找到
11
篇与
综合应用
相关的结果
- 第 2 页
-
 Java开发常用的在线工具 作为一个Java开发人员,经常要和各种各样的工具打交道,除了我们常用的IDE工具以外,其实还有很多工具是我们在日常开发及学习过程中要经常使用到的。博主偏爱使用在线工具,因为个人觉得这样比较方便。本文就总结了一下我常用的在线工具。欢迎纠正及补充。 我会在我的个人博客(http://www.hollischuang.com)中单独创建一个常用工具页面,把这些工具的链接放到里面,我会持续更新这个页面。不爱保存书签的同学可以直接保存我的页面。 后面我会在有时间的时候做个浏览器书签或者chrome插件。 Java源代码搜索 Grepcode是一个面向于Java开发人员的网站,在这里你可以通过Java的projects、classes等各种关键字在线查看它对应的源码,知道对应的project、classes等信息。 更方便的是,能提供非常多不同版本的源码在线查看、jar包、源码jar包、doc的下载。 同样,你也可以之间使用xxx-1.1.1.jar类似这样的名字直接找到对应的jar包,从而下载。 开源代码及文档搜索 SearchCode 是一个源码搜索引擎,目前支持从 Github、Bitbucket、Google Code、CodePlex、SourceForge 和 Fedora Project 平台搜索公开的源码。 在线UML制图 ProcessOn是一个在线协作绘图平台,为用户提供最强大、易用的作图工具!支持在线创作流程图、BPMN、UML图、UI界面原型设计、iOS界面原型设计等。 Json在线验证及格式化 我用过很多json在线格式化的工具,经过实践,json.cn是比较不错的,不仅支持json格式的验证及格式化,还可以将json格式压缩成普通文本等好用功能。 Diff Check 使用过svn或者git的人对diffcheck肯定不陌生,但有时候我们修改的文本内容并没有被版本控制,那么就可以使用在线的网站查看文件的修改情况。https://www.diffchecker.com/很不错。 MarkDown编辑器 MaHua马克飞象Cmd 以上这几个我都用过,都还好吧,因为我一般都喜欢把自己写过的东西保存下来,所以就用了客户端的,我是用的是MacDown Maven依赖查询 mvnrepository这个不用详细解释了,就是查询maven的gav信息一类的。因为我们公司有内部的Nexus仓库,所以很少用这个。 在线代码运行 http://tool.lu/coderunner/可以在线运行php,c,c++,go,python,java,groovy等代码。基本是很少使用。 在线翻译 Google翻译 百度翻译 有道翻译 爱词霸翻译 说不出具体哪个好,其实都不太准确,还是需要自己根据语境进行翻译。 不过忍不住吐槽一句国内的这几个翻译网站,既然是做翻译的,域名竟然用拼音,我也是醉了。 SQL自动生成Java代码 AutoJCode可以从sql的建表语句中生成一个DO类。 json生成java类 http://www.bejson.com/json2javapojo/ SQL美化/格式化/压缩 sql在线美化,格式化,压缩 编码转换 站长工具的编码转换比较全面,提供了Unicode编码、UFT8编码、URL编码/解码等功能。 Corn表达式生成 Cron一般用于配置定时任务的执行。没有什么特别好的网站,http://www.pdtools.net/tools/becron.jsp还可以吧,基本可以满足需求。 正则验证 Java开发对正则表达式肯定不陌生。站长工具提供的正则验证还不错。 正则代码生成 站长工具提供的正则代码生成。 时间戳转换 时间戳(英语:Timestamp)是指在一连串的资料中加入辨识文字,如时间或日期,用以保障本地端(local)资料更新顺序与远端(remote)一致。 站长工具提供的时间戳转换。 世界时间转换 世界各地时间转换,我比较常用的是北京时间转纽约时间,北京时间转洛杉矶时间。 timebie提供了世界时间相互转换的功能。 加密解密 站长工具中的加密解密 查看网页源代码 查看网页源代码 单位换算 convertworld是一个比较全的单位换算的网站。我经常用它进行时间单位和货币单位的换算。 在线调色板 在线调色板 常用对照表 ASCII对照表 HTTP状态码 HTTP Content-type TCP/UDP常见端口参考 HTML转义字符 RGB颜色参考 欢迎补充~
Java开发常用的在线工具 作为一个Java开发人员,经常要和各种各样的工具打交道,除了我们常用的IDE工具以外,其实还有很多工具是我们在日常开发及学习过程中要经常使用到的。博主偏爱使用在线工具,因为个人觉得这样比较方便。本文就总结了一下我常用的在线工具。欢迎纠正及补充。 我会在我的个人博客(http://www.hollischuang.com)中单独创建一个常用工具页面,把这些工具的链接放到里面,我会持续更新这个页面。不爱保存书签的同学可以直接保存我的页面。 后面我会在有时间的时候做个浏览器书签或者chrome插件。 Java源代码搜索 Grepcode是一个面向于Java开发人员的网站,在这里你可以通过Java的projects、classes等各种关键字在线查看它对应的源码,知道对应的project、classes等信息。 更方便的是,能提供非常多不同版本的源码在线查看、jar包、源码jar包、doc的下载。 同样,你也可以之间使用xxx-1.1.1.jar类似这样的名字直接找到对应的jar包,从而下载。 开源代码及文档搜索 SearchCode 是一个源码搜索引擎,目前支持从 Github、Bitbucket、Google Code、CodePlex、SourceForge 和 Fedora Project 平台搜索公开的源码。 在线UML制图 ProcessOn是一个在线协作绘图平台,为用户提供最强大、易用的作图工具!支持在线创作流程图、BPMN、UML图、UI界面原型设计、iOS界面原型设计等。 Json在线验证及格式化 我用过很多json在线格式化的工具,经过实践,json.cn是比较不错的,不仅支持json格式的验证及格式化,还可以将json格式压缩成普通文本等好用功能。 Diff Check 使用过svn或者git的人对diffcheck肯定不陌生,但有时候我们修改的文本内容并没有被版本控制,那么就可以使用在线的网站查看文件的修改情况。https://www.diffchecker.com/很不错。 MarkDown编辑器 MaHua马克飞象Cmd 以上这几个我都用过,都还好吧,因为我一般都喜欢把自己写过的东西保存下来,所以就用了客户端的,我是用的是MacDown Maven依赖查询 mvnrepository这个不用详细解释了,就是查询maven的gav信息一类的。因为我们公司有内部的Nexus仓库,所以很少用这个。 在线代码运行 http://tool.lu/coderunner/可以在线运行php,c,c++,go,python,java,groovy等代码。基本是很少使用。 在线翻译 Google翻译 百度翻译 有道翻译 爱词霸翻译 说不出具体哪个好,其实都不太准确,还是需要自己根据语境进行翻译。 不过忍不住吐槽一句国内的这几个翻译网站,既然是做翻译的,域名竟然用拼音,我也是醉了。 SQL自动生成Java代码 AutoJCode可以从sql的建表语句中生成一个DO类。 json生成java类 http://www.bejson.com/json2javapojo/ SQL美化/格式化/压缩 sql在线美化,格式化,压缩 编码转换 站长工具的编码转换比较全面,提供了Unicode编码、UFT8编码、URL编码/解码等功能。 Corn表达式生成 Cron一般用于配置定时任务的执行。没有什么特别好的网站,http://www.pdtools.net/tools/becron.jsp还可以吧,基本可以满足需求。 正则验证 Java开发对正则表达式肯定不陌生。站长工具提供的正则验证还不错。 正则代码生成 站长工具提供的正则代码生成。 时间戳转换 时间戳(英语:Timestamp)是指在一连串的资料中加入辨识文字,如时间或日期,用以保障本地端(local)资料更新顺序与远端(remote)一致。 站长工具提供的时间戳转换。 世界时间转换 世界各地时间转换,我比较常用的是北京时间转纽约时间,北京时间转洛杉矶时间。 timebie提供了世界时间相互转换的功能。 加密解密 站长工具中的加密解密 查看网页源代码 查看网页源代码 单位换算 convertworld是一个比较全的单位换算的网站。我经常用它进行时间单位和货币单位的换算。 在线调色板 在线调色板 常用对照表 ASCII对照表 HTTP状态码 HTTP Content-type TCP/UDP常见端口参考 HTML转义字符 RGB颜色参考 欢迎补充~
-
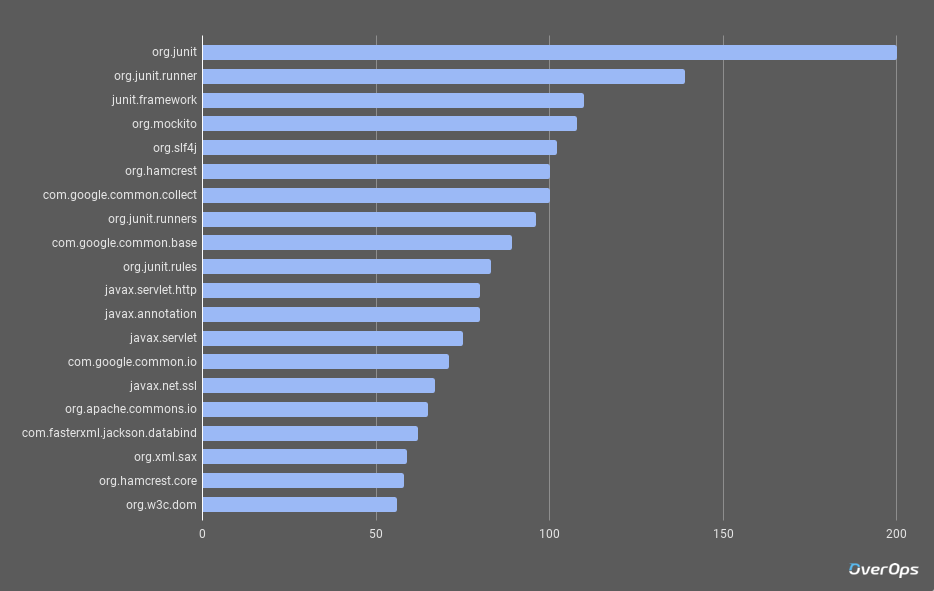
2017年排名Top 100的Java类库——在分析了259,885份源码之后得出的结论 本文由HollisChuang 翻译自 The Top 100 Java Libraries in 2017 – Based on 259,885 Source Files . 原作者:Henn Idan 一年的时间就这么匆匆过去了,就好像像我们昨天才刚刚从GitHub上分析了2016年的Top Java类库一样。今年,我们在数据检索方面采用了Google的BigQuery,来得到更精确的结果。 译者注:BigQuery 是 Google 专门面向数据分析需求设计的一种全面托管的 PB 级低成本企业数据仓库。该服务让开发者可以使用Google的架构来运行SQL语句对超级大的数据库进行操作。BigQuery 可在几秒内扫描 1 TB 的数据,在几分钟内扫描 1 PB 的数据。 首先,我们按照star数排名,从GitHub上拉取了前1000份Java代码仓库,然后过滤掉Android项目,剩下477个纯Java项目。 我们基于这477个纯Java项目进行了分析。我们去重之后统计了所有的类库的import。更深入的关于统计方法的介绍在文章底部。 废话不多说,让我们来看看2017年最受欢迎的Java类库都有哪些?今年又是谁稳坐第一的宝座。 最受欢迎的前20个Java类库 和去年一样,排名第一的类库,依旧是JUnit。基于它扩展的 JUnit Runner 占据第二名的位置,甚至是较旧的 junit.framework 此次也在第三名的位置。也就是说JUnit包揽了前三甲。 Mockito,这个开源的mock测试框架排名第四。 译者注:Mockito 是一个强大的用于 Java 开发的模拟测试框架, 通过 Mockito 我们可以创建和配置 Mock 对象, 进而简化有外部依赖的类的测试. Java中的日志组建 slf4j 位列第五。这从某个侧面体现出目前的开发人员对日志还是比较情有独钟的。同时也看得出Java开发人员对于 java.util.logging 库的使用率较低。我们也曾经分析过Java开发者使用日志的一些习惯和偏好。整理在eBook中。 Hamcrest类库排名的上升,说明了开发人员确实是需要更好的测试环境。 译者注:Hamcrest是一个协助编写用Java语言进行软件测试的框架。它支持创建自定义的断言匹配器(assertion matchers)(名称“Hamcrest”即为“matchers”的异位构词),允许声明式定义匹配规则。这些匹配器在单元测试框架(例如JUnit和jMock)中有用。 分析排名在前几名的类库我们发现,测试对于写出更好的代码是十分重要的。这也就说明了一个事实,出现线上问题是开发者最不想看到的,所以我们会想尽一切办法去避免他的发生。(这部分还有一些关于作者网站的广告,我就不翻译了。) Google的Guava类库排名第 7。 最受欢迎的JSON类库是Jackson 。 榜单第20名,是一个新晋类库:org.w3c.dom 。它提供了一系列操作DOM的接口。 其他值得我们注意的类库 纵观前100名,我们发现Spring 有很好的表现。以下8个类库进入前100 : #57 – org.springframework.beans.factory.annotation #60 – org.springframework.context #65 – org.springframework.context.annotation #66 – org.springframework.stereotype #68 – org.springframework.util #81 – org.springframework.test.context.junit4 #85 – org.springframework.beans.factory #91 – org.springframework.web.bind.annotation 除了Spring之外,Apache的类库也有广泛的应用: #16 – org.apache.commons.io #22 – org.apache.http #24 – org.apache.commons.lang #25 – org.apache.http.impl.client #30 – org.apache.http.client #33 – org.apache.http.client.methods #34 – org.apache.log4j #35 – org.apache.commons.codec.binary #45 – org.apache.commons.lang3 #53 – org.apache.http.entity #61 – org.apache.http.util #64 – org.apache.commons.logging #75 – org.apache.http.message #88 – org.apache.zookeeper #95 – org.apache.hadoop.conf #98 – org.apache.http.client.config #100 – org.apache.http.client.utils 译者注:看到apache类库有这么好的表现,笔者比较开心。笔者一直崇尚不要重复制造轮子,我们日常开发中可能用到的一些方法在apache的类库中具有最佳实现。比如处理IO流、处理集合等。 在今年的排名中,AssertJ较去年有明显的提升,它为 Java 提供了流式断言(Fluent assertions)。今年它攀升至 50 名。 我们在榜单中也发现了 javax.script和 org.apache.http.client.utils这两个脚本API。 脚本API供那些希望在其 Java 应用程序中执行用脚本语言编写的程序的应用程序编程人员使用。 2017年排名Top 100的Java类库详细文档 分析方法 文章开通我们提及过,今年我们使用Google的BigQuery来处理数据。我们通过GitHub提供的API拉取了1000份仓库代码。在过滤掉Android、Arduino和一些过时的仓库后,我们还剩余259,885份Java源文件。我们对同一个仓库中使用的类库进行去重后,还剩余25,788份类库。 我们实际是怎么做的呢? 首先,我们创建一个仓库表,用来存储star数排名靠前的哪些类库,命名为java_top_repos_filtered: SELECT full_name FROM java_top_repos_1000 WHERE NOT ((LOWER(full_name) CONTAINS 'android') OR (LOWER(full_name) CONTAINS 'arduino')) AND ((description IS null) OR (NOT ((LOWER(description) CONTAINS 'android') OR (LOWER(description) CONTAINS 'arduino') OR (LOWER(description) CONTAINS 'deprecated')))); 现在,我们有了排名靠前的类库的名字,然后我们把他们都拉取下来: SELECT repo_name, content FROM [bigquery-public-data:github_repos.contents] AS contents INNER JOIN ( SELECT id, repo_name FROM [bigquery-public-data:github_repos.files] AS files INNER JOIN java_top_repos_filtered AS top_repos ON files.repo_name = top_repos.full_name WHERE path LIKE '%.java' ) AS files_filtered ON contents.id = files_filtered.id; 至此,我们有了每个项目的源代码,我们就要把去重后的import的语句过滤出来,然后在提取包名称。 SELECT package, COUNT(*) count FROM ( //extract package name (exclude last point of data) and group with repo name (to count each package once per repo) SELECT REGEXP_EXTRACT(import_line, r' ([a-z0-9\._]*)\.') package, repo_name FROM ( //extract only 'import' code lines from *.java files SELECT SPLIT(content, '\n') import_line, repo_name FROM java_relevant_data HAVING LEFT(import_line, 6) = 'import' ) GROUP BY package, repo_name ) GROUP BY package ORDER BY count DESC; 最后,我们再进行一次过滤,确保没有Android, Arduino、过时的或者Java提供的原生的类库。 SELECT * FROM java_top_package_count WHERE NOT ((LEFT(package, 5) = 'java.') OR (LOWER(package) CONTAINS 'android')) ORDER BY count DESC; 至此,你就得到了一份2017年排名Top 100的Java类库的列表了。 最后的一点想法 一个主要的结论是:那些2016年受欢迎的类库,在2017年依旧受欢迎。这也说明,这些类库背后的开发者、团队或者公司都在努力的使这些类库更好。 这也意味着,如果你打算开始写自己的Java项目,或者日常的开发中,我们的电子表格可以提供一些好的建议。这些排名靠前的类库是不错的选择。
-
服务器性能指标(一)——负载(Load)分析及问题排查 平常的工作中,在衡量服务器的性能时,经常会涉及到几个指标,load、cpu、mem、qps、rt等。每个指标都有其独特的意义,很多时候在线上出现问题时,往往会伴随着某些指标的异常。大部分情况下,在问题发生之前,某些指标就会提前有异常显示。 对于这些指标的理解和查看、异常解决等,是程序员们重要的必备技能。本文,主要来介绍一下一个比较重要的指标——机器负载(Load),主要涉及负载的定义、查看负载方式、负载飙高排查思路等。 什么是负载 负载(load)是linux机器的一个重要指标,直观了反应了机器当前的状态。 来看下负载的定义是怎样的: In UNIX computing, the system load is a measure of the amount of computational work that a computer system performs. The load average represents the average system load over a period of time. It conventionally appears in the form of three numbers which represent the system load during the last one-, five-, and fifteen-minute periods.(wikipedia) 简单解释一下:在UNIX系统中,系统负载是对当前CPU工作量的度量,被定义为特定时间间隔内运行队列中的平均线程数。load average 表示机器一段时间内的平均load。这个值越低越好。负载过高会导致机器无法处理其他请求及操作,甚至导致死机。 Linux的负载高,主要是由于CPU使用、内存使用、IO消耗三部分构成。任意一项使用过多,都将导致服务器负载的急剧攀升。 查看机器负载。 在Linux机器上,有多个命令都可以查看机器的负载信息。其中包括uptime、top、w等。 uptime命令 uptime命令能够打印系统总共运行了多长时间和系统的平均负载。uptime命令可以显示的信息显示依次为:现在时间、系统已经运行了多长时间、目前有多少登陆用户、系统在过去的1分钟、5分钟和15分钟内的平均负载。 ~ uptime 13:29 up 23:41, 3 users, load averages: 1.74 1.87 1.97 这行信息的后半部分,显示”load average”,它的意思是”系统的平均负荷”,里面有三个数字,我们可以从中判断系统负荷是大还是小。 1.74 1.87 1.97 这三个数字的意思分别是1分钟、5分钟、15分钟内系统的平均负荷。我们一般表示为load1、load5、load15。 w命令 w命令的主要功能其实是显示目前登入系统的用户信息。但是与who不同的是,w命令功能更加强大,w命令还可以显示:当前时间,系统启动到现在的时间,登录用户的数目,系统在最近1分钟、5分钟和15分钟的平均负载。然后是每个用户的各项数据,项目显示顺序如下:登录帐号、终端名称、远 程主机名、登录时间、空闲时间、JCPU、PCPU、当前正在运行进程的命令行。 ~ w 14:08 up 23:41, 3 users, load averages: 1.74 1.87 1.97 USER TTY FROM LOGIN@ IDLE WHAT hollis console - 六14 23:40 - hollis s000 - 六14 20:24 -zsh hollis s001 - 六15 - w 从上面的w命令的结果可以看到,当前系统时间是14:08,系统启动到现在经历了23小时41分钟,共有3个用户登录。系统在近1分钟、5分钟和15分钟的平均负载分别是1.74 1.87 1.97。这和uptime得到的结果相同。 下面还打印了一些登录的用户的各项数据,不详细介绍了。 top命令 top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。 ~ top Processes: 244 total, 3 running, 9 stuck, 232 sleeping, 1484 threads 14:16:01 Load Avg: 1.74, 1.87, 1.97 CPU usage: 8.0% user, 6.79% sys, 85.19% idle SharedLibs: 116M resident, 16M data, 14M linkedit. MemRegions: 66523 total, 2152M resident, 50M private, 930M shared. PhysMem: 7819M used (1692M wired), 370M unused. VM: 682G vsize, 533M framework vsize, 6402060(0) swapins, 7234356(0) swapouts. Networks: packets: 383006/251M in, 334448/60M out. Disks: 1057821/38G read, 350852/40G written. PID COMMAND %CPU TIME #TH #WQ #PORT MEM PURG CMPRS PGRP PPID STATE BOOSTS %CPU_ME %CPU_OTHRS UID FAULTS COW MSGSENT MSGRECV SYSBSD SYSMACH CSW 30845 top 3.0 00:00.49 1/1 0 21 3632K 0B 0B 30845 1394 running *0[1] 0.00000 0.00000 0 3283+ 112 203556+ 101770+ 8212+ 119901+ 823+ 30842 Google Chrom 0.0 00:47.39 17 0 155 130M 0B 0B 1146 1146 sleeping *0[1] 0.00000 0.00000 501 173746 2697 117678 37821 364228 444830 310043 上面的输出结果中,Load Avg: 1.74, 1.87, 1.97显示的就是负载信息。 机器正常负载范围 对于机器的Load到底多少算正常的问题,一直都是很有争议的,不同人有着不同的理解。对于单个CPU,有人认为如果Load超过0.7就算是超出正常范围了。也有人认为只要不超过1都没问题。也有人认为,单个CPU的负载在2以下都可以接受。 为什么会有这么多不同的理解呢,是因为不同的机器除了CPU影响之外还有其他因素的影响,运行的程序、机器内存、甚至是机房温度等都有可能有区别。 比如,有些机器用于定时执行大量的跑批任务,这个时间段内,Load可能会飙的比较高。而其他时间可能会比较低。那么这段飙高时间我们要不要去排查问题呢? 我的建议是,最好根据自己机器的实际情况,建立一个指标的基线(如近一个月的平均值),只要日常的load在基线上下范围内不太大都可以接收,如果差距太多可能就要人为介入检查了。 但是,总要有个建议的阈值吧,关于这个值。阮一峰在自己的博客中有过以下建议: 当系统负荷持续大于0.7,你必须开始调查了,问题出在哪里,防止情况恶化。 当系统负荷持续大于1.0,你必须动手寻找解决办法,把这个值降下来。 当系统负荷达到5.0,就表明你的系统有很严重的问题,长时间没有响应,或者接近死机了。你不应该让系统达到这个值。 以上指标都是基于单CPU的,但是现在很多电脑都是多核的。所以,对一般的系统来说,是根据cpu数量去判断系统是否已经过载(Over Load)的。如果我们认为0.7算是单核机器负载的安全线的话,那么四核机器的负载最好保持在3(4*0.7 = 2.8)以下。 还有一点需要提一下,在Load Avg的指标中,有三个值,1分钟系统负荷、5分钟系统负荷,15分钟系统负荷。我们在排查问题的时候也是可以参考这三个值的。 一般情况下,1分钟系统负荷表示最近的暂时现象。15分钟系统负荷表示是持续现象,并非暂时问题。如果load15较高,而load1较低,可以认为情况有所好转。反之,情况可能在恶化。 如何降低负载 导致负载高的原因可能很复杂,有可能是硬件问题也可能是软件问题。 如果是硬件问题,那么说明机器性能确实就不行了,那么解决起来很简单,直接换机器就可以了。 前面我们提过,CPU使用、内存使用、IO消耗都可能导致负载高。如果是软件问题,有可能由于Java中的某些线程被长时间占用、大量内存持续占用等导致。建议从以下几个方面排查代码问题: 1、是否有内存泄露导致频繁GC 2、是否有死锁发生 3、是否有大字段的读写 4、会不会是数据库操作导致的,排查SQL语句问题。 这里还有个建议,如果发现线上机器Load飙高,可以考虑先把堆栈内存dump下来后,进行重启,暂时解决问题,然后再考虑回滚和排查问题。 Java Web应用Load飙高排查思路 1、使用uptime查看当前load,发现load飙高。 ~ uptime 13:29 up 23:41, 3 users, load averages: 10 10 10 2、使用top命令,查看占用CPU较高的进程ID。 ~ top PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1893 admin 20 0 7127m 2.6g 38m S 181.7 32.6 10:20.26 java 发现PID为1893的进程占用CPU 181%。而且是一个Java进程,基本断定是软件问题。 3、使用 top命令,查看具体是哪个线程占用率较高 ~ top -Hp 1893 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 4519 admin 20 0 7127m 2.6g 38m R 18.6 32.6 0:40.11 java 4、使用printf命令查看这个线程的16进制 ~ printf %x 4519 11a7 5、使用jstack命令查看当前线程正在执行的方法。(Java命令学习系列(二)——Jstack) ~ jstack 1893 |grep -A 200 11a7 "thread-5" #500 daemon prio=10 os_prio=0 tid=0x00007f632314a800 nid=0x11a2 runnable [0x000000005442a000] java.lang.Thread.State: RUNNABLE at sun.misc.URLClassPath$Loader.findResource(URLClassPath.java:684) at sun.misc.URLClassPath.findResource(URLClassPath.java:188) at java.net.URLClassLoader$2.run(URLClassLoader.java:569) at java.net.URLClassLoader$2.run(URLClassLoader.java:567) at java.security.AccessController.doPrivileged(Native Method) at java.net.URLClassLoader.findResource(URLClassLoader.java:566) at org.hibernate.validator.internal.xml.ValidationXmlParser.getInputStreamForPath(ValidationXmlParser.java:248) at com.hollis.test.util.BeanValidator.validate(BeanValidator.java:30) 从上面的线程的栈日志中,可以发现,当前占用CPU较高的线程正在执行我代码的com.hollis.test.util.BeanValidator.validate(BeanValidator.java:30)类。那么就可以去排查这个类是否用法有问题了。 6、还可以使用jstat(Java命令学习系列(四)——jstat)来查看GC情况,看看是否有频繁FGC,然后再使用jmap(Java命令学习系列(三)——Jmap)来dump内存,查看是否存在内存泄露。
-
第一次使用缓存,因为没预热,翻车了 预热一般指缓存预热,一般用在高并发系统中,为了提升系统在高并发情况下的稳定性的一种手段。缓存预热是指在系统启动之前或系统达到高峰期之前,通过预先将常用数据加载到缓存中,以提高缓存命中率和系统性能的过程。缓存预热的目的是尽可能地避免缓存击穿和缓存雪崩,还可以减轻后端存储系统的负载,提高系统的响应速度和吞吐量。 预热的必要性 缓存预热的好处有很多,如: 减少冷启动影响:当系统重启或新启动时,缓存是空的,这被称为冷启动。冷启动可能导致首次请求处理缓慢,因为数据需要从慢速存储(如数据库)检索。 提高数据访问速度:通过预先加载常用数据到缓存中,可以确保数据快速可用,从而加快数据访问速度。 平滑流量峰值:在流量高峰期之前预热缓存可以帮助系统更好地处理高流量,避免在流量激增时出现性能下降。 保证数据的时效性:定期预热可以保证缓存中的数据是最新的,特别是对于高度依赖于实时数据的系统。 减少对后端系统的压力:通过缓存预热,可以减少对数据库或其他后端服务的直接查询,从而减轻它们的负载。 预热的方法 缓存预热的一般做法是在系统启动或系统空闲期间,将常用的数据加载到缓存中,主要做法有以下几种: 系统启动时加载:在系统启动时,将常用的数据加载到缓存中,以便后续的访问可以直接从缓存中获取。 定时任务加载:定时执行任务,将常用的数据加载到缓存中,以保持缓存中数据的实时性和准确性。 手动触发加载:在系统达到高峰期之前,手动触发加载常用数据到缓存中,以提高缓存命中率和系统性能。 用时加载:在用户请求到来时,根据用户的访问模式和业务需求,动态地将数据加载到缓存中。 缓存加载器:一些缓存框架提供了缓存加载器的机制,可以在缓存中不存在数据时,自动调用加载器加载数据到缓存中。 Redis预热 在分布式缓存中,我们通常都是使用Redis,针对Redis的预热,有以下几个工具可供使用,帮助我们实现缓存的预热: RedisBloom:RedisBloom是Redis的一个模块,提供了多个数据结构,包括布隆过滤器、计数器、和TopK数据结构等。其中,布隆过滤器可以用于Redis缓存预热,通过将预热数据添加到布隆过滤器中,可以快速判断一个键是否存在于缓存中。 Redis Bulk loading:这是一个官方出的,基于Redis协议批量写入数据的工具 Redis Desktop Manager:Redis Desktop Manager是一个图形化的Redis客户端,可以用于管理Redis数据库和进行缓存预热。通过Redis Desktop Manager,可以轻松地将预热数据批量导入到Redis缓存中。 应用启动时预热 ApplicationReadyEvent 在应用程序启动时,可以通过监听应用启动事件,或者在应用的初始化阶段,将需要缓存的数据加载到缓存中。 ApplicationReadyEvent 是 Spring Boot 框架中的一个事件类,它表示应用程序已经准备好接收请求,即应用程序已启动且上下文已刷新。这个事件是在 ApplicationContext 被初始化和刷新,并且应用程序已经准备好处理请求时触发的。 基于ApplicationReadyEvent,我们可以在应用程序完全启动并处于可用状态后执行一些初始化逻辑。使用 @EventListener 注解或实现 ApplicationListener 接口来监听这个事件。例如,使用 @EventListener 注解: @EventListener(ApplicationReadyEvent.class) public void preloadCache() { // 在应用启动后执行缓存预热逻辑 // ... }Runner 如果你不想直接监听ApplicationReadyEvent,在SpringBoot中,也可以通过CommandLineRunner 和 ApplicationRunner 来实现这个功能。 CommandLineRunner 和 ApplicationRunner 是 Spring Boot 中用于在应用程序启动后执行特定逻辑的接口。这解释听上去就像是专门干这个事儿的。 import org.springframework.boot.CommandLineRunner; import org.springframework.stereotype.Component; @Component public class MyCommandLineRunner implements CommandLineRunner { @Override public void run(String... args) throws Exception { // 在应用启动后执行缓存预热逻辑 // ... } }import org.springframework.boot.ApplicationArguments; import org.springframework.boot.ApplicationRunner; import org.springframework.stereotype.Component; @Component public class MyApplicationRunner implements ApplicationRunner { @Override public void run(ApplicationArguments args) throws Exception { // 在应用启动后执行缓存预热逻辑 // ... } }CommandLineRunner 和 ApplicationRunner的调用,是在SpringApplication的run方法中 其实就是callRunners(context, applicationArguments);的实现: private void callRunners(ApplicationContext context, ApplicationArguments args) { List runners = new ArrayList(); runners.addAll(context.getBeansOfType(ApplicationRunner.class).values()); runners.addAll(context.getBeansOfType(CommandLineRunner.class).values()); AnnotationAwareOrderComparator.sort(runners); for (Object runner : new LinkedHashSet(runners)) { if (runner instanceof ApplicationRunner) { callRunner((ApplicationRunner) runner, args); } if (runner instanceof CommandLineRunner) { callRunner((CommandLineRunner) runner, args); } } }使用InitializingBean接口 实现 InitializingBean 接口,并在 afterPropertiesSet 方法中执行缓存预热的逻辑。这样,Spring 在初始化 Bean 时会调用 afterPropertiesSet 方法。 import org.springframework.beans.factory.InitializingBean; import org.springframework.stereotype.Component; @Component public class CachePreloader implements InitializingBean { @Override public void afterPropertiesSet() throws Exception { // 执行缓存预热逻辑 // ... } }这个方法的调用我们在Spring的启动流程中也介绍过,不再展开了 使用@PostConstruct注解 类似的,我们还可以使用 @PostConstruct 注解标注一个方法,该方法将在 Bean 的构造函数执行完毕后立即被调用。在这个方法中执行缓存预热的逻辑。 import javax.annotation.PostConstruct; import org.springframework.stereotype.Component; @Component public class CachePreloader { @PostConstruct public void preloadCache() { // 执行缓存预热逻辑 // ... } }定时任务预热 在启动过程中预热有一个问题,那就是一旦启动之后,如果需要预热新的数据,或者需要修改数据,就不支持了,那么,在应用的运行过程中,我们也是可以通过定时任务来实现缓存的更新预热的。 我们通常依赖这种方式来确保缓存中的数据是最新的,避免因为业务数据的变化而导致缓存数据过时。 在Spring中,想要实现一个定时任务也挺简单的,基于@Scheduled就可以轻易实现. @Scheduled(cron = "0 0 1 * * ?") // 每天凌晨1点执行 public void scheduledCachePreload() { // 执行缓存预热逻辑 // ... }也可以依赖xxl-job等定时任务实现。 缓存器预热 些缓存框架提供了缓存加载器的机制,可以在缓存中不存在数据时,自动调用加载器加载数据到缓存中。这样可以简化缓存预热的逻辑。如Caffeine中就有这样的功能: import com.github.benmanes.caffeine.cache.Caffeine; import com.github.benmanes.caffeine.cache.LoadingCache; import org.springframework.stereotype.Service; import java.util.concurrent.TimeUnit; @Service public class MyCacheService { private final LoadingCache cache; public MyCacheService() { this.cache = Caffeine.newBuilder() .refreshAfterWrite(1, TimeUnit.MINUTES) // 配置自动刷新,1分钟刷新一次 .build(key -> loadDataFromSource(key)); // 使用加载器加载数据 } public String getValue(String key) { return cache.get(key); } private String loadDataFromSource(String key) { // 从数据源加载数据的逻辑 // 这里只是一个示例,实际应用中可能是从数据库、外部服务等获取数据 System.out.println("Loading data for key: " + key); return "Value for " + key; } }在上面的例子中,我们使用 Caffeine.newBuilder().refreshAfterWrite(1, TimeUnit.MINUTES) 配置了缓存的自动刷新机制,即每个缓存项在写入后的1分钟内,如果有读请求,Caffeine 会自动触发数据的刷新。 loadDataFromSource 方法是用于加载数据的自定义方法。你可以在这个方法中实现从数据源(例如数据库、外部服务)加载数据的逻辑。
-
[10.17日更新]各大互联网公司架构演进之路汇总 大型网站架构演化历程 大型网站架构技术一览 Web 支付宝和蚂蚁花呗的技术架构及实践 聚划算架构演进和系统优化 (视频+PPT) 淘宝交易系统演进之路 (专访) 淘宝数据魔方技术架构解析 淘宝技术发展历程和架构经验分享(视频+PPT) 阿里游戏高可用架构设计实践 高德——快速转型时期的稳定性架构实践(视频+PPT) 秒杀系统架构分析与实战 腾讯社区搜索架构演进(视频+PPT) 京东峰值系统设计 京东咚咚架构演进 大促系统全流量压测及稳定性保证——京东交易架构分享(含PPT) 京东618实践:一元抢宝系统的数据库架构优化 京东上千页面搭建基石——CMS前后端分离演进史 新浪微博平台架构 微博图床架构揭秘 微博推荐架构的演进 微博众筹的架构设计 当当网系统分级与海量信息动态发布实践 当当网架构演进及规划实现(视频+PPT) LinkedIn架构这十年 4亿用户的LinkedIn数据产品设计原则和架构实现 Facebook’s software architecture(英文) 从0到100——知乎架构变迁史 豆瓣的基础架构 搜狗搜索广告检索系统-弹性架构演进之路(视频+PPT) 小米网抢购系统开发实践 小米抢购限流峰值系统「大秒」架构解密 海尔电商峰值系统架构设计最佳实践 唯品会峰值系统架构演变 1号店电商峰值与流式计算 蘑菇街如何在双11中创造99.99%的可用性 蘑菇街电商交易平台服务架构及改造优化历程(含PPT) 麦包包峰值架构实践 苏宁易购:商品详情系统架构设计 苏宁易购亿万级商品评价系统的架构演进之路和实现细节 携程的技术演进之路 篱笆网技术架构性能演进(视频+PPT) 从技术细节看美团的架构 美团云的网络架构演进之路 百度开放云大数据技术演进历程(视频+PPT) 途牛供应链系统的架构演进(视频+PPT) 途牛订单的服务化演进 Airbnb架构要点分享 12306核心模型设计思路和架构设计 ACFUN 的视频架构演化实践 虎嗅:四年覆盖9成互联网企业中高层的网站架构演变 涂鸦科技:支撑从零暴增数十亿数据的背后,竟无专职运维! 宜人贷系统架构——高并发下的进化之路 链家网技术架构的演进之路 无线 阿里无线技术架构演进 支付宝钱包客户端技术架构 手机淘宝构架演化实践 手淘技术架构演进细节 手机淘宝移动端接入网关基础架构演进之路 微信后台系统的演进之路 微信红包的架构设计简介 微信Android客户端架构演进之路 微信热补丁 Tinker 的实践演进之路 Android QQ音乐架构演进(视频+PPT) 快的打车架构实践 Uber 四年时间增长近 40 倍,背后架构揭秘 Uber容错设计与多机房容灾方案 大众点评移动应用的架构演进(视频+PPT) 饿了么移动APP的架构演进 滴滴出行iOS客户端架构演进之路 今日头条架构演进之路——高压下的架构演进专题(含PPT) 今日头条 User Profile 系统架构实践(视频+PPT) 余额宝技术架构及演进 微博付费打赏架构:一个社交场景下准金融项目开发和实践 千万级用户App小咖秀:服务端架构设计分享 「脉脉」基础架构迁移实战:拯救大兵瑞恩 其他 魅族实时消息推送架构 魅族云端同步的架构实践和协议细节 App架构经验总结 乐视支付架构 欢迎补充!~