找到
2
篇与
框架
相关的结果
-
 Webx PullService分析 写在前面:上周在做项目的时候遇到这样一种情况,就是我在vm模板里面接收到后端传过来的数据,数据格式是一个字符串,字符串是使用逗号隔开的一些监控点信息的名字,我需要在前端将这个字符串分割,然后分别对每一个监控点信息名字加上链接。当时第一想法是使用js实现,但是发现js没办法实现我的需求(至少我做不到),因为本身我拿到的字符串就是在一个对象的某一个属性,而这个对象我又是从List里面遍历出来的。代码如下: #foreach ( $defination in $data ) #end 有人会说,为什么不在后台直接将字符串分割,然后拼接上超链接在传到前端直接输出呢,我没这么做的原因是:第一、这么做是有风险的、第二、我也没办法这么做。首先看看我的另外一篇博文解决webx的xss和csrf漏洞,文中我们提到,将html、js、css代码传到前端,前端不做任何处理就输出这是有安全漏洞的。所以,只能想办法在前端进行超链接的拼接,好在集团有关于这个的解决方案:pull service 一、 概述 pull service的功能是将对象置入模板中。被pull service放到模板中的对象,不需要应用程序的干预即可直接使用。如果模板没有用到某个对象,则不会产生创建该对象的开销。看起来,这些对象像是被模板主动“拉”进context的,而不是由应用程序push进context中的。这就是pull service名称的来源。 1.1. 为什么需要pull service? 通常我们在做一个页面时,需要处理一些常见的操作,如:日期转换、字符串处理、生成动态URL、生成CSRF Tooken、获取上下文状态、表单验证等。要完这些操作,我们通常使用JEE设计模式中的视图助手(view helper)来完成,如:在JSP中是通过java bean的方式来封装这些处理逻辑,并在需要的地方引用这个java bean的相应方法,从而实现这些操作的重用。 java bean虽然解决了我们碰到的这些问题,但缺少统一的配置以及这些对象实例的生命周期管理(如:单例、request、session等级别)。这时,我们就需要引入一个类似于java bean的机制来辅助我们页面的开发,并增加统一配置与生命周期管理。 二、设计 Pull service的最终表现是由一组具有不同功能与作用域的pull tool,并为这些pull tool提供统一的配置、生命周期管理,使之可以方便的注入的我们的view层上下文,从而满足我们view层的渲染辅助。 2.1. Pull tools作用域 global :就是singleton,在系统启动时创建实例 request :在每个request的第一次访问该tool时,自动创建实例 注意,ToolFactory和ToolSetFactory本身一定是singleton的。但他们所创建的tool对象的作用域,是由ToolFactory或ToolSetFactory.isSingleton方法决定的。 2.2. 单个tool和tool set 单个tool,由ToolFactory创建,每个factory创建一个tool tool集合,由ToolSetFactory创建,每个factory创建一组tool。这种接口赋予ToolSetFactory自主决定将创建哪些对象的权力。例如在webx中,uri broker tool将一组URI brokers对象放到模板中。 2.3. 延迟创建实例 对于global tool或tool set,全部实例均在系统启动时创建。 对于非global tool或tool set,所有实例均在每次request时,第一次访问该tool时创建。如果一个tool set将创建一组tools,那么每一个tool都是延迟创建的。 2.4. RuntimeToolSetFactory 这是一个特殊的tool set factory接口,主要用于兼容以前的pull service实现。这个factory会在每次request中,都调用createToolSet方法生成toolset实例。因此它的性能不如tool set factory。正常情况下不推荐使用它。 2.5. Pull tools全局性 parent context中的tools被所有子context中的tools共享。但子context可以覆盖父context中的同名tools(注:只是以当前context的tool的引用为优先,不影响父context中的实例)。 三、使用 3.1 配置: 在webx.xml文件中加入: 3.2 ID命名约定 ,(明确指定)此时id=xxx ,此时id=hello 此时id=hello 3.3 由以下的内置工具tool构成: arrayUtil ==>> ArrayUtil classLoaderUtil ==>> ClassLoaderUtil classUtil ==>> ClassUtil enumUtil ==>> EnumUtil exceptionUtil ==>> ExceptionUtil fileUtil ==>> FileUtil localeUtil ==>> LocaleUtil mathUtil ==>> MathUtil messageUtil ==>> MessageUtil objectUtil ==>> ObjectUtil streamUtil ==>> StreamUtil stringEscapeUtil ==>> StringEscapeUtil stringUtil ==>> StringUtil systemUtil ==>> SystemUtil 四、使用方式: 了解完了pull service,我们回到刚开始那个问题,如何解决我的需求: #foreach ( $defination in $data ) #foreach ($monitor in $!stringUtil.split($!defination.monitors,",")) $monitor, #end #end 看到 中的那段代码了么,首先我们使用stringUtil类的split方法将字符串按照逗号进行拆解,拆解之后返回的是一个字符串数组,然后我们用foreach遍历这个数组,拿到每一个元素进行字符串的拼接。这段代码:$!stringUtil.split($!defination.monitors,",")就是使用pull service代码。上面我们介绍过得哪些内置工具都可以拿过来直接使用。 五、自定义 定义工具类: public class IconTool { public String getIconCodeByKey(String key){ String iconCode = ""; if(StringUtil.isNotBlank(key)){ switch (key) { case "site": iconCode ="xe629;"; break; default: iconCode ="xe63b;"; break; } return iconCode; } return "xe65e;"; } } 配置文件: 使用: 在vm文件中调用: $!iconTool.getIconCodeByKey($page.iconCode)
Webx PullService分析 写在前面:上周在做项目的时候遇到这样一种情况,就是我在vm模板里面接收到后端传过来的数据,数据格式是一个字符串,字符串是使用逗号隔开的一些监控点信息的名字,我需要在前端将这个字符串分割,然后分别对每一个监控点信息名字加上链接。当时第一想法是使用js实现,但是发现js没办法实现我的需求(至少我做不到),因为本身我拿到的字符串就是在一个对象的某一个属性,而这个对象我又是从List里面遍历出来的。代码如下: #foreach ( $defination in $data ) #end 有人会说,为什么不在后台直接将字符串分割,然后拼接上超链接在传到前端直接输出呢,我没这么做的原因是:第一、这么做是有风险的、第二、我也没办法这么做。首先看看我的另外一篇博文解决webx的xss和csrf漏洞,文中我们提到,将html、js、css代码传到前端,前端不做任何处理就输出这是有安全漏洞的。所以,只能想办法在前端进行超链接的拼接,好在集团有关于这个的解决方案:pull service 一、 概述 pull service的功能是将对象置入模板中。被pull service放到模板中的对象,不需要应用程序的干预即可直接使用。如果模板没有用到某个对象,则不会产生创建该对象的开销。看起来,这些对象像是被模板主动“拉”进context的,而不是由应用程序push进context中的。这就是pull service名称的来源。 1.1. 为什么需要pull service? 通常我们在做一个页面时,需要处理一些常见的操作,如:日期转换、字符串处理、生成动态URL、生成CSRF Tooken、获取上下文状态、表单验证等。要完这些操作,我们通常使用JEE设计模式中的视图助手(view helper)来完成,如:在JSP中是通过java bean的方式来封装这些处理逻辑,并在需要的地方引用这个java bean的相应方法,从而实现这些操作的重用。 java bean虽然解决了我们碰到的这些问题,但缺少统一的配置以及这些对象实例的生命周期管理(如:单例、request、session等级别)。这时,我们就需要引入一个类似于java bean的机制来辅助我们页面的开发,并增加统一配置与生命周期管理。 二、设计 Pull service的最终表现是由一组具有不同功能与作用域的pull tool,并为这些pull tool提供统一的配置、生命周期管理,使之可以方便的注入的我们的view层上下文,从而满足我们view层的渲染辅助。 2.1. Pull tools作用域 global :就是singleton,在系统启动时创建实例 request :在每个request的第一次访问该tool时,自动创建实例 注意,ToolFactory和ToolSetFactory本身一定是singleton的。但他们所创建的tool对象的作用域,是由ToolFactory或ToolSetFactory.isSingleton方法决定的。 2.2. 单个tool和tool set 单个tool,由ToolFactory创建,每个factory创建一个tool tool集合,由ToolSetFactory创建,每个factory创建一组tool。这种接口赋予ToolSetFactory自主决定将创建哪些对象的权力。例如在webx中,uri broker tool将一组URI brokers对象放到模板中。 2.3. 延迟创建实例 对于global tool或tool set,全部实例均在系统启动时创建。 对于非global tool或tool set,所有实例均在每次request时,第一次访问该tool时创建。如果一个tool set将创建一组tools,那么每一个tool都是延迟创建的。 2.4. RuntimeToolSetFactory 这是一个特殊的tool set factory接口,主要用于兼容以前的pull service实现。这个factory会在每次request中,都调用createToolSet方法生成toolset实例。因此它的性能不如tool set factory。正常情况下不推荐使用它。 2.5. Pull tools全局性 parent context中的tools被所有子context中的tools共享。但子context可以覆盖父context中的同名tools(注:只是以当前context的tool的引用为优先,不影响父context中的实例)。 三、使用 3.1 配置: 在webx.xml文件中加入: 3.2 ID命名约定 ,(明确指定)此时id=xxx ,此时id=hello 此时id=hello 3.3 由以下的内置工具tool构成: arrayUtil ==>> ArrayUtil classLoaderUtil ==>> ClassLoaderUtil classUtil ==>> ClassUtil enumUtil ==>> EnumUtil exceptionUtil ==>> ExceptionUtil fileUtil ==>> FileUtil localeUtil ==>> LocaleUtil mathUtil ==>> MathUtil messageUtil ==>> MessageUtil objectUtil ==>> ObjectUtil streamUtil ==>> StreamUtil stringEscapeUtil ==>> StringEscapeUtil stringUtil ==>> StringUtil systemUtil ==>> SystemUtil 四、使用方式: 了解完了pull service,我们回到刚开始那个问题,如何解决我的需求: #foreach ( $defination in $data ) #foreach ($monitor in $!stringUtil.split($!defination.monitors,",")) $monitor, #end #end 看到 中的那段代码了么,首先我们使用stringUtil类的split方法将字符串按照逗号进行拆解,拆解之后返回的是一个字符串数组,然后我们用foreach遍历这个数组,拿到每一个元素进行字符串的拼接。这段代码:$!stringUtil.split($!defination.monitors,",")就是使用pull service代码。上面我们介绍过得哪些内置工具都可以拿过来直接使用。 五、自定义 定义工具类: public class IconTool { public String getIconCodeByKey(String key){ String iconCode = ""; if(StringUtil.isNotBlank(key)){ switch (key) { case "site": iconCode ="xe629;"; break; default: iconCode ="xe63b;"; break; } return iconCode; } return "xe65e;"; } } 配置文件: 使用: 在vm文件中调用: $!iconTool.getIconCodeByKey($page.iconCode)
-
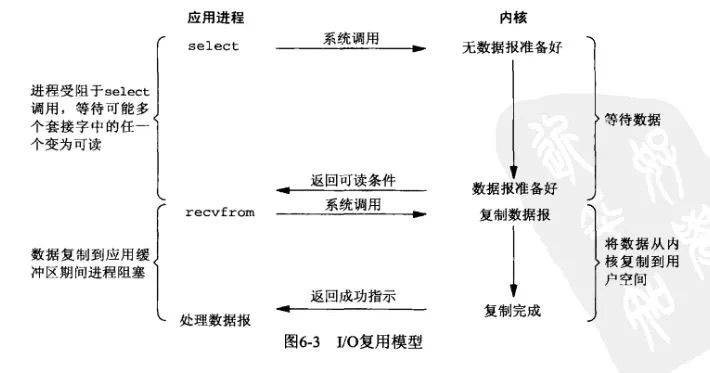
Redis不是一直号称单线程效率也很高吗,为什么又采用多线程了? Redis是目前广为人知的一个内存数据库,在各个场景中都有着非常丰富的应用,前段时间Redis推出了6.0的版本,在新版本中采用了多线程模型。 因为我们公司使用的内存数据库是自研的,按理说我对Redis的关注其实并不算多,但是因为Redis用的比较广泛,所以我需要了解一下这样方便我进行面试。 总不能候选人用过Redis,但是我非要问人家阿里的Tair是怎么回事吧。 所以,在Redis 6.0 推出之后,我想去了解下为什么采用多线程,现在采用的多线程和以前版本有什么区别?为什么这么晚才使用多线程? Redis不是已经采用了多路复用技术吗?不是号称很高的性能了吗?为啥还要采用多线程模型呢? 本文就来分析下这些问题以及背后的思考。 Redis为什么最开始被设计成单线程的? Redis作为一个成熟的分布式缓存框架,它由很多个模块组成,如网络请求模块、索引模块、存储模块、高可用集群支撑模块、数据操作模块等。 很多人说Redis是单线程的,就认为Redis中所有模块的操作都是单线程的,其实这是不对的。 我们所说的Redis单线程,指的是”其网络IO和键值对读写是由一个线程完成的”,也就是说,Redis中只有网络请求模块和数据操作模块是单线程的。而其他的如持久化存储模块、集群支撑模块等是多线程的。 所以说,Redis中并不是没有多线程模型的,早在Redis 4.0的时候就已经针对部分命令做了多线程化。 那么,为什么网络操作模块和数据存储模块最初并没有使用多线程呢? 这个问题的答案比较简单!因为:”没必要!” 为什么没必要呢?我们先来说一下,什么情况下要使用多线程? 多线程适用场景 一个计算机程序在执行的过程中,主要需要进行两种操作分别是读写操作和计算操作。 其中读写操作主要是涉及到的就是I/O操作,其中包括网络I/O和磁盘I/O。计算操作主要涉及到CPU。 而多线程的目的,就是通过并发的方式来提升I/O的利用率和CPU的利用率。 那么,Redis需不需要通过多线程的方式来提升提升I/O的利用率和CPU的利用率呢? 首先,我们可以肯定的说,Redis不需要提升CPU利用率,因为Redis的操作基本都是基于内存的,CPU资源根本就不是Redis的性能瓶颈。 所以,通过多线程技术来提升Redis的CPU利用率这一点是完全没必要的。 那么,使用多线程技术来提升Redis的I/O利用率呢?是不是有必要呢? Redis确实是一个I/O操作密集的框架,他的数据操作过程中,会有大量的网络I/O和磁盘I/O的发生。要想提升Redis的性能,是一定要提升Redis的I/O利用率的,这一点毋庸置疑。 但是,提升I/O利用率,并不是只有采用多线程技术这一条路可以走! 多线程的弊端 我们在很多文章中介绍过一些Java中的多线程技术,如内存模型、锁、CAS等,这些都是Java中提供的一些在多线程情况下保证线程安全的技术。 线程安全:是编程中的术语,指某个函数、函数库在并发环境中被调用时,能够正确地处理多个线程之间的共享变量,使程序功能正确完成。 和Java类似,所有支持多线程的编程语言或者框架,都不得不面对的一个问题,那就是如何解决多线程编程模式带来的共享资源的并发控制问题。 虽然,采用多线程可以帮助我们提升CPU和I/O的利用率,但是多线程带来的并发问题也给这些语言和框架带来了更多的复杂性。而且,多线程模型中,多个线程的互相切换也会带来一定的性能开销。 所以,在提升I/O利用率这个方面上,Redis并没有采用多线程技术,而是选择了多路复用 I/O技术。 小结 Redis并没有在网络请求模块和数据操作模块中使用多线程模型,主要是基于以下四个原因: 1、Redis 操作基于内存,绝大多数操作的性能瓶颈不在 CPU 2、使用单线程模型,可维护性更高,开发,调试和维护的成本更低 3、单线程模型,避免了线程间切换带来的性能开销 4、在单线程中使用多路复用 I/O技术也能提升Redis的I/O利用率 还是要记住:Redis并不是完全单线程的,只是有关键的网络IO和键值对读写是由一个线程完成的。 Redis的多路复用 多路复用这个词,相信很多人都不陌生。我之前的很多文章中也够提到过这个词。 其中在介绍Linux IO模型的时候我们提到过它、在介绍HTTP/2的原理的时候,我们也提到过他。 那么,Redis的多路复用技术和我们之前介绍的又有什么区别呢? 这里先讲讲Linux多路复用技术,就是多个进程的IO可以注册到同一个管道上,这个管道会统一和内核进行交互。当管道中的某一个请求需要的数据准备好之后,进程再把对应的数据拷贝到用户空间中。  多看一遍上面这张图和上面那句话,后面可能还会用得到。 也就是说,通过一个线程来处理多个IO流。 IO多路复用在Linux下包括了三种,select、poll、epoll,抽象来看,他们功能是类似的,但具体细节各有不同。 其实,Redis的IO多路复用程序的所有功能都是通过包装操作系统的IO多路复用函数库来实现的。每个IO多路复用函数库在Redis源码中都有对应的一个单独的文件。  在Redis 中,每当一个套接字准备好执行连接应答、写入、读取、关闭等操作时,就会产生一个文件事件。因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发地出现。  一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。 所以,Redis选择使用多路复用IO技术来提升I/O利用率。 而之所以Redis能够有这么高的性能,不仅仅和采用多路复用技术和单线程有关,此外还有以下几个原因: 1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。 2、数据结构简单,对数据操作也简单,如哈希表、跳表都有很高的性能。 3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU 4、使用多路I/O复用模型 为什么Redis 6.0 引入多线程 2020年5月份,Redis正式推出了6.0版本,这个版本中有很多重要的新特性,其中多线程特性引起了广泛关注。 但是,需要提醒大家的是,Redis 6.0中的多线程,也只是针对处理网络请求过程采用了多线程,而数据的读写命令,仍然是单线程处理的。 但是,不知道会不会有人有这样的疑问: Redis不是号称单线程也有很高的性能么? 不是说多路复用技术已经大大的提升了IO利用率了么,为啥还需要多线程? 主要是因为我们对Redis有着更高的要求。 根据测算,Redis 将所有数据放在内存中,内存的响应时长大约为 100 纳秒,对于小数据包,Redis 服务器可以处理 80,000 到 100,000 QPS,这么高的对于 80% 的公司来说,单线程的 Redis 已经足够使用了。 但随着越来越复杂的业务场景,有些公司动不动就上亿的交易量,因此需要更大的 QPS。 为了提升QPS,很多公司的做法是部署Redis集群,并且尽可能提升Redis机器数。但是这种做法的资源消耗是巨大的。 而经过分析,限制Redis的性能的主要瓶颈出现在网络IO的处理上,虽然之前采用了多路复用技术。但是我们前面也提到过,多路复用的IO模型本质上仍然是同步阻塞型IO模型。 下面是多路复用IO中select函数的处理过程:  从上图我们可以看到,在多路复用的IO模型中,在处理网络请求时,调用 select (其他函数同理)的过程是阻塞的,也就是说这个过程会阻塞线程,如果并发量很高,此处可能会成为瓶颈。 虽然现在很多服务器都是多个CPU核的,但是对于Redis来说,因为使用了单线程,在一次数据操作的过程中,有大量的CPU时间片是耗费在了网络IO的同步处理上的,并没有充分的发挥出多核的优势。 如果能采用多线程,使得网络处理的请求并发进行,就可以大大的提升性能。多线程除了可以减少由于网络 I/O 等待造成的影响,还可以充分利用 CPU 的多核优势。 所以,Redis 6.0采用多个IO线程来处理网络请求,网络请求的解析可以由其他线程完成,然后把解析后的请求交由主线程进行实际的内存读写。提升网络请求处理的并行度,进而提升整体性能。 但是,Redis 的多 IO 线程只是用来处理网络请求的,对于读写命令,Redis 仍然使用单线程来处理。 那么,在引入多线程之后,如何解决并发带来的线程安全问题呢? 这就是为什么我们前面多次提到的”Redis 6.0的多线程只用来处理网络请求,而数据的读写还是单线程”的原因。 Redis 6.0 只有在网络请求的接收和解析,以及请求后的数据通过网络返回给时,使用了多线程。而数据读写操作还是由单线程来完成的,所以,这样就不会出现并发问题了。 参考资料: https://www.cnblogs.com/Zzbj/p/13531622.html https://xie.infoq.cn/article/b3816e9fe3ac77684b4f29348 https://jishuin.proginn.com/p/763bfbd2a1c2 《极客时间:Redis核心技术与实战》