找到
556
篇与
技术
相关的结果
- 第 2 页
-
 正式宣战关系型数据库市场,华为宣布开源一款人工智能数据库 关系型数据库,是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据。目前市场上被广泛使用的关系型数据库主要有Oracle、DB2、MySQL、Microsoft SQL Server、Microsoft Access等。  目前使用比较广泛的关系型数据库主要有开源的MySQL和闭源的Oracle,在2019年5月15日,华为面向全球发布人工智能原生(AI-Native)数据库GaussDB,GaussDB是一款分布式数据库,取名Gauss是在致敬数学家高斯。 近日,有消息称,这一受到广泛关注的数据库被华为开源了。在华为的GaussBD的官网( https://support.huawei.com/enterprise/zh/cloud-computing/gaussdb-200-pid-21407429 )上,可以看到2019年8月2日新增了一份《Open Source Software Notice》:  这款数据库和我们之前了解的数据库有一个关键的区别:GaussDB 是业界首款 AI-Native 数据库,也是业界第一款支持 ARM 的企业级数据库。 全球首款AI-Native数据库 近些年来,以亚马逊等为代表的云计算企业纷纷投身数据库的研发,他们所打造的数据库也有了一个全新的理念:云原生(Cloud-Native)数据库。 不过,华为似乎要在这一基础上再进一步,华为刚刚发布的GaussDB数据库,也是全球首款人工智能原生(AI-Native)数据库。  作为全球首款AI-Native数据库,GaussDB首次将人工智能技术融入分布式数据库的全生命周期,实现自运维、自管理、自调优、故障自诊断和自愈。在交易、分析和混合负载场景下,基于最优化理论,首创基于深度强化学习的自调优算法,调优性能比业界提升60%以上; 从传统数据库的日暮西山,到开源数据库、Cloud-Native数据库、AI-Native数据库的快速崛起,在这场巨变中,华为发布GaussDB数据库,不止是要充当传统数据库的“掘墓人”,更是在新的智能时代成为释放数据价值的“新引擎”。 第一款支持 ARM 的企业级数据库 过去的数据库都是基于单一计算架构开发的,比如x86、Power、SPARC等。 GaussDB通过异构计算创新框架充分发挥X86、ARM、GPU、NPU多种算力优势,在权威标准测试集TPC-DS上,性能比业界提升50%,排名第一。 GaussDB不仅仅是支持ARM架构,还支持本地部署、私有云、公有云等多种场景。 分布式、AI-Native、支持异构,三大特性说明华为不是要做一款跟别人类似的产品,而是能应对未来挑战的产品。在布局未来这一块,华为走在了最前面。 总结 截止今年5月,华为GaussDB数据库和FusionInsight大数据解决方案已经应用于全球60个国家及地区,服务于1500多个客户,拥有500多家商业合作伙伴,并广泛应用于金融、运营商、政府、能源、医疗、制造、交通等多个行业。 据运维派报道,已经有多个典型的金融案例证明了GaussDB是经受得住考验的: 1、招商银行零售银行。使用GaussDB分布式OLTP数据库后,其综合交易流水平台、风险预警平台和重资产营销平台管理数据的容量提升10倍,AI的故障恢复速度提升30倍,相较其它产品30秒的RTO时间,GaussDB可以做到1秒以内。 2、某大型银行智慧银行项目。使用GaussDB分布式OLAP数据库后,其分析师平台、数据仓库和数据集市的数据分析效率大幅提升,相较友商产品TPC-DSBenchmark 2.68M的成绩,GaussDB能达到4.03M,提升达到50%。 3、中国民生银行。使用GaussDB分布式HTAP数据库后,一套架构能够支持流数据库、图数据库、空间数据、文本数据库和关系数据库五种类型数据的混合负载,在解决扩展性和性能瓶颈问题的同时,可有效分散风险,提升业务连续性。  GaussDB是一款划时代的产品。它引领着华为继单机数据、集群数据库和云分布式数据库后,率先进入数据库发展的第四个阶段——人工智能原生数据库时代。可以预见的是:用不了多久,数据库产业将全面进入AI数据库时代,华为无疑已经占得先机。 参考: https://www.shangyexinzhi.com/article/details/id-127376/ https://www.huawei.com/cn/press-events/news/2019/5/huawei-launches-ai-native-database 正面刚甲骨文?那不是华为GaussDB的格局
正式宣战关系型数据库市场,华为宣布开源一款人工智能数据库 关系型数据库,是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据。目前市场上被广泛使用的关系型数据库主要有Oracle、DB2、MySQL、Microsoft SQL Server、Microsoft Access等。  目前使用比较广泛的关系型数据库主要有开源的MySQL和闭源的Oracle,在2019年5月15日,华为面向全球发布人工智能原生(AI-Native)数据库GaussDB,GaussDB是一款分布式数据库,取名Gauss是在致敬数学家高斯。 近日,有消息称,这一受到广泛关注的数据库被华为开源了。在华为的GaussBD的官网( https://support.huawei.com/enterprise/zh/cloud-computing/gaussdb-200-pid-21407429 )上,可以看到2019年8月2日新增了一份《Open Source Software Notice》:  这款数据库和我们之前了解的数据库有一个关键的区别:GaussDB 是业界首款 AI-Native 数据库,也是业界第一款支持 ARM 的企业级数据库。 全球首款AI-Native数据库 近些年来,以亚马逊等为代表的云计算企业纷纷投身数据库的研发,他们所打造的数据库也有了一个全新的理念:云原生(Cloud-Native)数据库。 不过,华为似乎要在这一基础上再进一步,华为刚刚发布的GaussDB数据库,也是全球首款人工智能原生(AI-Native)数据库。  作为全球首款AI-Native数据库,GaussDB首次将人工智能技术融入分布式数据库的全生命周期,实现自运维、自管理、自调优、故障自诊断和自愈。在交易、分析和混合负载场景下,基于最优化理论,首创基于深度强化学习的自调优算法,调优性能比业界提升60%以上; 从传统数据库的日暮西山,到开源数据库、Cloud-Native数据库、AI-Native数据库的快速崛起,在这场巨变中,华为发布GaussDB数据库,不止是要充当传统数据库的“掘墓人”,更是在新的智能时代成为释放数据价值的“新引擎”。 第一款支持 ARM 的企业级数据库 过去的数据库都是基于单一计算架构开发的,比如x86、Power、SPARC等。 GaussDB通过异构计算创新框架充分发挥X86、ARM、GPU、NPU多种算力优势,在权威标准测试集TPC-DS上,性能比业界提升50%,排名第一。 GaussDB不仅仅是支持ARM架构,还支持本地部署、私有云、公有云等多种场景。 分布式、AI-Native、支持异构,三大特性说明华为不是要做一款跟别人类似的产品,而是能应对未来挑战的产品。在布局未来这一块,华为走在了最前面。 总结 截止今年5月,华为GaussDB数据库和FusionInsight大数据解决方案已经应用于全球60个国家及地区,服务于1500多个客户,拥有500多家商业合作伙伴,并广泛应用于金融、运营商、政府、能源、医疗、制造、交通等多个行业。 据运维派报道,已经有多个典型的金融案例证明了GaussDB是经受得住考验的: 1、招商银行零售银行。使用GaussDB分布式OLTP数据库后,其综合交易流水平台、风险预警平台和重资产营销平台管理数据的容量提升10倍,AI的故障恢复速度提升30倍,相较其它产品30秒的RTO时间,GaussDB可以做到1秒以内。 2、某大型银行智慧银行项目。使用GaussDB分布式OLAP数据库后,其分析师平台、数据仓库和数据集市的数据分析效率大幅提升,相较友商产品TPC-DSBenchmark 2.68M的成绩,GaussDB能达到4.03M,提升达到50%。 3、中国民生银行。使用GaussDB分布式HTAP数据库后,一套架构能够支持流数据库、图数据库、空间数据、文本数据库和关系数据库五种类型数据的混合负载,在解决扩展性和性能瓶颈问题的同时,可有效分散风险,提升业务连续性。  GaussDB是一款划时代的产品。它引领着华为继单机数据、集群数据库和云分布式数据库后,率先进入数据库发展的第四个阶段——人工智能原生数据库时代。可以预见的是:用不了多久,数据库产业将全面进入AI数据库时代,华为无疑已经占得先机。 参考: https://www.shangyexinzhi.com/article/details/id-127376/ https://www.huawei.com/cn/press-events/news/2019/5/huawei-launches-ai-native-database 正面刚甲骨文?那不是华为GaussDB的格局
-
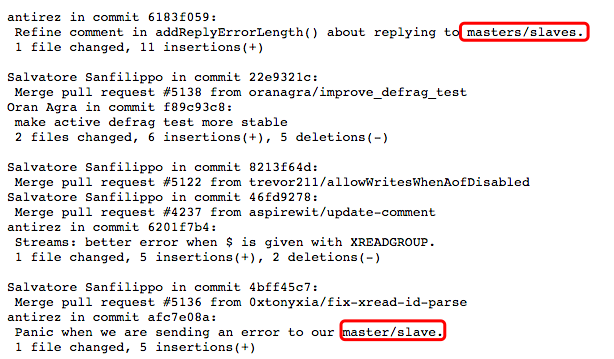
政治不正确?Redis/Python等的master-slave要改名了。 Master/Slave模式,是分布式系统中一个比较常用的计算结构。这个词最开始来源于MySql数据库,主要表示MySQL数据库自身提供的主从复制功能,通过master-slave,可以方便的实现数据的多处自动备份,实现数据库的拓展。多个数据备份不仅可以加强数据的安全性,通过实现读写分离还能进一步提升数据库的负载性能。 这个名词由两个单词组合而成:Master和Slave。 Master:主人、雇主。 Slave:奴,奴隶。 争议焦点 组合成的词一般写作Master/Slave 或者 master-slave,一般表示主从结构。这个词本身是一个没有任何感情色彩的中性词语。 master-slave目前在软件行业内被广泛使用,如Mysql、Redis、Python、mongodb、ActiveMQ、PostgreSQL、Ruby、Jenkins 等都有类似的描述。 但是,随着人们开始越来越重视人权、歧视等问题,很多开发者认为这一描述具有侵犯性。所以,出现了很多声音呼吁修改这一描述。他们的主要诉求是不要使用master-slave这一词汇,而是使用其他词汇代替。 这件事儿之所以最近这么受重视,是因为比较关键的技术被要求修改,那就是Redis和Python。 Redis被迫修改 2018年9月7日,Redis 5.0 RC5 发布了,该版本中仍然使用master-slave来表示主从模式,这引起了很多开发者的抗议。 值得注意的是,以上提交记录的第一个提交者antirez就是Redis的作者。他的真名叫Salvatore Sanfilippo,antirez是他的网名。 对于大部分开发者抗议使用master-slave这一描述,antirez 表示这已经不是开发者第一次提这种要求了,他很抱歉 master-slave 这个描述让许多人感到失望,但他不认为这个特定于上下文环境的术语具有侵犯性。 但是,虽然这么说,但是antirez还是在推特上发起了一个投票,结果显示,超过半数的人希望修改这一描述。 antirez 还表示,这个看似简单的修改实际上要付出昂贵的代价,并产生兼容性问题。例如: 不能在应用现有的 PR 现在有像 INFO 和 ROLE 这样的命令 —— 使用包含 slave 术语的协议进行回复 术语 slave 中的源代码包含 1500 个事件 拥有私人项目并根据需要进行代码合并的人会遇到很多问题 可以看到,冒然进行变动会产生很多问题。而且,现在发布的 Redis 5 候选版本是向后兼容的首个稳定版本。 最后 antirez 决定,在不影响项目进度的情况下做了些妥协,表达了希望能折中解决问题的建议。 短期变化 将 master-slave 架构的描述改为 master-replica 为 SLAVEOF 提供别名 REPLICAOF,所以仍然可以使用 SLAVEOF,但多了一个选项 保持继续使用 slave 来对 INFO 和 ROLE 进行回应,现在目前看来,这仍然是一个重大的破坏性变更 长期变化 编写一个 INFO 的替代品 在内部替换很多东西,因为技术原因,如果作了改动,许多 PR 也会无法应用,所以必须在某些地方进行大变动 Python可能也会修改 同样是2018年9月7日,在 Red Hat 工作的 Python 开发者 Victor Stinner 公开提交了 4 个 PR,希望能将 Python 文档和代码中出现的 “master” 和 “slave” 修改为像 “parent” 和 “worker” 这样的术语,以及对其他类似的术语也进行修改。 Victor Stinner 在他的 bug report 中解释说,出于多元化的考虑,尽量避免出现与奴隶制相关的术语反而可能会更好,像 ‘master’ 和 ‘slave’ 这种。他还指出之前就已有关于这个问题的投诉,但都是私下提出的 —— 以避免引起激烈的争论。 对于这个问题,Python的创始人,已经宣布退出Python核心开发组决策层的Guido van Rossum被请回参与了这一事件的讨论及仲裁。最终他做出了重要的决定: 计划在Python 3.8中,将slave改为worker、helper、另外将master process改为parent process。 前尘与未来 事实上,在技术圈子里,这种关于政治正确的事屡见不鲜。其实,这也不是关于master-slave的第一次讨论,Redis也并不是第一个屈服的。 早在2014 年,Drupal 项目就用 primary 和 replica 替换了 master 和 slave;Django 项目则用 leader 和 follower 替换之;CouchDB 项目也做了类似语言上的净化。如今,Redis和Python也将在后续版本中国年逐渐淡化master-slave这一说法。 随着Redis和Python的妥协,相信未来会有更多的软件也会做一些相应的修改。那么问题来了,下一个会是谁呢? 继master-slave之后,会不会有另外的词汇被质疑呢?下一个词又会是什么呢? 最后,还要说的就是,起名,真的很重要!
-
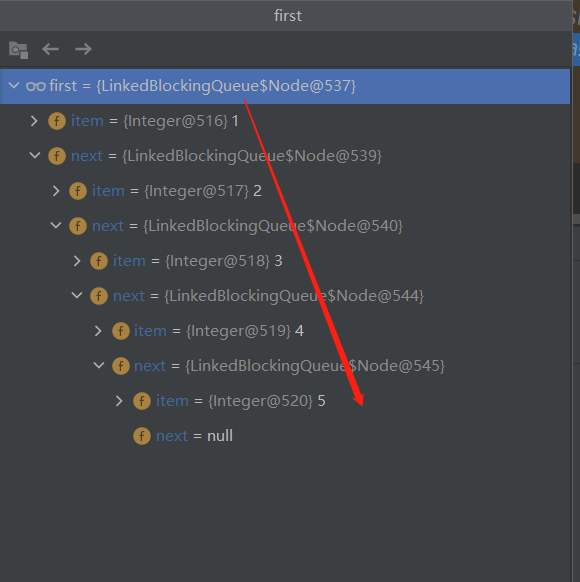
面试官问我平时怎么看源码的,我把这篇文章甩给他了。 面试官问我平时怎么看源码的,我把这篇文章甩给他了。 本文来自作者投稿,原作者:WwpwW 1.1,为什么要分析源码? 分析源码可以培养一下自己独立思考问题的能力(愿意读源码找问题的能力),最重要的是我们不用再买纸质书去学习数据结构了,数据结构的应用都在源码里面了,正如那句被人熟知的”营养都在汤里面”一样,当我们看过一遍一遍数据结构的理论知识后还是想不起它在哪里用到时,可能看一看源码加上自己的一点思考时就知道它的使用场景了,解答完毕。 1.2,分析源码的好处是? 其实,对于工作一段时间的小伙伴来说,我们都是面向业务开发,就是被人饭后谈资的增删改查程序员/程序猿,当然了,有的人说起来这样的话,”api调包侠”就有点过分了,其实对于我个人来说,我是受不了这样的话语的,因为增删改查是常用的操作,即满足了”二八原则”,其实,程序员/程序猿都是工作中不可或缺的一部分,也是企业开发应用中重要的一环,分析源码可能就会带来显而易见的内功提升,其次就是分析源码的过程中就是在向优秀的人学习的一种体现,毕竟源码里面隐藏了大师多年的心得和思想。 1.3,如何分析源码? 在整个文章的阅读过程中,想必你已经学会了如何分析源码了,从哪入手,这也是一种潜移默化的过程 二, 方法分析 2.1,构造函数 public LinkedBlockingQueue() { //创建容量为整形最大值 this(Integer.MAX_VALUE); } public LinkedBlockingQueue(int capacity) { //若capacity小于0,则直接抛出参数不合法的异常 if (capacity = capacity) return false; //创建一个临时变量l,将最后一个节点的引用赋值给l Node l = last; //将最后一个节点的引用赋值给新节点node的前一个引用(链表的特点) node.prev = l; //将新节点node赋值给最后一个节点(因为元素如队列是放在队列的末尾的,队列的特点->先进先出) last = node; //为什么这里要判断first是否为null呢?因为添加时不知道队列里是否已经存在元素,若first为null,说明队列里没有元素 if (first == null) //此时的node就是第一个结点,赋值即可 first = node; else //将新节点node挂在原有结点的下一个,即l.next=node l.next = node; //队列元素个数进行加一 ++count; //发送一个信号,队列不满的信号 notEmpty.signal(); //默认将元素e添加到队列里面了~,即返回true return true; } 2.3,size()方法 public int size() { //直接返回队列里表示元素个数的成员变量count即可 return count.get(); } 2.4,peek()方法 public E peek() { //若队列元素个数为0,说明队列里还未有元素,直接返回null if (count.get() == 0) return null; //获取锁 final ReentrantLock takeLock = this.takeLock; //进行加锁操作 takeLock.lock(); try { //获取队列的第一个结点引用first Node first = head.next; //若队列的第一个节点引用为null,则直接返回null即可 if (first == null) return null; else //获取第一个节点引用first的元素item返回 return first.item; } finally { //进行释放锁,记得释放锁要放在finally语句块里,确保锁可以得到释放 takeLock.unlock(); } } 2.5,contains()方法 public boolean contains(Object o) { //引入队列里不允许放入null,所以若元素o为null,则直接返回false,相当于进行了前置校验操作 if (o == null) return false; //第二步 fullyLock(); try { //循环遍历队列的每个节点node的元素item是否与元素o相等,若存在相等元素,则包含,返回true即可 for (Node p = head.next; p != null; p = p.next) if (o.equals(p.item)) return true; return false; } finally { //第四步,第三次说明了,释放锁要放在finally语句块里面,确保锁可以得到正确的释放 fullyUnlock(); } } /** * Locks to prevent both puts and takes. */ //第二步,上面的注释说明,进行加锁操作,禁止进行添加元素到队列,禁止进行从队列里取元素,下面就慢慢分析take()方法了 void fullyLock() { putLock.lock(); takeLock.lock(); } //第四步,因为加锁和释放锁是成对的,所以最后一定要记得释放锁哈~,即加了什么锁,要对应的解锁 /** * Unlocks to allow both puts and takes. */ void fullyUnlock() { takeLock.unlock(); putLock.unlock(); } 2.6,put()方法 public void put(E e) throws InterruptedException { //这个队列是不允许添加空元素的,先来个前置校验,元素为null,则抛出NPE异常 if (e == null) throw new NullPointerException(); // Note: convention in all put/take/etc is to preset local var // holding count negative to indicate failure unless set. int c = -1; //构造一个节点node,元素为e Node node = new Node(e); //获取putLock这把锁引用 final ReentrantLock putLock = this.putLock; final AtomicInteger count = this.count; putLock.lockInterruptibly(); try { //当队列元素个数等于队列容量capacity时,进行等待,这里存在一个阻塞操作 while (count.get() == capacity) { notFull.await(); } //第二步操作,入队列 enqueue(node); //元素个数增加1,这里使用的是cas机制 c = count.getAndIncrement(); if (c + 1 < capacity) //进行信号的通知,和notify一样 notFull.signal(); } finally { //释放锁操作 putLock.unlock(); } if (c == 0) signalNotEmpty(); } //第二步,入队列操作(队列的特点是先进先出) private void enqueue(Node node) { //将新元素结点node挂在原有队列最后一个元素的后面,然后将最后一个节点的引用赋值给last last = last.next = node; } 2.7,take()方法 public E take() throws InterruptedException { E x; int c = -1; final AtomicInteger count = this.count; //获取takeLock锁引用 final ReentrantLock takeLock = this.takeLock; //这把锁是可以中断的 takeLock.lockInterruptibly(); try { //若队列元素个数为0,说明队列里没元素了,此时需要进行发送一个等待的通知 while (count.get() == 0) { notEmpty.await(); } //进行从队列里进行取元素操作,见下面的第二步操作 x = dequeue(); //队列元素个数进行减一操作 c = count.getAndDecrement(); if (c > 1) notEmpty.signal(); } finally { // 释放锁 takeLock.unlock(); } if (c == capacity) signalNotFull(); return x; } //第二步操作 private E dequeue() { //下面的操作就是队首元素出来了,队列的后面元素要前移,如果这一步不是很好理解的话,可以按照下面的方式进行debug看下 //在分析这块时,自己也有所成长,因为debug是可以看到元素在数据流中如何处理的 Node h = head; Node first = h.next; h.next = h; // help GC head = first; //获取队首元素x E x = first.item; //触发gc机制进行垃圾回收,什么是垃圾对象呢,就是不可达对象,不了解的可以看下jvm对应的机制 first.item = null; //返回队列的队首元素 return x; } 2.8,remove()方法 public boolean remove(Object o) { //这个队列里不允许添加元素为null的元素,所以这里在删除的时候做了一下前置校验 if (o == null) return false; //第二步,禁止入队列和出队列操作,和上文的contains()方法采取的策略一致 fullyLock(); try { //循环遍历队列的每个元素,进行比较,这里是不是和你写业务逻辑方法一样,啧啧,有点意思吧 //这里你就明白为什么要看源码了,以及看源码你能得到什么 for (Node trail = head, p = trail.next; p != null; trail = p, p = p.next) { //此时找到待删除的元素o if (o.equals(p.item)) { //进行第三步操作 unlink(p, trail); return true; } } return false; } finally { fullyUnlock(); } } //第二步,禁止入队列,出队列操作 void fullyLock() { putLock.lock(); takeLock.lock(); } //第三步 void unlink(Node p, Node trail) { //触发gc机制,将垃圾对象进行回收 p.item = null; //将待删除元素的下一个节点【挂载】待删除元素的前一个元素的next后面 trail.next = p.next; //判断待删除的元素是否是队列的最后一个元素,如果是,则trail赋值给last,这里你可以想象一下链表的删除操作 if (last == p) last = trail; //队列的元素个数减一 if (count.getAndDecrement() == capacity) notFull.signal(); } 2.9,clear()方法 /** * Atomically removes all of the elements from this queue. * The queue will be empty after this call returns. */ public void clear() { //方法上的注释已经说明了clear()方法的作用是干什么的了,很清晰 //在clear()操作时,不允许进行put/take操作,进行了加锁 fullyLock(); try { //循环遍历队列的每一个元素,将其节点node对应的元素item置为null,触发gc for (Node p, h = head; (p = h.next) != null; h = p) { h.next = h; p.item = null; } //队首队尾相同表明队列为空了 head = last; //将队列的容量capacity置为0 if (count.getAndSet(0) == capacity) notFull.signal(); } finally { //记得在这里释放锁 fullyUnlock(); } } 2.10, toArray()方法 public Object[] toArray() { //禁止put/take操作,所以进行加锁,看下面的第二步含义 fullyLock(); try { //获取队列元素个数size int size = count.get(); //创建大小为size的object数组,之所以为Object类型是因为Object对象的范围最大,什么类型都可以装下 Object[] a = new Object[size]; int k = 0; //循环遍历队列的每一个元素,将其装入到数组object里面 for (Node p = head.next; p != null; p = p.next) a[k++] = p.item; return a; } finally { //最后进行释放对应的锁,其实这里你也可以学到很多东西的,比如说加锁,解锁操作,为啥要放到finally语句块呢等等等 //都会潜移默化的指导你编码的过程 fullyUnlock(); } } //第二步,注释已经很好的说明了这个方法的含义,就是阻止put和take操作的,所以进行获取对应的锁进行加锁操作 /** * Locks to prevent both puts and takes. */ void fullyLock() { putLock.lock(); takeLock.lock(); } 2.11,方法总结 这里自己没有对队列的poll()方法,offer()方法进行分析,是因为它和take(),add()方法的分析过程都太一样了,至于一点点差别,你可以去自己看下源码哈,这里由于篇幅的问题就不过多介绍了,其实整个方法的分析就是基于链表和数组的操作。不过这里没有在方法的分析过程中去写时间复杂度,不过,你看过vector源码之后就知道如何分析了。 三,总结一下 3.1,思考一下 文章的开头抛出了下面的3个问题 1.1,为什么要分析源码? 那我这里在问下,你分析完这个集合源码,学习到了什么?是不是有点启发? 1.2,分析源码的好处是? 在分析的过程中,你学会了如何更加去编码,或许你没有意识到,但这是潜移默化的过程,相信你学习到了 1.3,如何分析源码? 在整个文章的阅读过程中,想必你已经学会了如何分析源码了,从哪入手,这也是一种潜移默化的过程
-
我要彻底给你讲清楚,Java就是值传递,不接受争辩的那种! 关于Java中方法间的参数传递到底是怎样的、为什么很多人说Java只有值传递等问题,一直困惑着很多人,甚至我在面试的时候问过很多有丰富经验的开发者,他们也很难解释的很清楚。 我很久也写过一篇文章,我当时认为我把这件事说清楚了,但是,最近在整理这部分知识点的时候,我发现我当时理解的还不够透彻,于是我想着通过Google看看其他人怎么理解的,但是遗憾的是没有找到很好的资料可以说的很清楚。 于是,我决定尝试着把这个话题总结一下,重新理解一下这个问题。 辟谣时间 关于这个问题,在StackOverflow上也引发过广泛的讨论,看来很多程序员对于这个问题的理解都不尽相同,甚至很多人理解的是错误的。还有的人可能知道Java中的参数传递是值传递,但是说不出来为什么。 在开始深入讲解之前,有必要纠正一下大家以前的那些错误看法了。如果你有以下想法,那么你有必要好好阅读本文。 错误理解一:值传递和引用传递,区分的条件是传递的内容,如果是个值,就是值传递。如果是个引用,就是引用传递。 错误理解二:Java是引用传递。 错误理解三:传递的参数如果是普通类型,那就是值传递,如果是对象,那就是引用传递。 实参与形参 我们都知道,在Java中定义方法的时候是可以定义参数的。比如Java中的main方法,public static void main(String[] args),这里面的args就是参数。参数在程序语言中分为形式参数和实际参数。 形式参数:是在定义函数名和函数体的时候使用的参数,目的是用来接收调用该函数时传入的参数。 实际参数:在调用有参函数时,主调函数和被调函数之间有数据传递关系。在主调函数中调用一个函数时,函数名后面括号中的参数称为“实际参数”。 简单举个例子: public static void main(String[] args) { ParamTest pt = new ParamTest(); pt.sout("Hollis");//实际参数为 Hollis } public void sout(String name) { //形式参数为 name System.out.println(name); } 实际参数是调用有参方法的时候真正传递的内容,而形式参数是用于接收实参内容的参数。 求值策略 我们说当进行方法调用的时候,需要把实际参数传递给形式参数,那么传递的过程中到底传递的是什么东西呢? 这其实是程序设计中求值策略(Evaluation strategies)的概念。 在计算机科学中,求值策略是确定编程语言中表达式的求值的一组(通常确定性的)规则。求值策略定义何时和以何种顺序求值给函数的实际参数、什么时候把它们代换入函数、和代换以何种形式发生。 求值策略分为两大基本类,基于如何处理给函数的实际参数,分位严格的和非严格的。 严格求值 在“严格求值”中,函数调用过程中,给函数的实际参数总是在应用这个函数之前求值。多数现存编程语言对函数都使用严格求值。所以,我们本文只关注严格求值。 在严格求值中有几个关键的求值策略是我们比较关心的,那就是传值调用(Call by value)、传引用调用(Call by reference)以及传共享对象调用(Call by sharing)。 传值调用(值传递) 在传值调用中,实际参数先被求值,然后其值通过复制,被传递给被调函数的形式参数。因为形式参数拿到的只是一个”局部拷贝”,所以如果在被调函数中改变了形式参数的值,并不会改变实际参数的值。 传引用调用(应用传递) 在传引用调用中,传递给函数的是它的实际参数的隐式引用而不是实参的拷贝。因为传递的是引用,所以,如果在被调函数中改变了形式参数的值,改变对于调用者来说是可见的。 传共享对象调用(共享对象传递) 传共享对象调用中,先获取到实际参数的地址,然后将其复制,并把该地址的拷贝传递给被调函数的形式参数。因为参数的地址都指向同一个对象,所以我们称也之为”传共享对象”,所以,如果在被调函数中改变了形式参数的值,调用者是可以看到这种变化的。 不知道大家有没有发现,其实传共享对象调用和传值调用的过程几乎是一样的,都是进行”求值”、”拷贝”、”传递”。你品,你细品。  但是,传共享对象调用和内传引用调用的结果又是一样的,都是在被调函数中如果改变参数的内容,那么这种改变也会对调用者有影响。你再品,你再细品。 那么,共享对象传递和值传递以及引用传递之间到底有很么关系呢? 对于这个问题,我们应该关注过程,而不是结果,因为传共享对象调用的过程和传值调用的过程是一样的,而且都有一步关键的操作,那就是”复制”,所以,通常我们认为传共享对象调用是传值调用的特例 我们先把传共享对象调用放在一边,我们再来回顾下传值调用和传引用调用的主要区别: 传值调用是指在调用函数时将实际参数复制一份传递到函数中,传引用调用是指在调用函数时将实际参数的引用直接传递到函数中。 所以,两者的最主要区别就是是直接传递的,还是传递的是一个副本。 这里我们来举一个形象的例子。再来深入理解一下传值调用和传引用调用: 你有一把钥匙,当你的朋友想要去你家的时候,如果你直接把你的钥匙给他了,这就是引用传递。 这种情况下,如果他对这把钥匙做了什么事情,比如他在钥匙上刻下了自己名字,那么这把钥匙还给你的时候,你自己的钥匙上也会多出他刻的名字。 你有一把钥匙,当你的朋友想要去你家的时候,你复刻了一把新钥匙给他,自己的还在自己手里,这就是值传递。 这种情况下,他对这把钥匙做什么都不会影响你手里的这把钥匙。 Java的求值策略 前面我们介绍过了传值调用、传引用调用以及传值调用的特例传共享对象调用,那么,Java中是采用的哪种求值策略呢? 很多人说Java中的基本数据类型是值传递的,这个基本没有什么可以讨论的,普遍都是这样认为的。 但是,有很多人却误认为Java中的对象传递是引用传递。之所以会有这个误区,主要是因为Java中的变量和对象之间是有引用关系的。Java语言中是通过对象的引用来操纵对象的。所以,很多人会认为对象的传递是引用的传递。 而且很多人还可以举出以下的代码示例: public static void main(String[] args) { Test pt = new Test(); User hollis = new User(); hollis.setName("Hollis"); hollis.setGender("Male"); pt.pass(hollis); System.out.println("print in main , user is " + hollis); } public void pass(User user) { user.setName("hollischuang"); System.out.println("print in pass , user is " + user); } 输出结果: print in pass , user is User{name='hollischuang', gender='Male'} print in main , user is User{name='hollischuang', gender='Male'} 可以看到,对象类型在被传递到pass方法后,在方法内改变了其内容,最终调用方main方法中的对象也变了。 所以,很多人说,这和引用传递的现象是一样的,就是在方法内改变参数的值,会影响到调用方。 但是,其实这是走进了一个误区。 Java中的对象传递 很多人通过代码示例的现象说明Java对象是引用传递,那么我们就从现象入手,先来反驳下这个观点。 我们前面说过,无论是值传递,还是引用传递,只不过是求值策略的一种,那求值策略还有很多,比如前面提到的共享对象传递的现象和引用传递也是一样的。那凭什么就说Java中的参数传递就一定是引用传递而不是共享对象传递呢? 那么,Java中的对象传递,到底是哪种形式呢?其实,还真的就是共享对象传递。 其实在 《The Java™ Tutorials》中,是有关于这部分内容的说明的。首先是关于基本类型描述如下: Primitive arguments, such as an int or a double, are passed into methods by value. This means that any changes to the values of the parameters exist only within the scope of the method. When the method returns, the parameters are gone and any changes to them are lost. 即,原始参数通过值传递给方法。这意味着对参数值的任何更改都只存在于方法的范围内。当方法返回时,参数将消失,对它们的任何更改都将丢失。 关于对象传递的描述如下: Reference data type parameters, such as objects, are also passed into methods by value. This means that when the method returns, the passed-in reference still references the same object as before. However, the values of the object’s fields can be changed in the method, if they have the proper access level. 也就是说,引用数据类型参数(如对象)也按值传递给方法。这意味着,当方法返回时,传入的引用仍然引用与以前相同的对象。但是,如果对象字段具有适当的访问级别,则可以在方法中更改这些字段的值。 这一点官方文档已经很明确的指出了,Java就是值传递,只不过是把对象的引用当做值传递给方法。你细品,这不就是共享对象传递么? 其实Java中使用的求值策略就是传共享对象调用,也就是说,Java会将对象的地址的拷贝传递给被调函数的形式参数。只不过”传共享对象调用”这个词并不常用,所以Java社区的人通常说”Java是传值调用”,这么说也没错,因为传共享对象调用其实是传值调用的一个特例。 值传递和共享对象传递的现象冲突吗? 看到这里很多人可能会有一个疑问,既然共享对象传递是值传递的一个特例,那么为什么他们的现象是完全不同的呢? 难道值传递过程中,如果在被调方法中改变了值,也有可能会对调用者有影响吗?那到底什么时候会影响什么时候不会影响呢? 其实是不冲突的,之所以会有这种疑惑,是因为大家对于到底是什么是”改变值”有误解。 我们先回到上面的例子中来,看一下调用过程中实际上发生了什么? 在参数传递的过程中,实际参数的地址0X1213456被拷贝给了形参。这个过程其实就是值传递,只不过传递的值得内容是对象的应用。 那为什么我们改了user中的属性的值,却对原来的user产生了影响呢? 其实,这个过程就好像是:你复制了一把你家里的钥匙给到你的朋友,他拿到钥匙以后,并没有在这把钥匙上做任何改动,而是通过钥匙打开了你家里的房门,进到屋里,把你家的电视给砸了。 这个过程,对你手里的钥匙来说,是没有影响的,但是你的钥匙对应的房子里面的内容却是被人改动了。 也就是说,Java对象的传递,是通过复制的方式把引用关系传递了,如果我们没有改引用关系,而是找到引用的地址,把里面的内容改了,是会对调用方有影响的,因为大家指向的是同一个共享对象。 那么,如果我们改动一下pass方法的内容: public void pass(User user) { user = new User(); user.setName("hollischuang"); System.out.println("print in pass , user is " + user); } 上面的代码中,我们在pass方法中,重新new了一个user对象,并改变了他的值,输出结果如下: print in pass , user is User{name='hollischuang', gender='Male'} print in main , user is User{name='Hollis', gender='Male'} 再看一下整个过程中发生了什么: 这个过程,就好像你复制了一把钥匙给到你的朋友,你的朋友拿到你给他的钥匙之后,找个锁匠把他修改了一下,他手里的那把钥匙变成了开他家锁的钥匙。这时候,他打开自己家,就算是把房子点了,对你手里的钥匙,和你家的房子来说都是没有任何影响的。 所以,Java中的对象传递,如果是修改引用,是不会对原来的对象有任何影响的,但是如果直接修改共享对象的属性的值,是会对原来的对象有影响的。 总结 我们知道,编程语言中需要进行方法间的参数传递,这个传递的策略叫做求值策略。 在程序设计中,求值策略有很多种,比较常见的就是值传递和引用传递。还有一种值传递的特例——共享对象传递。 值传递和引用传递最大的区别是传递的过程中有没有复制出一个副本来,如果是传递副本,那就是值传递,否则就是引用传递。 在Java中,其实是通过值传递实现的参数传递,只不过对于Java对象的传递,传递的内容是对象的引用。 我们可以总结说,Java中的求值策略是共享对象传递,这是完全正确的。 但是,为了让大家都能理解你说的,我们说Java中只有值传递,只不过传递的内容是对象的引用。这也是没毛病的。 但是,绝对不能认为Java中有引用传递。 OK,以上就是本文的全部内容,不知道本文是否帮助你解开了你心中一直以来的疑惑。欢迎留言说一下你的想法。 参考资料 The Java™ Tutorials Evaluation strategy Is Java “pass-by-reference” or “pass-by-value”? Passing by Value vs. by Reference Visual Explanation
-
SpringBatch配置多线程step SpringBatch批处理框架默认使用单线程完成任务的执行,但是他提供了对线程池的支持。使用tasklet的task-executor属性可以很容易的将普通的step转成多线程的step。 task-executor:任务执行处理器,定义后采用多线程执行任务,需要考虑线程安全问题。 throttle-limit:最大使用线程池数目。 如果我们希望示例中的 billingStep 以并发方式执行,且并发任务数为 5,那么只需要做如下配置即可,见清单: Spring Core 为我们提供了多种执行器实现(包括多种异步执行器),我们可以根据实际情况灵活选择使用。 类名 描述 是否异步 SyncTaskExecutor 简单同步执行器 否 ThrottledTaskExecutor 该执行器为其他任意执行器的装饰类,并完成提供执行次数限制的功能 视被装饰的执行器而定 SimpleAsyncTaskExecutor 简单异步执行器,提供了一种最基本的异步执行实现 是 WorkManagerTaskExecutor 该类作为通过 JCA 规范进行任务执行的实现,其包含 JBossWorkManagerTaskExecutor 和 GlassFishWorkManagerTaskExecutor 两个子类 是 ThreadPoolTaskExecutor 线程池任务执行器 是 在多线程step中为了保证代码处理的正确性,要求所有在多线程step中处理的对象和操作必须都是线程安全的。但是SpringBatch框架提供的大部分的ItemReader、ItemWriter都不是线程安全的。所以需要自己保证多线程处理时候的线程安全。 那么,如何保证step的线程安全呢? 1.对reader的read方法使用synchronized关键字。 这种方式并不支持重启操作。当执行失败的时候并没有保存当前的状态数据导致无法知道哪些数据已经读取,哪些数据未读取。 多线程step提供了多个线程执行一个step的能力,但这种场景在实际业务中是用的并不是非常多。更多的是job中不同的step没有先后顺序,可以在执行期间并行的执行。SpringBatch提供了并行step的能力。可以通过split元素来定义并行的作业流。 参考资料:使用 Spring Batch 构建企业级批处理应用: 第 2 部分