找到
16
篇与
分布式
相关的结果
- 第 2 页
-
 Zookeeper介绍(三)——Zookeeper的安装 在Zookeeper概述中简单介绍了Zookeepr,工欲善其事,必先利其器。那么本文就介绍如何安装Zookeeper。 Zookeeper有三种安装方式:单机模式、集群模式、伪集群模式。 单机模式 单机模式表示只运行在一台服务器上,适合测试环境; 安装步骤如下: 一、下载ZooKeeper 二、解压 三、在conf目录下创建一个配置文件zoo.cfg tickTime=2000 dataDir=/Users/zdandljb/zookeeper/data dataLogDir=/Users/zdandljb/zookeeper/dataLog clientPort=2181 这里涉及到的参数会在后文统一介绍 四、启动ZooKeeper的Server sh bin/zkServer.sh start, 如果想要关闭,输入:zkServer.sh stop 五、检查是否启动成功 启动后使用命令echo ruok | nc localhost 2181检查 Zookeeper 是否已经在服务。如果正常启动将输出imok 集群模式 Zookeeper 不仅可以单机提供服务,同时也支持多机组成集群来提供服务。 安装步骤和单机模式类似,只是配置不太一样。这里以三台机器为例 一、分别在不同的机器上下载并解压Zookeeper 二、创建myid文件 在每台机器上都创建一个myid文件。文件的内容只有一个数字。 server1机器的内容为:1 server2机器的内容为:2 server3机器的内容为:3 三、在conf目录下创建一个配置文件zoo.cfg tickTime=2000 dataDir=/Users/zdandljb/zookeeper/data dataLogDir=/Users/zdandljb/zookeeper/dataLog clientPort=2181 initLimit=5 syncLimit=2 server.1=server1:2888:3888 server.2=server2:2888:3888 server.3=server3:2888:3888 伪集群模式 实际上 Zookeeper 还支持另外一种伪集群的方式,也就是可以在一台物理机上运行多个 Zookeeper 实例 一、安装Zookeeper 建了3个文件夹,server1 server2 server3,然后每个文件夹里面解压一个zookeeper的下载包 二、创建myid文件 进入data目录,创建一个myid的文件,里面写入一个数字,server1,就写一个1,server2对应myid文件就写入2,server3对应myid文件就写个3 三、在conf目录下创建一个配置文件zoo.cfg tickTime=2000 dataDir=/Users/zdandljb/zookeeper/data dataLogDir=xxx/zookeeper/server1/ clientPort=2181 initLimit=5 syncLimit=2 server.1=server1:2888:3888 server.2=server2:2889:3889 server.3=server3:2890:3890 为了防止端口冲突,要配置不同的端口号。 常用参数 dataDir:用于存放内存数据库快照的文件夹,同时用于集群的myid文件也存在这个文件夹里。 dataLogDir:用于单独设置transaction log的目录,transaction log分离可以避免和普通log还有快照的竞争。 tickTime:心跳时间,为了确保client-server连接存在的,以毫秒为单位,最小超时时间为两个心跳时间。 clientPort:客户端监听端口。 initLimit:初始化连接时最长能忍受多少个心跳时间间隔数 syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度 server.x=[hostname]:nnnnn[:nnnnn] 配置集群里面的主机信息,其中: ①server.x:server.x的x要写在myid文件中,决定当前机器的id, ②第一个port用于连接leader, ③第二个用于leader选举。 ④如果electionAlg为0,则不需要第二个port。 ⑤hostname也可以填ip。 伪集群模式安转时,后面连着的2个端口3个server都不要一样,否则端口冲突。 electionAlg 用于选举的实现的参数: 1:LeaderElection 2:AuthFastLeaderElection 3:FastLeaderElection zookeeper默认使用FastLeaderElection进行Leader选举
Zookeeper介绍(三)——Zookeeper的安装 在Zookeeper概述中简单介绍了Zookeepr,工欲善其事,必先利其器。那么本文就介绍如何安装Zookeeper。 Zookeeper有三种安装方式:单机模式、集群模式、伪集群模式。 单机模式 单机模式表示只运行在一台服务器上,适合测试环境; 安装步骤如下: 一、下载ZooKeeper 二、解压 三、在conf目录下创建一个配置文件zoo.cfg tickTime=2000 dataDir=/Users/zdandljb/zookeeper/data dataLogDir=/Users/zdandljb/zookeeper/dataLog clientPort=2181 这里涉及到的参数会在后文统一介绍 四、启动ZooKeeper的Server sh bin/zkServer.sh start, 如果想要关闭,输入:zkServer.sh stop 五、检查是否启动成功 启动后使用命令echo ruok | nc localhost 2181检查 Zookeeper 是否已经在服务。如果正常启动将输出imok 集群模式 Zookeeper 不仅可以单机提供服务,同时也支持多机组成集群来提供服务。 安装步骤和单机模式类似,只是配置不太一样。这里以三台机器为例 一、分别在不同的机器上下载并解压Zookeeper 二、创建myid文件 在每台机器上都创建一个myid文件。文件的内容只有一个数字。 server1机器的内容为:1 server2机器的内容为:2 server3机器的内容为:3 三、在conf目录下创建一个配置文件zoo.cfg tickTime=2000 dataDir=/Users/zdandljb/zookeeper/data dataLogDir=/Users/zdandljb/zookeeper/dataLog clientPort=2181 initLimit=5 syncLimit=2 server.1=server1:2888:3888 server.2=server2:2888:3888 server.3=server3:2888:3888 伪集群模式 实际上 Zookeeper 还支持另外一种伪集群的方式,也就是可以在一台物理机上运行多个 Zookeeper 实例 一、安装Zookeeper 建了3个文件夹,server1 server2 server3,然后每个文件夹里面解压一个zookeeper的下载包 二、创建myid文件 进入data目录,创建一个myid的文件,里面写入一个数字,server1,就写一个1,server2对应myid文件就写入2,server3对应myid文件就写个3 三、在conf目录下创建一个配置文件zoo.cfg tickTime=2000 dataDir=/Users/zdandljb/zookeeper/data dataLogDir=xxx/zookeeper/server1/ clientPort=2181 initLimit=5 syncLimit=2 server.1=server1:2888:3888 server.2=server2:2889:3889 server.3=server3:2890:3890 为了防止端口冲突,要配置不同的端口号。 常用参数 dataDir:用于存放内存数据库快照的文件夹,同时用于集群的myid文件也存在这个文件夹里。 dataLogDir:用于单独设置transaction log的目录,transaction log分离可以避免和普通log还有快照的竞争。 tickTime:心跳时间,为了确保client-server连接存在的,以毫秒为单位,最小超时时间为两个心跳时间。 clientPort:客户端监听端口。 initLimit:初始化连接时最长能忍受多少个心跳时间间隔数 syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度 server.x=[hostname]:nnnnn[:nnnnn] 配置集群里面的主机信息,其中: ①server.x:server.x的x要写在myid文件中,决定当前机器的id, ②第一个port用于连接leader, ③第二个用于leader选举。 ④如果electionAlg为0,则不需要第二个port。 ⑤hostname也可以填ip。 伪集群模式安转时,后面连着的2个端口3个server都不要一样,否则端口冲突。 electionAlg 用于选举的实现的参数: 1:LeaderElection 2:AuthFastLeaderElection 3:FastLeaderElection zookeeper默认使用FastLeaderElection进行Leader选举
-
Java中的事务——全局事务与本地事务 在上一篇文章中说到过,Java事务的类型有三种:JDBC事务、JTA(Java Transaction API)事务、容器事务。这是从事务的实现角度区分的,本文从另外一个角度来再次区分一下Java中的事务。 站在事务管理的角度,可以把Java中用到的事务分为本地事务和全局事务。 本地事务 不用事务的编程框架来管理事务,直接使用资源管理器来控制事务。典型的就是java.sql.Connection 中的 setAutoCommit、commit、rollback方法。 本地事务的优点 支持严格的ACID属性 可靠 高效 状态可以只在资源管理器中维护 应用编程模型简单 本地事务的局限 不具备分布式事务处理能力 隔离的最小单位由资源管理器决定,如数据库中的一条记录 本地事务比较简单,对事务不太了解的同学可以阅读我的博客中其他关于事务的内容。 全局事务 前面我们介绍了本地事务,本地事务是我们在编程中比较常接触的事务,比如典型的jdbc操作,在保证ACID方面做的非常出色。但是本地事务无法解决分布式场景中的事务问题。 我前面的文章中专门介绍过分布式场景中为什么需要事务。这里我再稍微回顾一下。 典型的分布式事务场景 转账 对于银行账户间转账的问题。账户A向账户B转账,从实现上来看,一般可以拆分为“从账户A中扣钱”、“向账户B中加钱”两个操作步骤,两个账户大多数情况下会被切分到不同的数据库上,更多的是,两个操作会是两次服务调用。这两个操作要求做到要么同时成功、要么同时失败。因此引入了分布式事务问题。 下单 在电商网站上,在消费者点击购买按钮后,交易后台会进行库存检查、下单、减库存、更新订单状态等一连串的服务调用,每一个操作对应一个独立的服务,服务一般会有独立的数据库,因此会产生分布式事务问题。 由于用一次操作,数据要写入的数据库不一致,或者调用的服务都是RPC服务,那么就会无法保证操作在同一个事务中被处理掉。所以就会存在分布式的事务问题。 全局事务的定义 在上面的场景中会出现分布式事务问题,那么全局事务就是一个标准的分布式事务。下面我们尝试着给全局事务下一个定义: 全局事务是由资源管理器管理和协调的事务。 全局事务是一个DTP模型的事务,所谓DTP模型指的是X/Open DTP(X/Open Distributed Transaction Processing Reference Model),是X/Open 这个组织定义的一套分布式事务的标准,也就是了定义了规范和API接口,由这个厂商进行具体的实现。 X/Open DTP 定义了三个组件:AP,TM,RM 和两个协议:XA、TX AP(Application Program):也就是应用程序,可以理解为使用DTP的程序 RM(Resource Manager):资源管理器,这里可以理解为一个DBMS系统,或者消息服务器管理系统,应用程序通过资源管理器对资源进行控制。 TM(Transaction Manager):事务管理器,负责协调和管理事务,提供给AP应用程序编程接口以及管理资源管理器。 XA协议:应用或应用服务器与事务管理之前通信的接口 TX协议:全局事务管理器与资源管理器之间通信的接口 事务管理器控制着全局事务,管理事务生命周期,并协调资源。资源管理器负责控制和管理实际资源。 这里还要提到一个点,就是2PC(两阶段提交),在全局事务中,为了保证所有的操作可以一次性要么全提交,要么全失败。事务管理器和资源管理器之间的事务操作的控制是采用2PC来进行的,关于2PC,我博客中有文章专门介绍,这里不再赘述。 J2EE中全局事务的实现 Java自身提供了一些API可以用来实现全局事务。Java中的事务——JDBC事务和JTA事务中介绍的JTA事务就可以用来实现J2EE中的全局事务。 JTA(Java Transaction API):面向应用、应用服务器与资 源管理器的高层事务接口。 JTS(Java Transaction Service):JTA事务管理器的实现标 准,向上支持JTA,向下通过CORBA OTS实现跨事务域的互 操作性。 EJB:基于组件的应用编程模型,通过声明式事务管理进一步 简化事务应用的编程。 全局事务的优缺点 全局事务,作为一种标准的分布式事务解决方案,他解决了本地事务无法满足分布式场景中数据的ACID的要求。 在关于分布式事务、两阶段提交协议、三阶提交协议中我曾经介绍过,2PC本身是存在同步阻塞问题,这就会导致效率变低,所以,采用2PC进行事务控制的全局事务也必然存在效率低的问题。这也是全局事务最致命的缺点,在提倡微服务的今天,这是不能容忍的。 总结 本文主要介绍了本地事务和全局事务,本地事务很简单,在Java中可以使用JDBC来实现本地事务,全局事务是一种基本的分布式事务解决方案,是符合DTP模型的事务管理机制。 目前,越来越多的web开发要涉及到分布式事务,尤其是微服务架构最近越来越火,在微服务架构中,分布式事务是必然存在的。对于分布式事务的处理,本文主要介绍了一个典型的方案——全局事务。但是实际上,低效率的全局事务并不是很适合用来解决大型网站的分布式事务问题。 在业内,主要用来解决分布式事务的方案是使用柔性事务。柔性事务包括几种类型:两阶段型、补偿型、异步确保型和最大努力通知型。后面我会有文章继续介绍柔性事务。请继续关注。
-
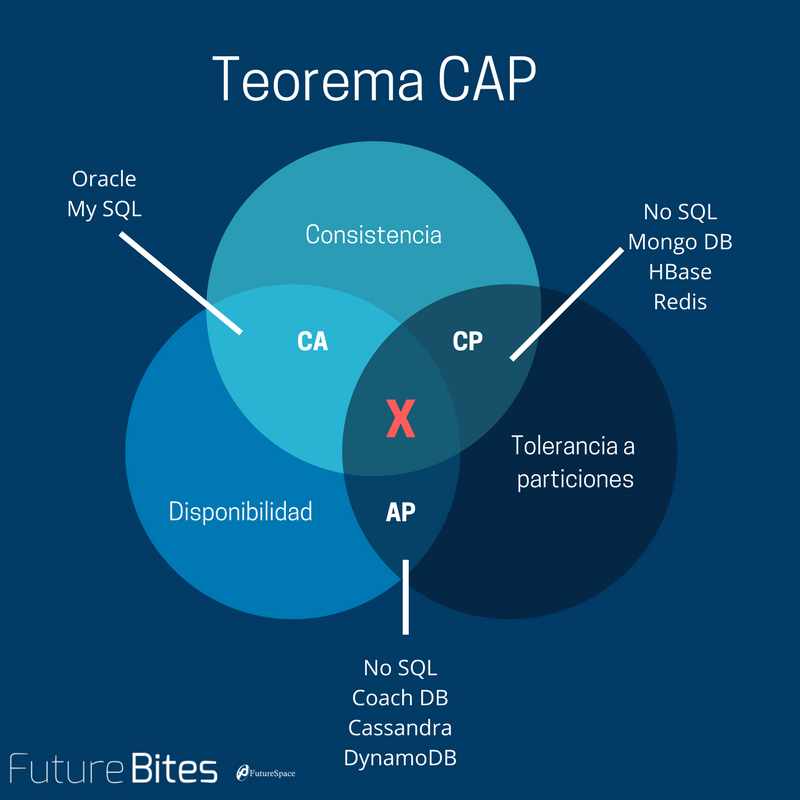
分布式系统的CAP理论 2000年7月,加州大学伯克利分校的Eric Brewer教授在ACM PODC会议上提出CAP猜想。2年后,麻省理工学院的Seth Gilbert和Nancy Lynch从理论上证明了CAP。之后,CAP理论正式成为分布式计算领域的公认定理。 无论你是一个系统架构师,还是一个普通开发,当你开发或者设计一个分布式系统的时候,CAP理论是无论如何也绕不过去的。本文就来介绍一下到底什么是CAP理论,如何证明CAP理论,以及CAP的权衡问题。 CAP理论概述 CAP理论:一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。 读者需要注意的的是,CAP理论中的CA和数据库事务中ACID的CA并完全是同一回事儿。两者之中的A都是C都是一致性(Consistency)。CAP中的A指的是可用性(Availability),而ACID中的A指的是原子性(Atomicity),切勿混为一谈。 CAP的定义 Consistency 一致性 一致性指“all nodes see the same data at the same time”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致,所以,一致性,说的就是数据一致性。分布式的一致性 对于一致性,可以分为从客户端和服务端两个不同的视角。从客户端来看,一致性主要指的是多并发访问时更新过的数据如何获取的问题。从服务端来看,则是更新如何复制分布到整个系统,以保证数据最终一致。 一致性是因为有并发读写才有的问题,因此在理解一致性的问题时,一定要注意结合考虑并发读写的场景。 从客户端角度,多进程并发访问时,更新过的数据在不同进程如何获取的不同策略,决定了不同的一致性。 三种一致性策略 对于关系型数据库,要求更新过的数据能被后续的访问都能看到,这是强一致性。 如果能容忍后续的部分或者全部访问不到,则是弱一致性。 如果经过一段时间后要求能访问到更新后的数据,则是最终一致性。 CAP中说,不可能同时满足的这个一致性指的是强一致性。 Availability 可用性 可用性指“Reads and writes always succeed”,即服务一直可用,而且是正常响应时间。 对于一个可用性的分布式系统,每一个非故障的节点必须对每一个请求作出响应。所以,一般我们在衡量一个系统的可用性的时候,都是通过停机时间来计算的。 可用性分类 可用水平(%) 年可容忍停机时间 容错可用性 99.9999
-
Zookeeper介绍(四)——Zookeeper中的基本概念 在介绍了Zookeeper的安装之后,就可以了解一下Zookeeper中的常用概念了。本文将主要介绍ZK中角色、数据模型、节点、ACL、watcher等概念。 角色 在Zookeeper概述中也提到过,Zookeeper的Follower在接到客户端请求之后会把请求转发到Leader,这里提到的Follower和Leader就是ZK中的角色,ZK中有以下角色: 领导者(leader) 负责进行投票的发起和决议,更新系统状态。为客户端提供读和写服务。 跟随者(follower) 用于接受客户端请求并想客户端返回结果,在选主过程中参与投票。为客户端提供读服务。 观察者(observer) 可以接受客户端连接,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度 客户端(client) 请求发起方 数据模型 ZK中数据是以目录结构的形式存储的。其中的每一个存储数据的节点都叫做Znode,每个Znode都有一个唯一的路径标识。和目录结构类似,每一个节点都可以可有子节点(临时节点除外)。节点中可以存储数据和状态信息,每个Znode上可以配置监视器(watcher),用于监听节点中的数据变化。节点不支持部分读写,而是一次性完整读写。 节点 Znode有四种类型,PERSISTENT(持久节点)、PERSISTENT_SEQUENTIAL(持久的连续节点)、EPHEMERAL(临时节点)、EPHEMERAL_SEQUENTIAL(临时的连续节点) Znode的类型在创建时确定并且之后不能再修改 临时节点 临时节点的生命周期和客户端会话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。 String root = "/ephemeral"; String createdPath = zk.create(root, root.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); System.out.println("createdPath = " + createdPath); String path = "/ephemeral/test01" ; createdPath = zk.create(path, path.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); System.out.println("createdPath = " + createdPath); Thread.sleep(1000 * 20); // 等待20秒关闭ZooKeeper连接 zk.close(); // 关闭连接后创建的临时节点将自动删除 临时节点不能有子节点 持久节点 所谓持久节点,是指在节点创建后,就一直存在,直到有删除操作来主动清除这个节点——不会因为创建该节点的客户端会话失效而消失。 String root = "/computer"; String createdPath = zk.create(root, root.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); System.out.println("createdPath = " + createdPath); 临时顺序节点 临时节点的生命周期和客户端会话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。注意创建的节点会自动加上编号。 String root = "/ephemeral"; String createdPath = zk.create(root, root.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); System.out.println("createdPath = " + createdPath); String path = "/ephemeral/test01" ; createdPath = zk.create(path, path.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL); System.out.println("createdPath = " + createdPath); Thread.sleep(1000 * 20); // 等待20秒关闭ZooKeeper连接 zk.close(); // 关闭连接后创建的临时节点将自动删除 输出结果: type = None createdPath = /ephemeral/test0000000003 createdPath = /ephemeral/test0000000004 createdPath = /ephemeral/test0000000005 createdPath = /ephemeral/test0000000006 持久顺序节点 这类节点的基本特性和持久节点类型是一致的。额外的特性是,在ZooKeeper中,每个父节点会为他的第一级子节点维护一份时序,会记录每个子节点创建的先后顺序。基于这个特性,在创建子节点的时候,可以设置这个属性,那么在创建节点过程中,ZooKeeper会自动为给定节点名加上一个数字后缀,作为新的节点名。这个数字后缀的范围是整型的最大值。 String root = "/computer"; String createdPath = zk.create(root, root.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); System.out.println("createdPath = " + createdPath); for (int i=0; i
-
初识分布式系统 随着大型网站的各种高并发访问、海量数据处理等场景越来越多,如何实现网站的高可用、易伸缩、可扩展、安全等目标就显得越来越重要。为了解决这样一系列问题,大型网站的架构也在不断发展。提高大型网站的高可用架构,不得不提的就是分布式。本文主要简单介绍了分布式系统的概念、分布式系统的特点、常用的分布式方案以及分布式和集群的区别等。 一、集中式系统 在学习分布式之前,先了解一下与之相对应的集中式系统是什么样的。 集中式系统用一句话概括就是:一个主机带多个终端。终端没有数据处理能力,仅负责数据的录入和输出。而运算、存储等全部在主机上进行。现在的银行系统,大部分都是这种集中式的系统,此外,在大型企业、科研单位、军队、政府等也有分布。集中式系统,主要流行于上个世纪。 集中式系统的最大的特点就是部署结构非常简单,底层一般采用从IBM、HP等厂商购买到的昂贵的大型主机。因此无需考虑如何对服务进行多节点的部署,也就不用考虑各节点之间的分布式协作问题。但是,由于采用单机部署。很可能带来系统大而复杂、难于维护、发生单点故障(单个点发生故障的时候会波及到整个系统或者网络,从而导致整个系统或者网络的瘫痪)、扩展性差等问题。 二、分布式系统(distributed system) 在《分布式系统概念与设计》一书中,对分布式系统做了如下定义: 分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统 简单来说就是一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。分布式意味着可以采用更多的普通计算机(相对于昂贵的大型机)组成分布式集群对外提供服务。计算机越多,CPU、内存、存储资源等也就越多,能够处理的并发访问量也就越大。 从分布式系统的概念中我们知道,各个主机之间通信和协调主要通过网络进行,所以,分布式系统中的计算机在空间上几乎没有任何限制,这些计算机可能被放在不同的机柜上,也可能被部署在不同的机房中,还可能在不同的城市中,对于大型的网站甚至可能分布在不同的国家和地区。但是,无论空间上如何分布,一个标准的分布式系统应该具有以下几个主要特征: 分布性 分布式系统中的多台计算机之间在空间位置上可以随意分布,系统中的多台计算机之间没有主、从之分,即没有控制整个系统的主机,也没有受控的从机。 透明性 系统资源被所有计算机共享。每台计算机的用户不仅可以使用本机的资源,还可以使用本分布式系统中其他计算机的资源(包括CPU、文件、打印机等)。 同一性 系统中的若干台计算机可以互相协作来完成一个共同的任务,或者说一个程序可以分布在几台计算机上并行地运行。 通信性 系统中任意两台计算机都可以通过通信来交换信息。 和集中式系统相比,分布式系统的性价比更高、处理能力更强、可靠性更高、也有很好的扩展性。但是,分布式在解决了网站的高并发问题的同时也带来了一些其他问题。首先,分布式的必要条件就是网络,这可能对性能甚至服务能力造成一定的影响。其次,一个集群中的服务器数量越多,服务器宕机的概率也就越大。另外,由于服务在集群中分布是部署,用户的请求只会落到其中一台机器上,所以,一旦处理不好就很容易产生数据一致性问题。 常用的分布式方案 分布式应用和服务 将应用和服务进行分层和分割,然后将应用和服务模块进行分布式部署。这样做不仅可以提高并发访问能力、减少数据库连接和资源消耗,还能使不同应用复用共同的服务,使业务易于扩展。 分布式静态资源 对网站的静态资源如JS、CSS、图片等资源进行分布式部署可以减轻应用服务器的负载压力,提高访问速度。 分布式数据和存储 大型网站常常需要处理海量数据,单台计算机往往无法提供足够的内存空间,可以对这些数据进行分布式存储。 分布式计算 随着计算技术的发展,有些应用需要非常巨大的计算能力才能完成,如果采用集中式计算,需要耗费相当长的时间来完成。分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。 分布式与集群 分布式(distributed)是指在多台不同的服务器中部署不同的服务模块,通过远程调用协同工作,对外提供服务。 集群(cluster)是指在多台不同的服务器中部署相同应用或服务模块,构成一个集群,通过负载均衡设备对外提供服务。