdk.java.net/jeps/358 《Java 8 In Action》
Java 14 发布了,再也不怕 NullPointerException 了! 2020年3月17日发布,Java正式发布了JDK 14 ,目前已经可以开放下载。在JDK 14中,共有16个新特性,本文主要来介绍其中的一个特性:JEP 358: Helpful NullPointerExceptions null何错之有? 对于Java程序员来说,null是令人头痛的东西。时常会受到空指针异常(NullPointerException)的骚扰。相信很多程序员都特别害怕出现程序中出现NPE,因为这种异常往往伴随着代码的非预期运行。 在编程语言中,空引用(Null Reference)是一个与空指针类似的概念,是一个已宣告但其并未引用到一个有效对象的变量。 在Java 1 中就包含了了Null引用和NPE了,但是其实,Null引用是伟大的计算机科学家Tony Hoare 早在1965年发明的,最初作为编程语言ALGOL W的一部分。 1965年,英国一位名为Tony Hoare的计算机科学家在设计ALGOL W语言时提出了null引用的想法。ALGOL W是第一批在堆上分配记录的类型语言之一。Hoare选择null引用这种方式,“只是因为这种方法实现起来非常容易”。虽然他的设计初衷就是要“通过编译器的自动检测机制,确保所有使用引用的地方都是绝对安全的”,他还是决定为null引用开个绿灯,因为他认为这是为“不存在的值”建模最容易的方式。 但是在2009年,很多年后,他开始为自己曾经做过这样的决定而后悔不已,把它称为“一个价值十亿美元的错误”。实际上,Hoare的这段话低估了过去五十年来数百万程序员为修复空引用所耗费的代价。因为在ALGOL W之后出现的大多数现代程序设计语言,包括Java,都采用了同样的设计方式,其原因是为了与更老的语言保持兼容,或者就像Hoare曾经陈述的那样,“仅仅是因为这样实现起来更加容易”。  相信很多Java程序员都一样对null和NPE深恶痛绝,因为他确实会带来各种各样的问题(来自《Java 8 实战》)。如: 它是错误之源。 NullPointerException是目前Java程序开发中最典型的异常。它会使你的代码膨胀。 它让你的代码充斥着深度嵌套的null检查,代码的可读性糟糕透顶。 它自身是毫无意义的。 null自身没有任何的语义,尤其是是它代表的是在静态类型语言中以一种错误的方式对缺失变量值的建模。 它破坏了Java的哲学。 Java一直试图避免让程序员意识到指针的存在,唯一的例外是:null指针。 它在Java的类型系统上开了个口子。 null并不属于任何类型,这意味着它可以被赋值给任意引用类型的变量。这会导致问题, 原因是当这个变量被传递到系统中的另一个部分后,你将无法获知这个null变量最初赋值到底是什么类型。 其他语言如何解决NPE问题 我们知道,出了Java语言外,还有很多其他的面向对象语言,那么在其他的一些语言中,是如何解决NPE的问题的呢? 如在Groovy中使用安全导航操作符(Safe Navigation Operator)可以访问可能为null的变量: def carInsuranceName = person?.car?.insurance?.name Groovy的安全导航操作符能够避免在访问这些可能为null引用的变量时发生NullPointerException,在调用链中的变量遭遇null时将null引用沿着调用链传递下去,返回一个null。 其实这个功能曾经考虑过增加一个类似的功能,但是后来又被舍弃了。 另外,在Haskell和Scala也有类似的替代品,如Haskell中的Maybe类型、Scala中的Option[T]。 在 Kotlin 中,其类型系统严格区分一个引用可以容纳 null 还是不能容纳。也就是说,一个变量是否可空必须显示声明,对于可空变量,在访问其成员时必须做空处理,否则无法编译通过: var a: String = "abc" a = null // 编译错误 果允许为空,可以声明一个可空字符串,写作 String?: var b: String? = "abc" //String? 表示该 String 类型变量可为空 b = null // 编译通过 看到这个?的时候,是不是发现和Groovy有点像?不过还是有一定区别的,这里就不展开了。 好了,书归正传,我们来看看作为一个TOIBE编程语言排行榜第一名的语言,Java语言对于NPE做出了哪些努力! Java做了哪些努力 一直以来对于null和NPE的改进还是做出了一些努力的。 首先在Java 8中提供了Optional,其实在Java 8 推出之前,Google的Guava库中就率先提供过Optional接口来使null快速失败。 Optional在可能为null的对象上做了一层封装,Optional对象包含了一些方法来显式地处理某个值是存在还是缺失,Optional类强制你思考值不存在的情况,这样就能避免潜在的空指针异常。 但是设计Optional类的目的并不是完全取代null,它的目的是设计更易理解的API。通过Optional,可以从方法签名就知道这个函数有可能返回一个缺失的值,这样强制你处理这些缺失值的情况。 关于Optional的用法,不是本文的重点,就不在这里详细介绍了,笔者在日常开发中经常结合Stream一起使用Optional,还是比较好用的。 另外一个值得一提的就是最近(2020年03月17日)发布的JDK 14中对于NPE有了一个增强。那就是JEP 358: Helpful NullPointerExceptions 更有帮助的NPE JDK 14中对于NEP有了一个增强,既然NPE暂时无法避免,那么就让他对开发者更有帮助一些。  每个Java开发人员都遇到过NullPointerExceptions (NPEs)。由于NPEs可以发生在程序的几乎任何地方,试图捕获并从它们中恢复通常是不切实际的。因此,开发人员通常依赖于JVM来确定NPE实际发生时的来源。例如,假设在这段代码中出现了一个NPE: a.i = 99; JVM将打印出导致NPE的方法、文件名和行号: Exception in thread "main" java.lang.NullPointerException at Prog.main(Prog.java:5) 通过以上堆栈信息,开发人员可以定位到a.i= 99这一行,并推断出a一定是null。 但是,对于更复杂的代码,如果不使用调试器,就不可能确定哪个变量是null。假设在这段代码中出现了一个NPE: a.b.c.i = 99; 我们根本无法确定到底是a还是b或者是c在运行时是个null值。 但是,在JDK14以后,这种窘境就有解了。 在JDK14中,当运行期,试图对一个null对象进行应用时,JVM依然会抛出一个NullPointerException (NPE),除此之外,还会通过通过分析程序的字节码指令,JVM将精确地确定哪个变量是null,并且在堆栈信息中明确的提示出来。 在JDK 14中,如果上文中的a.i = 99发生NPE,将会打印如下堆栈: Exception in thread "main" java.lang.NullPointerException: Cannot assign field "i" because "a" is null at Prog.main(Prog.java:5) 如果是a.b.c.i = 99;中的b为null导致了空指针,则会打印以下堆栈信息: Exception in thread "main" java.lang.NullPointerException: Cannot read field "c" because "a.b" is null at Prog.main(Prog.java:5) 可见,堆栈中明确指出了到底是哪个对象为null而导致了NPE,这样,一旦应用中发生NPE,开发者可以通过堆栈信息第一时间定位到到底是代码中的那个对象为null导致的。 这算是JDK的一个小小的改进,但是这个改进对于开发者来说确实是非常友好的。真的希望这些小而美的改动可以在JDK中越来越多。 参考资料: https://openjdk.java.net/jeps/358 《Java 8 In Action》
-
雷军写代码水平如何? 3月30日,小米集团发布公告,公司拟成立一家全资子公司,负责智能电动汽车业务。首期投资为100亿元人民币,预计未来10年投资额100亿美元,而智能电动汽车业务的首席执行官依然由雷军担任。 雷军说:我愿意押上我人生全部的声誉,再次披挂上阵,为小米汽车而战! 身为小米创始人,雷军展现在观众面前的形象往往是顶着一头六七十年代的三七分发型,身穿偏大西装,浑身散发着一股朴素土味乡村企业家的气息,实在与商业精英的形象没那么相符。 反而大家更加熟悉的那个雷总,是B站三巨头之一,单曲播放量第一的大佬,B站鬼畜镇店之宝。 从大学期间的写代码和创业,到加入金山公司实现财务自由,再到创立互联网手机品牌,建立小米生态。 赤手空拳打下一方天地的雷军不仅是我们茶余饭后调侃的谈资,更是我们不可复制的未来。 他的代码水平到底如何? 在20年前的《电脑爱好者》杂志上,雷军曾说过一句话:编程不只是技术也还是艺术。 1988年,雷军在武汉大学就读大一期间编写的Pascal程序,在他大二时就被编进了新生教材,原因正是雷军所编写的代码像艺术一样优美。 在这不久后雷军便开始编写加密软件BITLOK,用户包括当时知名的软件公司用友、超想、金山等等,继而和冯志宏(中国知名共享软件作者,有“中国工具软件开发之父”之称)合作开发出了免疫90杀毒软件,在武汉大学获得科技成果一等奖,被湖北省公安厅专门请去讲课、传授反病毒技术。 毕业后,雷军进入金山软件的珠海研发部实习,并和金山老板求伯君一起编写的书籍《深入DOS编程》,1993年5月,雷军参与研发的金山Ⅵ型汉卡,及WPS-NT,广泛应用于行业,极大地提高了办公效率和工作质量,市场占有率高达90%以上。 1993-1995年,雷军参与金山“盘古计划”(WPS Office前身)利用休假时间(大概2-3个月)全部重写了BITLOK 3.0(改版前有约3万行代码),带领团队完成WPS97开发,销售额高达3万套。 在金山的16年中,雷军从金山公司的一个小职员一路升任到了总经理。 彼时马化腾的腾讯公司在华强东刚刚开张,李彦宏在搜信写代码,史玉柱的巨人大厦没有按期完工,天天被债主逼债。 如果当时雷军继续写代码,或许如今的中国就少了一个知名企业家,而是多了一名顶级IT大神。 不写代码一样很牛! 成为总经理后,雷军的心思依然不能全放在管理上,直到“金山新同事将雷军电脑格式化”的事故发生,雷军才不得不将所有精力放在管理上。 2002年,在雷军的领导下,100多位工程师历时3年,舍弃了积累十余年的程序架构,将500多万行代码全部推倒重写,为了降低用户学习成本尊重用户使用习惯做出了一款与微软完全兼容的产品WPS 2005。 一战成名,金钱和荣誉纷至沓来。 直到2007年金山的荣耀攀登到巅峰时,实现了财务自由的雷军才辞卸任金山CEO,本可以游山玩水,潇洒度过下半生的雷军几年后便开启了自己在时代的另一个使命。 2010年4月,雷军与五位合伙人创办小米科技,并在2011年8月公布其自有品牌手机小米手机。 小米首战告捷,站上了智能手机的风口,在10年的斗争中,举着性价比的大旗,打造出了中国自己的品牌,削了高质量手机的售价,拓宽了属于自己的市场。 2014年,小米手机出货量突破了6000千万台,成为中国出货量最高的手机厂商。 从那时起,小米科技一路高歌猛进成为了家喻户晓的“国民手机”。 2018年7月9日,小米在香港交易所主板挂牌上市。2019年6月,入选2019福布斯中国最具创新力企业榜。10月,2019福布斯全球数字经济100强榜发布,小米位列第56位。 2020年入选《财富》世界500强排行榜位列422位。 2021年3月30日,小米集团在港交所发布公告,正式宣布进入造车领域。同日,小米启用新Logo 小米最好的代言人 作为小米的CEO,雷军就是小米最好的代言人。 比如运用个人影响力,推销九号卡丁车兰博基尼联动款和皮卡丘联名款出行装,在接受采访时也不忘向观众介绍自家生态链中的彩虹电池。 就算被大佬怼,只要说到自家的产品,雷军也能云淡风轻的借此开始完成自己的销售额。 还记得几年前在乌镇大会上雷军被马云莫名怼了一句“周围的空气是不干净的,你手机做的再好有什么用呢”。 在之后的某次演讲中,雷军只开篇用了马云的调侃,便开始郑重其事的介绍自家生态链的空气净化器产品,定价899,滤网149,手机app可以呼唤上门更新滤网,宇宙敬业第一销售非雷布斯莫属。 从微博上的“我去工厂拧螺丝”到小米9发布会上演唱神曲“Are you ok?”,rapper雷军毫不费力便拿下了B站鬼畜区的代言人,小米找具有如此影响力的雷布斯带货,绝对是1+1大于2。 当然,事实也是如此,在昔日的直播首秀中,雷军称自己很紧张,为了避免出现“翻车”,自己带了一摞小抄,直播时,还不断和网友互动,有网友留言:“雷总的头发是怎么保养的,程序员头发都掉光了。” 雷军便说是因自己头发浓密被质疑是假程序员,并提醒大家要保护好头发,植发很贵的,每个人头顶都是一栋别墅。还吐糟公司内部情愿请明星来代言小米,都不愿意请他来代言。 如此幽默加亲民的形象,再配上面面俱招牌式的笑容,抖音带货成绩斐然,总销售金额为2.1亿元,累计观看人数达5053万人,订单数量破57万,抖音相关话题视频播放量破5亿,碾压罗永浩之前所创下的抖音直播带货记录。 如今作为互联网公司最敬业的CEO,雷军微博足足有2000多万粉丝,每逢小米新品,雷布斯总会准时更新,在营销上,说雷军每年为小米节省几十亿的费用一点都不为过。 在写这篇文章之前,我去看了很多人对雷军的评价,很起怪,大家对他的评价异常的高。很值有人说:可以黑小米,但是不能黑雷军! 雷军之所以值得佩服,大概是因为他其实是最接近你我的普通人吧,在他奋斗的历程靠的完全是自己的努力! 最后,祝福雷军,祝福小米!雷军加油,小米加油!
-
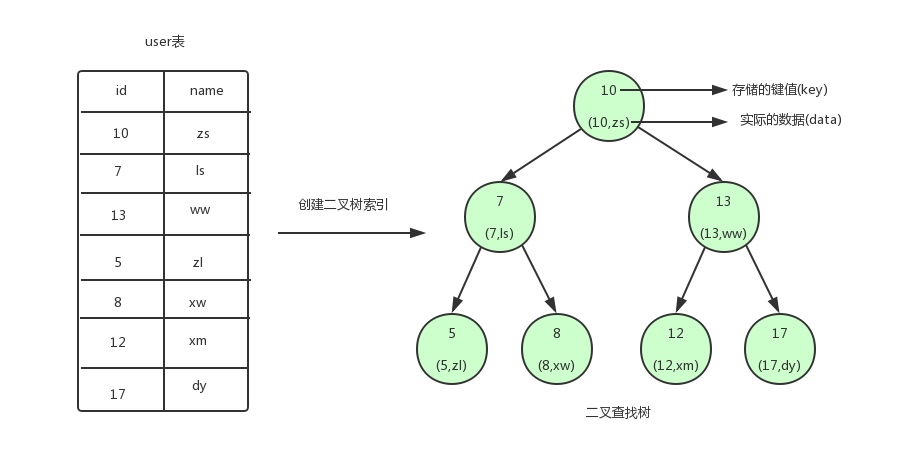
MySQL索引完全解读 索引这个词,相信大多数人已经相当熟悉了。不过为了文章的完整性,这里再啰嗦一下。索引是一种数据结构,用于帮助我们在大量数据中快速定位到我们想要查找的数据。 索引最形象的比喻就是图书的目录了。 注意这里的大量,数据量大了索引才显得有意义,如果我想要在[1,2,3,4]中找到4这个数据,直接对全数据检索也很快,没有必要费力气建索引再去查找。 索引在mysql数据库中分三类:1. B+树索引 2. Hash索引 3. 全文索引 我们今天要介绍的是工作开发中最常接触到innodb存储引擎中的的B+树索引。 2.二查找叉树、平衡二叉树、B树、B+树 要介绍B+树索引,就不得不提二叉查找树,平衡二叉树和B树这三种数据结构。B+树就是从他们仨演化来的。 2.1 二叉查找树 首先,让我们先看一张图  从图中可以看到,我们为user表(用户信息表)建立了一个二叉查找树的索引。图中的圆为二叉查找树的节点,节点中存储了键(key)和数据(data)。键对应user表中的id,数据对应user表中的行数据。二叉查找树的特点就是任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。 顶端的节点我们称为根节点,没有子节点的节点我们称之为叶节点。如果我们需要查找id=12的用户信息,利用我们创建的二叉查找树索引,查找流程如下: 1. 将根节点作为当前节点,把12与当前节点的键值10比较,12大于10,接下来我们把当前节点>的右子节点作为当前节点。 2. 继续把12和当前节点的键值13比较,发现12小于13,把当前节点的左子节点作为当前节点。 3. 把12和当前节点的键值12对比,12等于12,满足条件,我们从当前节点中取出data,即id=1>2,name=xm。 利用二叉查找树我们只需要3次即可找到匹配的数据。如果在表中一条条的查找的话,我们需要6次才能找到。 2.2 平衡二叉树 上面我们讲解了利用二叉查找树可以快速的找到数据。但是,如果上面的二叉查找树是这样的构造:  这个时候可以看到我们的二叉查找树变成了一个链表。如果我们需要查找id=17的用户信息,我们需要查找7次,也就相当于全表扫描了。 导致这个现象的原因其实是二叉查找树变得不平衡了,也就是高度太高了,从而导致查找效率的不稳定。 为了解决这个问题,我们需要保证二叉查找树一直保持平衡,就需要用到平衡二叉树了。平衡二叉树又称AVL树,在满足二叉查找树特性的基础上,要求每个节点的左右子树的高度不能超过1。 下面是平衡二叉树和非平衡二叉树的对比:  由平衡二叉树的构造我们可以发现第一张图中的二叉树其实就是一棵平衡二叉树。平衡二叉树保证了树的构造是平衡的,当我们插入或删除数据导致不满足平衡二叉树不平衡时,平衡二叉树会进行调整树上的节点来保持平衡。具体的调整方式这里就不介绍了。平衡二叉树相比于二叉查找树来说,查找效率更稳定,总体的查找速度也更快。 2.3 B树 因为内存的易失性。一般情况下,我们都会选择将user表中的数据和索引存储在磁盘这种外围设备中。但是和内存相比,从磁盘中读取数据的速度会慢上百倍千倍甚至万倍,所以,我们应当尽量减少从磁盘中读取数据的次数。 另外,从磁盘中读取数据时,都是按照磁盘块来读取的,并不是一条一条的读。 如果我们能把尽量多的数据放进磁盘块中,那一次磁盘读取操作就会读取更多数据,那我们查找数据的时间也会大幅度降低。 如果我们用树这种数据结构作为索引的数据结构,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块,我们都知道平衡二叉树可是每个节点只存储一个键值和数据的。那说明什么?说明每个磁盘块仅仅存储一个键值和数据!那如果我们要存储海量的数据呢?可以想象到二叉树的节点将会非常多,高度也会及其高,我们查找数据时也会进行很多次磁盘IO,我们查找数据的效率将会极低!  为了解决平衡二叉树的这个弊端,我们应该寻找一种单个节点可以存储多个键值和数据的平衡树。也就是我们接下来要说的B树。B树(Balance Tree)即为平衡树的意思,下图即是一颗B树。  注意:– 图中的p节点为指向子节点的指针,二叉查找树和平衡二叉树其实也有,因为图的美观性,被省略了。 – 图中的每个节点称为页,页就是我们上面说的磁盘块,在mysql中数据读取的基本单位都是页,所以我们这里叫做页更符合mysql中索引的底层数据结构。 从上图可以看出,B树相对于平衡二叉树,每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点,子节点的个数一般称为阶,上述图中的B树为3阶B树,高度也会很低。 基于这个特性,B树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衡二叉树高很多。假如我们要查找id=28的用户信息,那么我们在上图B树中查找的流程如下: 1. 先找到根节点也就是页1,判断28在键值17和35之间,我们那么我们根据页1中的指针p2找到页3。 2. 将28和页3中的键值相比较,28在26和30之间,我们根据页3中的指针p2找到页8。 3. 将28和页8中的键值相比较,发现有匹配的键值28,键值28对应的用户信息为(28,bv)。 注意: – B树的构造是有一些规定的,但这不是本文的关注点,有兴趣的同学可以令行了解。 – B树也是平衡的,当增加或删除数据而导致B树不平衡时,也是需要进行节点调整的。 2.4 B+树 B+树是对B树的进一步优化。让我们先来看下B+树的结构图:  根据上图我们来看下B+树和B树有什么不同。 1. B+树非叶子节点上是不存储数据的,仅存储键值,而B树节点中不仅存储键值,也会存储数据。之所以这么做是因为在数据库中页的大小是固定的,innodb中页的默认大小是16KB。如果不存储数据,那么就会存储更多的键值,相应的树的阶数(节点的子节点树)就会更大,树就会更矮更胖,如此一来我们查找数据进行磁盘的IO次数有会再次减少,数据查询的效率也会更快。另外,B+树的阶数是等于键值的数量的,如果我们的B+树一个节点可以存储1000个键值,那么3层B+树可以存储1000×1000×1000=10亿个数据。一般根节点是常驻内存的,所以一般我们查找10亿数据,只需要2次磁盘IO。 2. 因为B+树索引的所有数据均存储在叶子节点,而且数据是按照顺序排列的。那么B+树使得范围查找,排序查找,分组查找以及去重查找变得异常简单。而B树因为数据分散在各个节点,要实现这一点是很不容易的。有心的读者可能还发现上图B+树中各个页之间是通过双向链表连接的,叶子节点中的数据是通过单向链表连接的。其实上面的B树我们也可以对各个节点加上链表。其实这些不是它们之前的区别,是因为在mysql的innodb存储引擎中,索引就是这样存储的。也就是说上图中的B+树索引就是innodb中B+树索引真正的实现方式,准确的说应该是聚集索引(聚集索引和非聚集索引下面会讲到)。 通过上图可以看到,在innodb中,我们通过数据页之间通过双向链表连接以及叶子节点中数据之间通过单向链表连接的方式可以找到表中所有的数据。 MyISAM中的B+树索引实现与innodb中的略有不同。在MyISAM中,B+树索引的叶子节点并不存储数据,而是存储数据的文件地址。 3.聚集索引与非聚集索引 3.1 什么是聚集索引,什么是非聚集索引 在上节介绍B+树索引的时候,我们提到了图中的索引其实是聚集索引的实现方式。那什么是聚集索引呢? 在MySQL中,B+树索引按照存储方式的不同分为聚集索引和非聚集索引。这里我们着重介绍innodb中的聚集索引和非聚集索引。 1. 聚集索引(聚簇索引):以innodb作为存储引擎的表,表中的数据都会有一个主键,即使你不创建主键,系统也会帮你创建一个隐式的主键。这是因为innodb是把数据存放在B+树中的,而B+树的键值就是主键,在B+树的叶子节点中,存储了表中所有的数据。这种以主键作为B+树索引的键值而构建的B+树索引,我们称之为聚集索引。 2. 非聚集索引(非聚簇索引):以主键以外的列值作为键值构建的B+树索引,我们称之为非聚集索引。非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。明白了聚集索引和非聚集索引的定义,我们应该明白这样一句话:数据即索引,索引即数据。 3.2 利用聚集索引和非聚集索引查找数据 前面我们讲解B+树索引的时候并没有去说怎么在B+树中进行数据的查找,主要就是因为还没有引出聚集索引和非聚集索引的概念。下面我们通过讲解如何通过聚集索引以及非聚集索引查找数据表中数据的方式介绍一下B+树索引查找数据方法。 3.2.1 利用聚集索引查找数据  还是这张B+树索引图,现在我们应该知道这就是聚集索引,表中的数据存储在其中。现在假设我们要查找id>=18并且id=18 and id =18 and id
-
Java中的可变参数 什么是可变参数 可变参数(variable arguments)是在Java 1.5中引入的一个特性。它允许一个方法把任意数量的值作为参数。 public static void main(String[] args) { print("a"); print("a", "b"); print("a", "b", "c"); } public static void print(String ... s){ for(String a: s) System.out.println(a); } 可变参数的工作原理 可变参数在被使用的时候,他首先会创建一个数组,数组的长度就是调用该方法是传递的实参的个数,然后再把参数值全部放到这个数组当中,然后再把这个数组作为参数传递到被调用的方法中。 可变参数的使用场景 通过其定义我们知道,当一个方法可能要接收任意数量的参数的时候使用可变参数是非常有用的。Java SDK中有个很好的例子:String.format(String format, Object... args)。一个字符串可以中可以包含任意个待格式化参数,所以使用可变参数。 String.format("An integer: %d", i); String.format("An integer: %d and a string: %s", i, s);
-
Java中泛型的理解 Java泛型(generics) 是JDK 5中引入的一个新特性,允许在定义类和接口的时候使用类型参数(type parameter)。声明的类型参数在使用时用具体的类型来替换。泛型最主要的应用是在JDK 5中的新集合类框架中。对于泛型概念的引入,开发社区的观点是褒贬不一。从好的方面来说,泛型的引入可以解决之前的集合类框架在使用过程中通常会出现的运行时刻类型错误,因为编译器可以在编译时刻就发现很多明显的错误。而从不好的地方来说,为了保证与旧有版本的兼容性,Java泛型的实现上存在着一些不够优雅的地方。当然这也是任何有历史的编程语言所需要承担的历史包袱。后续的版本更新会为早期的设计缺陷所累。开发人员在使用泛型的时候,很容易根据自己的直觉而犯一些错误。比如一个方法如果接收List作为形式参数,那么如果尝试将一个List的对象作为实际参数传进去,却发现无法通过编译。虽然从直觉上来说,Object是String的父类,这种类型转换应该是合理的。但是实际上这会产生隐含的类型转换问题,因此编译器直接就禁止这样的行为。本文试图对Java泛型做一个概括性的说明。 类型擦除 Java的类型擦除 正确理解泛型概念的首要前提是理解类型擦除(type erasure)。 Java中的泛型基本上都是在编译器这个层次来实现的。在生成的Java字节代码中是不包含泛型中的类型信息的。使用泛型的时候加上的类型参数,会被编译器在编译的时候去掉。这个过程就称为类型擦除。如在代码中定义的List 和List等类型,在编译之后都会变成List。JVM看到的只是List,而由泛型附加的类型信息对JVM来说是不可见的。Java编译器会在编译时尽可能的发现可能出错的地方,但是仍然无法避免在运行时刻出现类型转换异常的情况。类型擦除也是Java的泛型实现方式与C++模板机制实现方式之间的重要区别。 很多泛型的奇怪特性都与这个类型擦除的存在有关,包括: 泛型类并没有自己独有的Class类对象。比如并不存在List.class或是List.class,而只有List.class。 静态变量是被泛型类的所有实例所共享的。对于声明为MyClass的类,访问其中的静态变量的方法仍然是 MyClass.myStaticVar。不管是通过new MyClass;还是new MyClass创建的对象,都是共享一个静态变量。 泛型的类型参数不能用在Java异常处理的catch语句中。因为异常处理是由JVM在运行时刻来进行的。由于类型信息被擦除,JVM是无法区分两个异常类型MyException;和MyException的。对于JVM来说,它们都是 MyException类型的。也就无法执行与异常对应的catch语句。 类型擦除的基本过程也比较简单: 首先是找到用来替换类型参数的具体类。这个具体类一般是Object。如果指定了类型参数的上界的话,则使用这个上界。把代码中的类型参数都替换成具体的类。同时去掉出现的类型声明,即去掉的内容。比如: T get()方法声明就变成了Object get(); List就变成了List。 接下来就可能需要生成一些桥接方法(bridge method)。这是由于擦除了类型之后的类可能缺少某些必须的方法。比如考虑下面的代码: class MyString implements Comparable { public int compareTo(String str) { return 0; } } 当类型信息被擦除之后,上述类的声明变成了class MyString implements Comparable。但是这样的话,类MyString就会有编译错误,因为没有实现接口Comparable声明的int compareTo(Object)方法。这个时候就由编译器来动态生成这个方法。 实例分析 了解了类型擦除机制之后,就会明白编译器承担了全部的类型检查工作。编译器禁止某些泛型的使用方式,正是为了确保类型的安全性。以上面提到的List和List为例来具体分析: public void inspect(List list) { for (Object obj : list) { System.out.println(obj); } list.add(1); //这个操作在当前方法的上下文是合法的。 } public void test() { List strs = new ArrayList(); inspect(strs); //编译错误 } 这段代码中,inspect方法接受List作为参数,当在test方法中试图传入List的时候,会出现编译错误。假设这样的做法是允许的,那么在inspect方法就可以通过list.add(1)来向集合中添加一个数字。这样在test方法看来,其声明为List的集合中却被添加了一个Integer类型的对象。这显然是违反类型安全的原则的,在某个时候肯定会抛出ClassCastException。因此,编译器禁止这样的行为。编译器会尽可能的检查可能存在的类型安全问题。对于确定是违反相关原则的地方,会给出编译错误。当编译器无法判断类型的使用是否正确的时候,会给出警告信息。 通配符与上下界 (可参考 Java泛型中extends和super的理解 和 Java泛型中K T V E ? object等的含义) 在使用泛型类的时候,既可以指定一个具体的类型,如List就声明了具体的类型是String;也可以用通配符?来表示未知类型,如List就声明了List中包含的元素类型是未知的。 通配符所代表的其实是一组类型,但具体的类型是未知的。List所声明的就是所有类型都是可以的。但是List并不等同于List。List实际上确定了List中包含的是Object及其子类,在使用的时候都可以通过Object来进行引用。而List则其中所包含的元素类型是不确定。其中可能包含的是String,也可能是 Integer。如果它包含了String的话,往里面添加Integer类型的元素就是错误的。正因为类型未知,就不能通过new ArrayList()的方法来创建一个新的ArrayList对象。因为编译器无法知道具体的类型是什么。但是对于 List中的元素确总是可以用Object来引用的,因为虽然类型未知,但肯定是Object及其子类。考虑下面的代码: public void wildcard(List list) { list.add(1);//编译错误 } 如上所示,试图对一个带通配符的泛型类进行操作的时候,总是会出现编译错误。其原因在于通配符所表示的类型是未知的。 因为对于List中的元素只能用Object来引用,在有些情况下不是很方便。在这些情况下,可以使用上下界来限制未知类型的范围。 如List即可。List是List的子类型,因此传递参数时不会发生错误。 开发自己的泛型类 泛型类与一般的Java类基本相同,只是在类和接口定义上多出来了用声明的类型参数。一个类可以有多个类型参数,如 MyClass。 每个类型参数在声明的时候可以指定上界。所声明的类型参数在Java类中可以像一般的类型一样作为方法的参数和返回值,或是作为域和局部变量的类型。但是由于类型擦除机制,类型参数并不能用来创建对象或是作为静态变量的类型。考虑下面的泛型类中的正确和错误的用法。 class ClassTest { private X x; private static Y y; //编译错误,不能用在静态变量中 public X getFirst() { //正确用法 return x; } public void wrong() { Z z = new Z(); //编译错误,不能创建对象 } } 总结 在使用泛型的时候可以遵循一些基本的原则,从而避免一些常见的问题。 在代码中避免泛型类和原始类型的混用(Effective Java中建议不要在代码中使用原始类型)。比如List 和List不应该共同使用。这样会产生一些编译器警告和潜在的运行时异常。当需要利用JDK 5之前开发的遗留代码,而不得不这么做时,也尽可能的隔离相关的代码。 在使用带通配符的泛型类的时候,需要明确通配符所代表的一组类型的概念。由于具体的类型是未知的,很多操作是不允许的。 泛型类最好不要同数组一块使用。你只能创建new List[10]这样的数组,无法创建new List [10]这样的。这限制了数组的使用能力,而且会带来很多费解的问题。因此,当需要类似数组的功能时候,使用集合类即可。 不要忽视编译器给出的警告信息。 参考资料: Java深度历险(五)——Java泛型