找到
11
篇与
综合应用
相关的结果
-
 负载均衡(一)——初识负载均衡 最近在看的几本书中都提到负载均衡技术,发现自己对这部分内容了解的并不是很多,所以把这块知识补充一下。与君共勉~! 什么是负载均衡(Load balancing) 在网站创立初期,我们一般都使用单台机器对台提供集中式服务,但是随着业务量越来越大,无论是性能上还是稳定性上都有了更大的挑战。这时候我们就会想到通过扩容的方式来提供更好的服务。我们一般会把多台机器组成一个集群对外提供服务。然而,我们的网站对外提供的访问入口都是一个的,比如www.taobao.com。那么当用户在浏览器输入www.taobao.com的时候如何将用户的请求分发到集群中不同的机器上呢,这就是负载均衡在做的事情。 负载均衡分类 现在我们知道,负载均衡就是一种计算机网络技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁碟驱动器或其他资源中分配负载,以达到最佳化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。那么,这种计算机技术的实现方式有多种。大致可以分为以下几种,其中最常用的是四层和七层负载均衡: 二层负载均衡 负载均衡服务器对外依然提供一个VIP(虚IP),集群中不同的机器采用相同IP地址,但是机器的MAC地址不一样。当负载均衡服务器接受到请求之后,通过改写报文的目标MAC地址的方式将请求转发到目标机器实现负载均衡。 三层负载均衡 和二层负载均衡类似,负载均衡服务器对外依然提供一个VIP(虚IP),但是集群中不同的机器采用不同的IP地址。当负载均衡服务器接受到请求之后,根据不同的负载均衡算法,通过IP将请求转发至不同的真实服务器。 四层负载均衡 四层负载均衡工作在OSI模型的传输层,由于在传输层,只有TCP/UDP协议,这两种协议中除了包含源IP、目标IP以外,还包含源端口号及目的端口号。四层负载均衡服务器在接受到客户端请求后,以后通过修改数据包的地址信息(IP+端口号)将流量转发到应用服务器。 七层负载均衡 七层负载均衡工作在OSI模型的应用层,应用层协议较多,常用http、radius、dns等。七层负载就可以基于这些协议来负载。这些应用层协议中会包含很多有意义的内容。比如同一个Web服务器的负载均衡,除了根据IP加端口进行负载外,还可根据七层的URL、浏览器类别、语言来决定是否要进行负载均衡。 图,四层和七层负载均衡 对于一般的应用来说,有了Nginx就够了。Nginx可以用于七层负载均衡。但是对于一些大的网站,一般会采用DNS+四层负载+七层负载的方式进行多层次负载均衡。 图,阿里云的SLB 常用负载均衡工具 Nginx/LVS/HAProxy是目前使用最广泛的三种负载均衡软件。 LVS LVS(Linux Virtual Server),也就是Linux虚拟服务器, 是一个由章文嵩博士发起的自由软件项目。使用LVS技术要达到的目标是:通过LVS提供的负载均衡技术和Linux操作系统实现一个高性能、高可用的服务器群集,它具有良好可靠性、可扩展性和可操作性。从而以低廉的成本实现最优的服务性能。 LVS主要用来做四层负载均衡。 Nginx Nginx(发音同engine x)是一个网页服务器,它能反向代理HTTP, HTTPS, SMTP, POP3, IMAP的协议链接,以及一个负载均衡器和一个HTTP缓存。 Nginx主要用来做七层负载均衡。 HAProxy HAProxy是一个使用C语言编写的自由及开放源代码软件,其提供高可用性、负载均衡,以及基于TCP和HTTP的应用程序代理。 Haproxy主要用来做七层负载均衡。 常见负载均衡算法 上面介绍负载均衡技术的时候提到过,负载均衡服务器在决定将请求转发到具体哪台真实服务器的时候,是通过负载均衡算法来实现的。负载均衡算法可以分为两类:静态负载均衡算法和动态负载均衡算法。 静态负载均衡算法包括:轮询,比率,优先权 动态负载均衡算法包括: 最少连接数,最快响应速度,观察方法,预测法,动态性能分配,动态服务器补充,服务质量,服务类型,规则模式。 轮询(Round Robin):顺序循环将请求一次顺序循环地连接每个服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从顺序循环队列中拿出,不参加下一次的轮询,直到其恢复正常。 比率(Ratio):给每个服务器分配一个加权值为比例,根椐这个比例,把用户的请求分配到每个服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从服务器队列中拿出,不参加下一次的用户请求的分配, 直到其恢复正常。 优先权(Priority):给所有服务器分组,给每个组定义优先权,BIG-IP 用户的请求,分配给优先级最高的服务器组(在同一组内,采用轮询或比率算法,分配用户的请求);当最高优先级中所有服务器出现故障,BIG-IP 才将请求送给次优先级的服务器组。这种方式,实际为用户提供一种热备份的方式。 最少的连接方式(Least Connection):传递新的连接给那些进行最少连接处理的服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从服务器队列中拿出,不参加下一次的用户请求的分配, 直到其恢复正常。 最快模式(Fastest):传递连接给那些响应最快的服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从服务器队列中拿出,不参加下一次的用户请求的分配,直到其恢复正常。 观察模式(Observed):连接数目和响应时间以这两项的最佳平衡为依据为新的请求选择服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP就把其从服务器队列中拿出,不参加下一次的用户请求的分配,直到其恢复正常。 预测模式(Predictive):BIG-IP利用收集到的服务器当前的性能指标,进行预测分析,选择一台服务器在下一个时间片内,其性能将达到最佳的服务器相应用户的请求。(被BIG-IP 进行检测) 动态性能分配(Dynamic Ratio-APM):BIG-IP 收集到的应用程序和应用服务器的各项性能参数,动态调整流量分配。动态服务器补充(Dynamic Server Act.):当主服务器群中因故障导致数量减少时,动态地将备份服务器补充至主服务器群。 服务质量(QoS):按不同的优先级对数据流进行分配。 服务类型(ToS): 按不同的服务类型(在Type of Field中标识)负载均衡对数据流进行分配。 规则模式:针对不同的数据流设置导向规则,用户可自行。 参考资料 几种负载均衡算法
负载均衡(一)——初识负载均衡 最近在看的几本书中都提到负载均衡技术,发现自己对这部分内容了解的并不是很多,所以把这块知识补充一下。与君共勉~! 什么是负载均衡(Load balancing) 在网站创立初期,我们一般都使用单台机器对台提供集中式服务,但是随着业务量越来越大,无论是性能上还是稳定性上都有了更大的挑战。这时候我们就会想到通过扩容的方式来提供更好的服务。我们一般会把多台机器组成一个集群对外提供服务。然而,我们的网站对外提供的访问入口都是一个的,比如www.taobao.com。那么当用户在浏览器输入www.taobao.com的时候如何将用户的请求分发到集群中不同的机器上呢,这就是负载均衡在做的事情。 负载均衡分类 现在我们知道,负载均衡就是一种计算机网络技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁碟驱动器或其他资源中分配负载,以达到最佳化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。那么,这种计算机技术的实现方式有多种。大致可以分为以下几种,其中最常用的是四层和七层负载均衡: 二层负载均衡 负载均衡服务器对外依然提供一个VIP(虚IP),集群中不同的机器采用相同IP地址,但是机器的MAC地址不一样。当负载均衡服务器接受到请求之后,通过改写报文的目标MAC地址的方式将请求转发到目标机器实现负载均衡。 三层负载均衡 和二层负载均衡类似,负载均衡服务器对外依然提供一个VIP(虚IP),但是集群中不同的机器采用不同的IP地址。当负载均衡服务器接受到请求之后,根据不同的负载均衡算法,通过IP将请求转发至不同的真实服务器。 四层负载均衡 四层负载均衡工作在OSI模型的传输层,由于在传输层,只有TCP/UDP协议,这两种协议中除了包含源IP、目标IP以外,还包含源端口号及目的端口号。四层负载均衡服务器在接受到客户端请求后,以后通过修改数据包的地址信息(IP+端口号)将流量转发到应用服务器。 七层负载均衡 七层负载均衡工作在OSI模型的应用层,应用层协议较多,常用http、radius、dns等。七层负载就可以基于这些协议来负载。这些应用层协议中会包含很多有意义的内容。比如同一个Web服务器的负载均衡,除了根据IP加端口进行负载外,还可根据七层的URL、浏览器类别、语言来决定是否要进行负载均衡。 图,四层和七层负载均衡 对于一般的应用来说,有了Nginx就够了。Nginx可以用于七层负载均衡。但是对于一些大的网站,一般会采用DNS+四层负载+七层负载的方式进行多层次负载均衡。 图,阿里云的SLB 常用负载均衡工具 Nginx/LVS/HAProxy是目前使用最广泛的三种负载均衡软件。 LVS LVS(Linux Virtual Server),也就是Linux虚拟服务器, 是一个由章文嵩博士发起的自由软件项目。使用LVS技术要达到的目标是:通过LVS提供的负载均衡技术和Linux操作系统实现一个高性能、高可用的服务器群集,它具有良好可靠性、可扩展性和可操作性。从而以低廉的成本实现最优的服务性能。 LVS主要用来做四层负载均衡。 Nginx Nginx(发音同engine x)是一个网页服务器,它能反向代理HTTP, HTTPS, SMTP, POP3, IMAP的协议链接,以及一个负载均衡器和一个HTTP缓存。 Nginx主要用来做七层负载均衡。 HAProxy HAProxy是一个使用C语言编写的自由及开放源代码软件,其提供高可用性、负载均衡,以及基于TCP和HTTP的应用程序代理。 Haproxy主要用来做七层负载均衡。 常见负载均衡算法 上面介绍负载均衡技术的时候提到过,负载均衡服务器在决定将请求转发到具体哪台真实服务器的时候,是通过负载均衡算法来实现的。负载均衡算法可以分为两类:静态负载均衡算法和动态负载均衡算法。 静态负载均衡算法包括:轮询,比率,优先权 动态负载均衡算法包括: 最少连接数,最快响应速度,观察方法,预测法,动态性能分配,动态服务器补充,服务质量,服务类型,规则模式。 轮询(Round Robin):顺序循环将请求一次顺序循环地连接每个服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从顺序循环队列中拿出,不参加下一次的轮询,直到其恢复正常。 比率(Ratio):给每个服务器分配一个加权值为比例,根椐这个比例,把用户的请求分配到每个服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从服务器队列中拿出,不参加下一次的用户请求的分配, 直到其恢复正常。 优先权(Priority):给所有服务器分组,给每个组定义优先权,BIG-IP 用户的请求,分配给优先级最高的服务器组(在同一组内,采用轮询或比率算法,分配用户的请求);当最高优先级中所有服务器出现故障,BIG-IP 才将请求送给次优先级的服务器组。这种方式,实际为用户提供一种热备份的方式。 最少的连接方式(Least Connection):传递新的连接给那些进行最少连接处理的服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从服务器队列中拿出,不参加下一次的用户请求的分配, 直到其恢复正常。 最快模式(Fastest):传递连接给那些响应最快的服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP 就把其从服务器队列中拿出,不参加下一次的用户请求的分配,直到其恢复正常。 观察模式(Observed):连接数目和响应时间以这两项的最佳平衡为依据为新的请求选择服务器。当其中某个服务器发生第二到第7 层的故障,BIG-IP就把其从服务器队列中拿出,不参加下一次的用户请求的分配,直到其恢复正常。 预测模式(Predictive):BIG-IP利用收集到的服务器当前的性能指标,进行预测分析,选择一台服务器在下一个时间片内,其性能将达到最佳的服务器相应用户的请求。(被BIG-IP 进行检测) 动态性能分配(Dynamic Ratio-APM):BIG-IP 收集到的应用程序和应用服务器的各项性能参数,动态调整流量分配。动态服务器补充(Dynamic Server Act.):当主服务器群中因故障导致数量减少时,动态地将备份服务器补充至主服务器群。 服务质量(QoS):按不同的优先级对数据流进行分配。 服务类型(ToS): 按不同的服务类型(在Type of Field中标识)负载均衡对数据流进行分配。 规则模式:针对不同的数据流设置导向规则,用户可自行。 参考资料 几种负载均衡算法
-
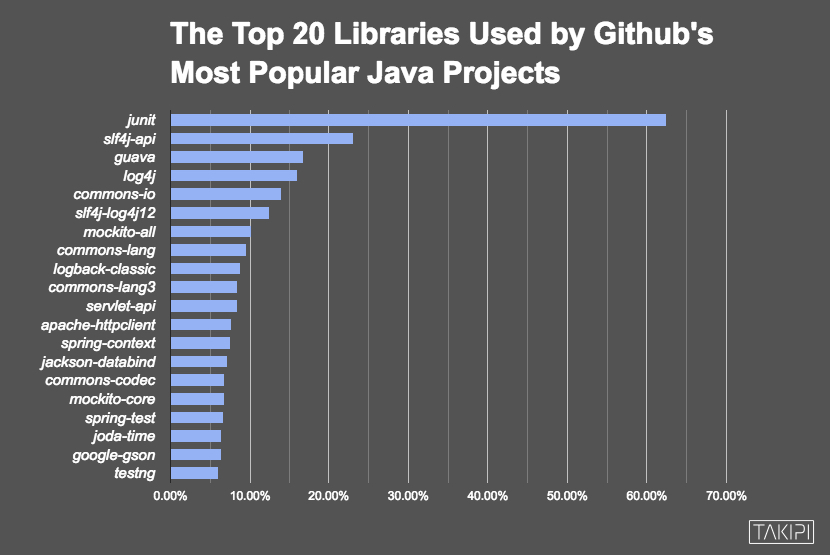
2016年排名Top 100的Java类库——在分析了47,251个依赖之后得出的结论 本文由HollisChuang 翻译自 The Top 100 Java Libraries in 2016 – After Analyzing 47,251 Dependencies . 原作者:Henn Idan 我们分析了GitHub中47,251个依赖,从中找出了排名前一百的Java类库,让我们看看谁在前面,谁在后面。 我们在漫长的周末的消遣方式就是浏览GitHub并且搜索流行的Java类库。我们决定把其中的乐趣与结果分享给你。 我们分析了GitHub中排名前3,862个项目中的47,251个导入语句,其中有12,059个Java类库被依赖。我们从这个列表中提取出前一百并把结果分享给你。 最受欢迎的前20个Java类库 和上次分析结果一致,junit依旧是GitHub中最受欢迎的类库。Java中的日志API slf4j排名第二,log4j排名第四。 Google的开源类库Guava呈上升趋势,排名第三(去年排名第四)。Guava中包含一系列诞生在谷歌内部的核心Java类库。如果你不了解Guava或者你不知道如何使用它,你可以阅读Google Guava: 5 Things You Never Knew It Could Do Spring类库的崛起 Spring框架作为Java EE的主要竞争对手在Java社区很流行,这一点也在GitHub中很好的提现了出来。在排名一百名以外,有44个类库是与Spring相关的。最有趣的部分是Spring Boot的迅速崛起,关于这部分内容可以阅读Java Bootstrap: Dropwizard vs. Spring Boot. 排名靠前的Spring类库: #13 – springframework.spring-context #17 – springframework.spring-test #22 – springframework.spring-webmvc #24 – springframework.spring-core #27 – springframework.spring-web #36 – springframework.spring-jdbc #37 – springframework.spring-orm #38 – springframework.spring-tx #40 – springframework.spring-aop #47 – springframework.spring-context-support #72 – springframework.boot.spring-boot-starter-web #81 – springframework.security.spring-security-web #82 – springframework.security.spring-security-config #88 – springframework.boot.spring-boot-starter-test #99 – springframework.security.spring-security-core 最受欢迎的JSON类库 因为Java本身还不支持JSON(尽管Java9宣称支持),所以我们想通过GitHub中的项目来看看这些JSON类库的受欢迎程度。 你不能通过他的使用量多少来选择一个使用哪个类库,因为这些JSON框架的功能不尽相同。而是应该根据实际使用环境选择最适合的。如果你不知道如何选择,可以参考JSON benchmark. 排名靠前的JSON类库: #14 – fasterxml.jackson.core.jackson-databind #19 – google.code.gson.gson #43 – json.json #80 – googlecode.json-simple.json-simple #89 – thoughtworks.xstream.xstream 神奇四侠 有很多有趣的新库,甚至引起了我们的注意,但我们决定关注以下他们: #68 – projectlombok.lombok – Lombok提供了简单的注解的形式来帮助我们消除一些必须有但显得很臃肿的Java样板代码。 #90 – jsoup.jsoup – jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。 #92 – io.netty.netty-all – 网络应用程序框架,用于快速和方便的开发维护高性能协议服务器和客户端 #98 –dom4j.dom4j – 处理XML的开源框架。它集成了XPath并提供全力支持DOM,JAXP和Java平台。 前100个类库的类型 魔术背后的科学(我们是如何得出这份列表的) 你可能想知道我们是如何得出这些信息的。我们首先按照star数量把GitHub中的项目代码pull到本地。我们提取并分析了使用了Maven和Ivy的项目中用于依赖管理的 pom.xml / ivy.xml ,这给我们提供了47,251分数据来源。 我们做了一些疯狂的挖掘和分析,最终我们得到GitHub中排名前3,862项目中的12,059个Java类库。这样就可以很方便的对他们进行排名了,只要按照他们出现的次数排序就可以了。 如果你想看看我们的原始数据,这个文件可以。虽然这篇文章中我们已经介绍的比较清楚了,我们仍然欢迎你来看看,确保我们没有错过任何有趣的见解。 最后的一点想法 当我们拿着这份列表与去年的结果做对比的时候,我们发现一些小的类库的排名有一些小的波动,Spring有明显上升,而MongoDB消失在名单中。 如果你已经对类库有了选择,但你仍然寻找最终的工具,我们有一个完美的建议给你。 Top 15 Tools Java Developers Use After Major Releases
-
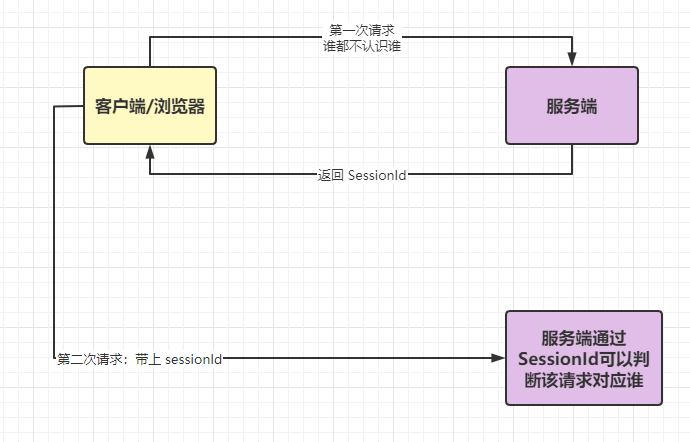
session、token、jwt、oauth2 傻傻分不清 在我们的 java 业务系统中,或多或少的会涉及到权限、认证等类似的概念。但是很多小伙伴还是傻傻的分不清这些的概念和区别,今天我们就来好好的捋一捋,将其区别的概念深深的刻在脑海中。 认证 Authentication 百度百科中对于认证的解释是:身份验证(Authentication),在 .NET Framework 安全中,通过对照某些机构检查用户的凭据,发现和验证主体标识的过程。 当然,今天我们来讨论肯定不会用这么生硬的词来解释的。 通俗地讲就是 验证当前用户的身份,证明“你是你自己”(比如:你每天上下班打卡,都需要通过指纹打卡,当你的指纹和系统里录入的指纹相匹配时,就打卡成功) 常见的认证方式: 用户名密码登录 邮箱发送登录链接 手机号接收验证码 只要你能收到邮箱/验证码,就默认你是账号的主人 授权 Authorization 所谓授权,就是某个用户授予其他应用访问该用户某些资源的权限。 例如,在你安装手机应用的时候,APP肯定会跳出来问是否允许授予权限(访问相册、位置等权限);你在访问微信小程序时,当登录时,小程序会询问是否允许授予权限(获取昵称、头像、地区、性别等个人信息) 实现授权的方式有:cookie、session、token、OAuth 凭证 Credentials 实现认证和授权的前提是需要一种媒介(证书) 来标记访问者的身份。 这个其实很好理解,身份证大家肯定是都有的。过身份证,我们可以办理手机卡/银行卡/个人贷款/交通出行等等,这就是认证的凭证。 在互联网应用中,一般网站会有两种模式,游客模式和登录模式。 游客模式下,可以正常浏览网站上面的文章,一旦想要点赞/收藏/分享文章,就需要登录或者注册账号。 登录模式,当用户登录成功后,服务器会给该用户使用的浏览器颁发一个令牌(token),这个令牌用来表明你的身份,每次浏览器发送请求时会带上这个令牌,就可以使用游客模式下无法使用的功能。 Cookie HTTP 是无状态的协议(对于事务处理没有记忆能力,每次客户端和服务端会话完成时,服务端不会保存任何会话信息):每个请求都是完全独立的,服务端无法确认当前访问者的身份信息,无法分辨上一次的请求发送者和这一次的发送者是不是同一个人。 所以服务器与浏览器为了进行会话跟踪(知道是谁在访问我),就必须主动的去维护一个状态,这个状态用于告知服务端前后两个请求是否来自同一浏览器。而这个状态需要通过 cookie 或者 session 去实现。 cookie 存储在客户端: cookie 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。 cookie 是不可跨域的: 每个 cookie 都会绑定单一的域名,无法在别的域名下获取使用,一级域名和二级域名之间是允许共享使用的(靠的是 domain)。 Session session 是另外一种记录服务器和客户端会话状态的机制,通常情况下,session 是基于 cookie 实现的,session 存储在服务器端,sessionId 会被存储到客户端的cookie 中 session 认证流程: 用户第一次请求服务器的时候,服务器根据用户提交的相关信息,创建对应的 Session 请求返回时将此 Session 的唯一标识信息 SessionID 返回给浏览器 浏览器接收到服务器返回的 SessionID 信息后,会将此信息存入到 Cookie 中,同时 Cookie 记录此 SessionID 属于哪个域名 当用户第二次访问服务器的时候,请求会自动判断此域名下是否存在 Cookie 信息,如果存在自动将 Cookie 信息也发送给服务端,服务端会从 Cookie 中获取 SessionID,再根据 SessionID 查找对应的 Session 信息,如果没有找到说明用户没有登录或者登录失效,如果找到 Session 证明用户已经登录可执行后面操作。 目前,大部分系统都是根据此原理来验证用户的登录状态的。 Cookie 和 Session 的区别 这个应该是面试中问的频率非常高的一个问题了。 安全性: Session 比 Cookie 安全,Session 是存储在服务器端的,Cookie 是存储在客户端的。 存取值的类型不同:Cookie 只支持存字符串数据,想要设置其他类型的数据,需要将其转换成字符串,Session 可以存任意数据类型。 有效期不同: Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般失效时间较短,客户端关闭(默认情况下)或者 Session 超时都会失效。 存储大小不同: 单个 Cookie 保存的数据不能超过 4K,Session 可存储数据远高于 Cookie,但是当访问量过多,会占用过多的服务器资源。 令牌 Token Acesss Token 访问资源接口(API)时所需要的资源凭证,简单 token 的组成: uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,token 的前几位以哈希算法压缩成的一定长度的十六进制字符串) Acesss Token的特点是 * 服务端无状态化、可扩展性好 * 支持移动端设备 * 安全 * 支持跨程序调用 token 的身份验证流程如下: 客户端使用用户名跟密码请求登录 服务端收到请求,去验证用户名与密码 验证成功后,服务端会签发一个 token 并把这个 token 发送给客户端 客户端收到 token 以后,会把它存储起来,比如放在 cookie 里或者 localStorage 里 客户端每次向服务端请求资源的时候需要带着服务端签发的 token 服务端收到请求,然后去验证客户端请求里面带着的 token ,如果验证成功,就向客户端返回请求的数据 Refresh Token refresh token 是专用于刷新 access token 的 token。 如果没有 refresh token,也可以刷新 access token,但每次刷新都要用户输入登录用户名与密码,会很麻烦。有了 refresh token,可以减少这个麻烦,客户端直接用 refresh token 去更新 access token,无需用户进行额外的操作。 Access Token 的有效期比较短,当 Acesss Token 由于过期而失效时,使用 Refresh Token 就可以获取到新的 Token,如果 Refresh Token 也失效了,用户就只能重新登录了。 Refresh Token 及过期时间是存储在服务器的数据库中,只有在申请新的 Acesss Token 时才会验证,不会对业务接口响应时间造成影响,也不需要向 Session 一样一直保持在内存中以应对大量的请求。 Token 和 Session 的区别 Session 是一种记录服务器和客户端会话状态的机制,使服务端有状态化,可以记录会话信息。而 Token 是令牌,访问资源接口(API)时所需要的资源凭证。Token 使服务端无状态化,不会存储会话信息。 Session 和 Token 并不矛盾,作为身份认证 Token 安全性比 Session 好,因为每一个请求都有签名还能防止监听以及重放攻击,而 Session 就必须依赖链路层来保障通讯安全了。如果你需要实现有状态的会话,仍然可以增加 Session 来在服务器端保存一些状态。 所谓 Session 认证只是简单的把 User 信息存储到 Session 里,因为 SessionID 的不可预测性,暂且认为是安全的。而 Token ,如果指的是 OAuth Token 或类似的机制的话,提供的是 认证 和 授权 ,认证是针对用户,授权是针对 App 。其目的是让某 App 有权利访问某用户的信息。这里的 Token 是唯一的。不可以转移到其它 App上,也不可以转到其它用户上。Session 只提供一种简单的认证,即只要有此 SessionID ,即认为有此 User 的全部权利。是需要严格保密的,这个数据应该只保存在站方,不应该共享给其它网站或者第三方 App。 所以简单来说:如果你的用户数据可能需要和第三方共享,或者允许第三方调用 API 接口,用 Token 。如果永远只是自己的网站,自己的 App,用什么就无所谓了。 JWT(JSON Web Token) JSON Web Token(简称 JWT)是目前最流行的跨域认证解决方案 JWT 是为了在网络应用环境间传递声明而执行的一种基于 JSON 的开放标准(RFC 7519)。JWT 的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源。比如用在用户登录上。 可以使用 HMAC 算法或者是 RSA 的公/私秘钥对 JWT 进行签名。因为数字签名的存在,这些传递的信息是可信的。 JWT 认证流程: 用户输入用户名/密码登录,服务端认证成功后,会返回给客户端一个 JWT 客户端将 token 保存到本地(通常使用 localstorage,也可以使用 cookie) 当用户希望访问一个受保护的路由或者资源的时候,需要请求头的 Authorization 字段中使用Bearer 模式添加 JWT,其内容看起来是下面这样
-
服务器性能指标(二)——CPU利用率分析及问题排查 平常的工作中,在衡量服务器的性能时,经常会涉及到几个指标,load、cpu、mem、qps、rt等。每个指标都有其独特的意义,很多时候在线上出现问题时,往往会伴随着某些指标的异常。大部分情况下,在问题发生之前,某些指标就会提前有异常显示。 在上一篇文章中,我们介绍了一个重要的指标就是负载(Load),其中我们提到Linux的负载高,主要是由于CPU使用、内存使用、IO消耗三部分构成。任意一项使用过多,都将导致服务器负载的急剧攀升。本文就来分析其中的第二项,CPU的利用率。主要涉及CPU利用率的定义、查看CPU利用率方式、CPU利用率飙高排查思路等。 什么是CPU利用率 CPU利用率,又称CPU使用率。顾名思义,CPU利用率是来描述CPU的使用情况的,表明了一段时间内CPU被占用的情况。使用率越高,说明你的机器在这个时间上运行了很多程序,反之较少。使用率的高低与你的CPU强弱有直接关系。 在接下来深入介绍CPU的利用率之前,我们先来解释一个简单的概念,可能是很多人一直存在误解的地方。 很多人都知道,现在我们用到操作系统,无论是Windows、Linux还是MacOS等其实都是多用户多任务分时操作系统。使用这些操作系统的用户是可以“同时”干多件事的,这已经是日常习惯了,并没觉得有什么特别。 但是实际上,对于单CPU的计算机来说,在CPU中,同一时间是只能干一件事儿的。为了看起来像是“同时干多件事”,分时操作系统是把CPU的时间划分成长短基本相同的时间区间,即”时间片”,通过操作系统的管理,把这些时间片依次轮流地分配给各个用户使用。 如果某个作业在时间片结束之前,整个任务还没有完成,那么该作业就被暂停下来,放弃CPU,等待下一轮循环再继续做.此时CPU又分配给另一个作业去使用。 由于计算机的处理速度很快,只要时间片的间隔取得适当,那么一个用户作业从用完分配给它的一个时间片到获得下一个CPU时间片,中间有所”停顿”,但用户察觉不出来,好像整个系统全由它”独占”似的。 而我们说到的CPU的占用率,一般指的就是对时间片的占用情况。 查看CPU利用率 在上一篇文章中,我们介绍过,使用uptime、top、w等命令可以在Linux查看系统的负载情况。其中,top命令也可以用来查看CPU的利用率,除此之外,还可以使用vmstat来查看cpu的利用率。 vmstat命令 vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。 ~ vmstat procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 1 0 2446260 0 3202312 0 0 201 16304 1 6 0 0 84 5 1 从上面的结果中我们可以看到很多信息,我们本文重点关注下cpu部分的指标。 us sy id wa st 0 0 84 5 1 以上几个指标是当前CPU的占用情况。 %us:用户进程执行时间百分比 us的值比较高时,说明用户进程消耗的CPU时间多,但是如果长期超50%的使用,那么我们就该考虑优化程序算法或者进行加速。 %sy:内核系统进程执行时间百分比 sy的值高时,说明系统内核消耗的CPU资源多,这并不是良性表现,我们应该检查原因。 %id:空闲时间百分比 %wa:IO等待时间百分比 wa的值高时,说明IO等待比较严重,这可能由于磁盘大量作随机访问造成,也有可能磁盘出现瓶颈(块操作)。 %st:虚拟 CPU 等待实际 CPU 的时间的百分比 一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数 ~ vmstat 2 2 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 2479444 0 3165172 0 0 196 15905 2 8 0 0 84 5 11 0 0 0 2479404 0 3165176 0 0 0 2804 81664 2715 0 0 90 1 9 以上命令表示采集两次数据,每隔2秒采集一次。 top命令 top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。 ~ top top - 10:58:07 up 18:13, 1 user, load average: 0.32, 0.24, 0.19 Tasks: 64 total, 1 running, 63 sleeping, 0 stopped, 0 zombie Cpu(s): 0.1%us, 0.2%sy, 0.0%ni, 92.8%id, 0.1%wa, 0.0%hi, 0.0%si, 6.8%st Mem: 8388608k total, 5928076k used, 2460532k free, 0k buffers Swap: 16777216k total, 0k used, 16777216k free, 3181996k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 2393 admin 20 0 5056m 2.2g 56m S 4.3 27.6 79:06.21 java 1054 root 20 0 338m 9760 5112 S 0.3 0.1 2:37.30 logagent 使用top命令,除了可以查看Load Avg以外,还可以显示CPU利用率信息。 以上top命令打印的信息中(Cpu(s): 0.1%us, 0.2%sy, 0.0%ni, 92.8%id, 0.1%wa, 0.0%hi, 0.0%si, 6.8%st),第三行反映了当前cpu的整体情况。 从上面的打印信息中我们还可以看到,ID为2393的java进程当前内存使用率最高,占到4.3%左右。 由于Java是多线程的,所有,有些时候我们希望可以查看一个Java进程中所有线程的cpu使用率如何,也可以使用top命令来查看。 ~ top -Hp 1893 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 19163 admin 20 0 5056m 2.2g 56m S 1.7 27.6 17:39.97 java 10649 admin 20 0 5056m 2.2g 56m S 0.7 27.6 4:07.64 java 5884 admin 20 0 5056m 2.2g 56m S 0.3 27.6 2:18.19 java 10650 admin 20 0 5056m 2.2g 56m S 0.3 27.6 1:24.77 java 通过top -Hp 1893命令,我们可以发现,当前1893这个进程中,ID为19163的线程占用CPU最高,达到1.7%左右。 PS:top命令的输出结果是动态的,随着系统的情况实时变化的。 CPU使用率的计算逻辑 描述系统cpu使用情况主要有一下几点: user 从系统启动到现在,CPU处于用户态的运行时间。不包含nice值为负的进程。 nice 从系统启动到现在,CPUnice为负值的进程占用的cpu时间 system 从系统启动到现在,CPU处于内核态的运行时间 idle 从系统启动到现在,CPU除了 iowait外的等待时间 iowait 从系统启动到现在,CPUio 等待时间 irq 从系统启动到现在,CPU硬中断花费的时间 softirq 从系统启动到现在,CPU软中断花费的时间 steal 从系统启动到现在,CPU运行其他虚拟环境中的操作系统花费的时间 guest 从系统启动到现在,CPU运行在通过Linux内核控制的客户操作系统上的虚拟cpu的时间 guest_nice 从系统启动到现在,CPU运行在通过Linux内核控制的客户操作系统上的虚拟cpu的时间, nice 为负值进程 知道了以上参数的意思,计算某段时间内的cpu使用率就不难,由于cpu资源是在高速的变化,于是计算cpu使用率只能是在一段时间内的,设置两个时间点为t1和t2, CPU在t1和t2时间内总的使用时间: ( user2+ nice2+ system2+ idle2+ iowait2+ irq2+ softirq2 + steal2 + guest2 + guest_nice2 ) - ( user1+ nice1+ system1+ idle1+ iowait1+ irq1+ softirq1 + steal1 + guest1 + guest_nice1) CPU的空闲时间: (idle2 -idle1) CPU在t1和t2时间内的使用率 CPU非空闲时间/CPU总时间*100%=(1-CPU的空闲时间/CPU总时间)*100% 则: CPU(t1,t2)使用率:1-(idle2-idle1)/(( user2+ nice2+ system2+ idle2+ iowait2+ irq2+ softirq2 + steal2 + guest2 + guest_nice2 ) - ( user1+ nice1+ system1+ idle1+ iowait1+ irq1+ softirq1 + steal1 + guest1 + guest_nice1)) (参考资料:https://blog.csdn.net/IT_DREAM_ER/article/details/52037368) CPU利用率和负载 我们上一篇文章介绍了系统的负载,本文介绍了CPU利用率,很多小伙伴就会分不清楚了,这两者之前到底有什么区别和联系呢? CPU利用率是对一个时间段内CPU使用状况的统计,通过这个指标可以看出在某一个时间段内CPU被占用的情况。 CPU的Load是在一段时间内CPU正在处理以及等待CPU处理的进程数之和的统计信息,也就是CPU使用队列的长度的统计信息。 有一个很好的比喻,就是把CPU的使用比喻成排队打电话: 我们将CPU就类比为电话亭,每一个进程都是一个需要打电话的人。现在有一个电话亭(单核计算机),有10个人需要打电话(10个进程)。现在使用电话的规则是管理员会按照顺序给每一个人轮流分配1分钟的使用电话时间,如果使用者在1分钟内使用完毕,那么可以将电话使用权返还给管理员,如果到了1分钟电话使用者还没有使用完毕,那么需要重新排队,等待再次分配使用。在电话亭使用过程中,肯定会有人打完电话走掉,有人没有打完电话而选择重新排队,同样也会有新来的人继续排队,这个人数的变化就相当于任务数的增减。 CPU的Load统计一定时间段内,所有使用电话的人加上等待电话分配的人数的平均值。为了统计平均负载情况,我们5分钟统计一次人数,并在第1、5、15分钟的时候对统计情况取平均值,从而形成第1、5、15分钟的平均负载。 CPU利用率统计的进程在进入电话亭后,真正使用电话的时间和在电话亭停留的时间的比值。例如一个用户得到了一分钟的使用权,在10秒钟内打了电话,然后去查询号码本花了20秒钟,再用剩下的30秒打了另一个电话。那么他的利用率就是(10+30)/60 Java Web应用CPU使用率飙高排查思路 当发现系统的CPU使用率飙高时,首先要定位到是哪个进程占用的CPU较高。一般情况下,对于Java代码来说,导致CPU飙高可能由以下几个原因引起: 1、内存泄露、导致大量Full GC(如典型的Java 1.7之前的String.subString导致的内存泄露问题) 2、代码存在死循环(如典型的多线程场景使用HashMap导致死循环的问题) 这部分问题排查思路其实和我上一篇问文章的思路差不多,基本都是先定位到占用CPU较多的进程和线程,然后通过命令在查看这条线程执行情况。通过分析代码来定位其中的问题。 这里就不重复介绍了,最重要的是熟练的使用jstack、jstat以及jmap等命令来定位及解决Java进程的问题。
-
服务器性能指标(三)——内存使用分析及问题排查 平常的工作中,在衡量服务器的性能时,经常会涉及到几个指标,load、cpu、mem、qps、rt等。每个指标都有其独特的意义,很多时候在线上出现问题时,往往会伴随着某些指标的异常。大部分情况下,在问题发生之前,某些指标就会提前有异常显示。 在第一篇文章中,我们介绍了一个重要的指标就是负载(Load),其中我们提到Linux的负载高,主要是由于CPU使用、内存使用、IO消耗三部分构成。任意一项使用过多,都将导致服务器负载的急剧攀升。本文就来分析其中的第二项,内存使用。 什么是内存 内存是计算机中重要的部件之一,它是与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大。 内存(Memory)也被称为内存储器,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。 物理内存 物理内存指通过物理内存条而获得的内存空间。即随机存取存储器(random access memory,RAM),是与CPU直接交换数据的内部存储器,也叫主存(内存)。 虚拟内存 虚拟内存是计算机系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换(也就是说,当物理内存不足时,可能会借用硬盘空间来充当内存使用)。与没有使用虚拟内存技术的系统相比,使用这种技术的系统使得大型程序的编写变得更容易,对真正的物理内存(例如RAM)的使用也更有效率。 Swap分区 Swap分区(即交换区)在系统的物理内存不够用的时候,把硬盘空间中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间被临时保存到Swap分区中,等到那些程序要运行时,再从Swap分区中恢复保存的数据到内存中。 程序运行时的数据加载,线程并发,I/O缓冲等等,都依赖于内存,可用内存的大小,决定了程序是否能正常运行以及运行的性能。 查看内存使用情况 在Linux机器上,有多个命令都可以查看机器的内存信息。其中包括free、top等。 free命令 free命令可以显示Linux系统中空闲的、已用的物理内存,swap分区以及被内核缓冲区内存。在Linux系统监控的工具中,free命令是最经常使用的命令之一。 $free total used free shared buffers cached Mem: 8388608 2926968 5461640 0 0 1654392 -/+ buffers/cache: 1272576 7116032 Swap: 16777208 0 16777208 上图中,一共有3行6列数据,行数据的意义如下: Mem 行是内存的使用情况。 -/+ buffers/cache 行是物理内存的缓存统计情况。 Swap 行是交换空间的使用情况。 前面分别介绍过了物理内存和Swap分区。这里再介绍一下buffers和cache。 buffer与cache的区别 A buffer is something that has yet to be “written” to disk. A cache is something that has been “read” from the disk and stored for later use. 简单点说: buffers 就是存放要输出到disk(块设备)的数据,缓冲满了一次写,提高IO性能(内存 -> 磁盘) cached 就是存放从disk上读出的数据,常用的缓存起来,减少IO(磁盘 -> 内存) buffer 和 cache,两者都是RAM中的数据。简单来说,buffer是即将要被写入磁盘的,cache是被从磁盘中读出来的。 介绍完了buffer和cache的区别,接下来分析下free命令查询到的数据。 Mem行 total used free shared buffers cached Mem: 8388608 2926968 5461640 0 0 1654392 这一行展示物理内存的整体情况。 Total:8388608。表示物理内存总大小。 Used :2926968。表示总计分配给缓存(包含buffers 与cache )使用的数量,但其中可能部分缓存并未实际使用。 Free :5461640。表示未被分配的内存。 Shared:0。共享内存,一般系统不会用到。 Buffers:0。系统分配但未被使用的buffers 数量。 Cached:1654392。系统分配但未被使用的cache 数量。 total(Mem) = used(Mem) + free(Mem) -/+ buffers/cache 行 total used free shared buffers cached -/+ buffers/cache: 1272576 7116032 Used:1272576。 表示实际使用的buffers 与cache 总量,也是实际使用的内存总量。 Free:7116032。 未被使用的buffers 与cache 和未被分配的内存之和,这就是系统当前实际可用内存。 used(-/+ buffers/cache) = used(Mem) – cached(Mem) – buffers(Mem) free(-/+ buffers/cache) = free(Mem) + cached (Mem)+ buffers(Mem) Swap 行 $free total used free shared buffers cached Swap: 16777208 0 16777208 Total:16777208。Swap内存总大小。 Used:0。表示已分配的Swap大小。 Free:16777208。表示未被分配的内存。 接下来,再来整体看一下数据。 $free total used free shared buffers cached Mem: 8388608 2926968 5461640 0 0 1654392 -/+ buffers/cache: 1272576 7116032 Swap: 16777208 0 16777208 机器上实际可用内存大小: Free(-/+ buffers/cache)= Free(Mem)+buffers(Mem)+Cached(Mem); 7116032 = 5461640 + 0+ 1654392 已经分配的内存大小: Used(Mem) = Used(-/+ buffers/cache)+ buffers(Mem) + Cached(Mem) 2926968 = 1272576 + 0 + 1654392 物理内存总大小 total(Mem) = used(-/+ buffers/cache) + free(-/+ buffers/cache) 8388608 = 1272576 + 7116032 总结一下,整个机器的总内存大小8388608,其中已经分配的内存有2926968,还未分配的内存有5461640。而分配的2926968中,有1654392还没有使用,有1272576已经用掉了。当前机器中还有7116032内存可以使用。 free命令参数 -m 以M为单位显示内存 $free -m total used free shared buffers cached Mem: 8192 2802 5389 0 0 1559 -/+ buffers/cache: 1243 6948 Swap: 16383 0 16383 -g 以G为单位显示内存 $free -g total used free shared buffers cached Mem: 8 2 5 0 0 1 -/+ buffers/cache: 1 6 Swap: 16 0 16 -s 2持续的观察内存的状况,每隔2秒打印一次 $free -s 2 total used free shared buffers cached Mem: 8388608 2873128 5515480 0 0 1600588 -/+ buffers/cache: 1272540 7116068 Swap: 16777208 0 16777208 total used free shared buffers cached Mem: 8388608 2873168 5515440 0 0 1600628 -/+ buffers/cache: 1272540 7116068 Swap: 16777208 0 16777208 除了free ,还可以在Linux下可以使用/proc/meminfo文件查看操作系统内存的使用状态,其实,free命令的内容也是来自于/proc/meminfo文件。 top命令 top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。 在前面两篇文章中介绍过使用top命令查看Load Avg和CPU利用率。top还会打印的一部分信息就是内存情况。 top - 17:49:32 up 2 days, 6:25, 1 user, load average: 0.01, 0.09, 0.12 Tasks: 30 total, 1 running, 29 sleeping, 0 stopped, 0 zombie Cpu(s): 0.1%us, 0.0%sy, 0.0%ni, 88.0%id, 3.8%wa, 0.0%hi, 0.0%si, 8.1%st Mem: 8388608k total, 2884716k used, 5503892k free, 0k buffers Swap: 16777208k total, 0k used, 16777208k free, 1612080k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 85690 admin 20 0 5138m 1.1g 47m S 2.3 13.9 93:28.92 java 上面的Mem行和Swap行展示的就是内存的使用情况。并且也会按照进行展示不同进程的内存占用情况。十分好用。 Java Web应用内存占用飙高排查思路 JVM以一个进程(Process)的身份运行在Linux系统上,对于Linux来说,JVM不过是一个具有自助管理内存的乖孩子而已。 一般在应用启动时都可以通过JVM参数来设置JVM内存的大小。如果超过这个限制就会抛出异常。所以,我们比较常见的内存占用过高问题,最显著的现象就是抛出各种OutOfMemoryError。 有一种可能导致直接内存,也就是Linux的物理内存过高的情况,就是NIO的使用。NIO引入了一种基于通道与缓冲区的IO方式,他可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆中的DirectByteBuffer对象作为这块内存的引用进行操作。 所以,在使用NIO的时候,要特别小心,避免导致机器内存被挤满。 导致JVM中内存占用飙高的原因可能有很多。最常见的就是内存泄露。 内存泄露排查思路 1、使用top命令,查看占用内存较高的进程ID。 ~ top PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3331 admin 20 0 7127m 2.6g 38m S 10.7 90.6 10:20.26 java 发现PID为3331的进程占用内存 90.6%。而且是一个Java进程,基本断定是程序问题。 2、使用jmap查看内存情况,并分析是否存在内存泄露。 jmap -heap 3331:查看java 堆(heap)使用情况 jmap -histo 3331:查看堆内存(histogram)中的对象数量及大小 jmap -histo:live 3331:JVM会先触发gc,然后再统计信息 jmap -dump:format=b,file=heapDump 3331:将内存使用的详细情况输出到文件 得到堆dump文件后,可以进行对象分析。如果有大量对象在持续被引用,并没有被释放掉,那就产生了内存泄露,就要结合代码,把不用的对象释放掉。 参考资料 Linux 内存 buffer 和 cache 的区别