找到
6
篇与
面经
相关的结果
-
 记一次蚂蚁金服面试被虐经历 记一次蚂蚁金服面试被虐经历 本文来自作者投稿,原作者:yes 面试前的小姐姐 来说说前不久蚂蚁金服一面的情况。说来也是巧合,当时在群里有位蚂蚁金服的小姐姐发了个内推,看了下JD感觉可以试试于是就私聊了小姐姐发简历内推了。 我16年也就是大三上就开始实习了,到现在其实不到三年的经验。就我个人而言面试的经验真的是少之又少,不超过一个手掌的数。因此我简历发给小姐姐之后又联系她,让她晚点推让我先找几个公司练练手。 但是小姐姐说她可以先帮我热热身,她也是面试官(小姐姐可真的是太好了!),挑了晚上和小姐姐语音了20多分钟,虽然不是具体的面试内容,但是内容比这个更干!她我说了说一面二面大致的问的方向和注重点,还有一些注意事项: 一面: 小姐姐:上来先会给两道编程题,二选一,不会是很难的算法那种,比较务实。基本上常年在一线编程的话能写的出来。是发个链接给你的邮箱,然后点击链接在线编程,没有代码提示,写不出来基本上就是没了。 我:假如有些方法实在记不起来能在idea写了拷过去吗? 小姐姐:这个你可以跟面试官提,不过就我而言比较减分,并且你idea写代码,面试官可能会把代码拿来跑而不是目测过了就好了。如果没跑过也基本上没了。 我:哦哦好的好的。 小姐姐:然后就是自我介绍,一面着重考察基础方面,比如锁啊、GC啊、常见集合等等。再会根据你的简历,比如我看你简历写了dubbo,那就会问一些dubbo方面的问题。这么一堆谈下来差不多了,一面半小时左右。 我:哦哦好的好的。对了一面如果过了的话得多久才会有通知?周期会很长吗? 小姐姐:基本上2-3个工作日就会有结果了。 二面 小姐姐:二面的话比较考察项目,基本上会先让你描述一些项目整体的架构,从哪里到哪里数据怎么流转,项目的tps、qps等,基本上答不出来就认为你不是项目的核心人员。然后为什么这么设计,有哪些优化点?这是考察你对平日的工作有没有足够的思考。 我:哦哦好的好的(瑟瑟发抖)。 三面、四面 小姐姐:emm….你过了一面二面再说吧。 我:是是是!放眼当下。 其实我是真想先投几个公司先找下节奏的,但是小姐姐都这样说了我就只能直面人生了!过了两天面试官就来电话了,约个几天后的晚上7点,并且指明需要有电脑(小姐姐诚不我欺啊),我问需要摄像头不,答:不需要,能上网就行。 面试正文 其实我也忘记到底约的是7点还是7点半,反正我7点坐在电脑前面等了,内心激动的一批,饭都吃不下等到了7.35,终于等到你还好我没放弃!! 听到电话那头传来的温柔的小哥哥声音,来了他终于来了!我已经打开邮箱等待编程题的到来了! 小哥哥:来先做个自我介绍吧。 我:emm???不是说上来先做两道题吗?额可能是先自我介绍下再做题把?于是我就巴拉巴拉说了20秒,说到在现在公司做一部分前端开发的时候就被打断了。 小哥哥:说说你写前端有什么感触? 我:我想要换工作有很大一部分原因就是因为现在我需要做前端,前端对我而言吸引力不大,虽然对于后端而言前端给予的正反馈更加的明显和及时,但是我更喜欢后端在背后默默输出的感觉。 小哥哥:是的,前端对于后端而言更加的简单,掌握了几个框架基本上就够用了,天花板比较低。 我:是的是的,后端的东西太多了,涉及到的面很广(各位前端听友,上面的话是小哥哥说的,原话,雨我无瓜。我也是身不由己是吧,请海涵哈) 小哥哥:看你简历写了Dubbo、Redis、RocketMq,你挑个你最厉害的说说? 我:(我擦,我个人觉得这个问题看似为我考虑,实则暗藏杀机)redis吧? 我其实大脑快速过滤了一下感觉redis比较稳,我觉得能问的无非是: redis为什么单线程?IO多路复用? redis和memcached的优缺点? redis五个对象?每个对象的底层数据结构? redis的布隆过滤器(我还可以给你引申个布谷鸟过滤器)、hyperLogLog(我还给你说出是基于伯努利实验) redis的过期删除机制?淘汰机制? redis的RDB和AOF? redis的事务? redis的主从?哨兵?集群? redis的分布式锁?redlock?(来嘛martin大神对刚redis作者的内容我都说的出来) redis的一些优化?大key拆分?通过游标分批返回避免key*等命令阻塞?禁止swap?考虑内存碎片等等? 感觉好像挺稳的那就redis吧! 小哥哥:redis集群介绍一下 我:(来了来了!)redis的集群是将一共16384个槽分给集群中节点,每个节点通过gossip消息得知其它节点的信息,并在自身的clusterState中记录了所有的节点的信息和槽数组的分配情况 小哥哥:客户端是如何访问集群的? 我:客户端会先访问集群中的一个节点,如果槽命中直接访问,如果不命中,则会返回MOVED指令,并告知槽实际存在的节点,然后再去访问。(这里其实还有个迁移中的情况,如果访问的槽正在迁移,则返回ask命令,客户端会被引导去目标节点查找) 小哥哥:你们公司是用集群么? 我:是主从 小哥哥:知道关晓彤么? 我:???(什么情况这个跨度这么大吗?) 小哥哥紧接着说:就是和鹿晗那次把微博弄挂了的情况 我:哦哦哦知道知道 小哥哥:微博这么大的公司了,而且出了这么多这种事故?为什么还会挂了? 我:(我擦,为什么这么出了这么多次情况还会挂我咋知道!这么大公司监控服务很到位的啊,并且报警自动扩缩容这一套组合拳下来感觉不应该挂的啊,它为啥挂了…)我弱弱的说了句热点key的问题?太热了顶不住 小哥哥:那怎么处理呢? 我: 首先保障热点 key 过期问题,给不同的热点key分配随机的过期时间,保证过期的平滑。然后可以通过在 Redis 中设置分布式锁,只有获取到锁的请求才能够穿透到数据库,保证同一时间只有一个请求可以穿透到数据库更新缓存。 小哥哥:不是,我不是这个意思,我是问这个热点key的访问要如何解决? 我:可以通过 hash 分 key,把一个 key 拆分成多个 key,分布到不同的节点,防止单点过热。比如一个 key 之前就分到一个节点上,我把 key 做了拆分,就像一致性 hash 的虚拟节点,分散访问。 小哥哥:你说到一致性 hash?那和普通hash有什么区别? 我:一致性hash把hash的空间虚拟成一个圆环,key做hash落在圆环上,按顺时针查找,遇到的第一个缓存节点就命中。通过虚拟节点避免缓存分布不均,并且使得某个节点挂了之后,下面的节点只需要承担一部分的流量而不会因为需要承担所有流量而挂了,然后发生雪崩 小哥哥:好,那我们说回刚才的问题,你刚说的是一种解决方案那还有什么别的方案么? 我:(还有??我真的没了,我思考了十秒钟,一片空白不知道了)不知道了。 其实还有本地缓存,简单点就一个HashMap就行,或者Guava cache或者Ehcache。用本地缓存来应对极热数据。 小哥哥:那好吧,来说说MQ吧 我:(小哥哥有点失望的样子,哎也是不应该但是脑子就是想不起来..)常见的有RocketMQ、KafKa等,RocketMQ更适合业务,注重时延的优化。Kafka因为存在攒一波的思想,吞吐更高,并且适合大数据场景,不适合业务。 小哥哥:攒一波是什么意思? 我:攒一波就是发消息默认不是一条一条发,是等一波再发(其实攒一波思想很常见,例如tcp的纳格算法,pageCache的批量刷盘等等) 小哥哥:那Kafka是哪种模式? 我:什么意思?什么模式? 小哥哥:就是消息不是有推和拉两种模式 我:额…(我不知道,我就知道RocketMQ的,是基于拉的,虽说有个pushConsumer,但是本质上也就是拉,只是broker先hold住了拉的request。我也知道拉模式和推模式的优缺点,只是我当时傻了,我当时脑子想我简历就没写Kafka,为啥问我Kafka不问我RocketMQ,其实我应该先说说推拉模式的优缺点然后说了RocketMQ是采用什么的,然后说下我对Kafka不太熟,只是我当时傻了…)我说推?应该是推吧? 不对不对好像是拉….(我真的是神操作) 小哥哥:不知道就说不知道,不要乱说一通。 我:是是是,我不知道对不起。(是的不知道就直接说不知道,然后应该把自己知道的说出来,弥补下) 小哥哥:说说synchronize和lock区别 我:(来了来了,赶紧弥补下刚才的操作)synchronized是java内置锁,不需要手动的解锁,支持可重入,但是非公平,不可中断,条件单一,在1.6之前性能较差,经过1.6优化只有性能有显著的提升。 lock,基于AQS,拿reentrant为例,需要手动解锁,可重入,支持中断,支持多条件,支持超时操作。 (来快问我synchronized底层和1.6做了什么优化,我来从monitor对象开始说到字节码到monitorenter和monitorexit再到mutex,从偏向锁到轻量级锁到重量级锁,我再说个逃逸分析、锁消除、锁粗化。再引申出个JMM,来个cpu缓存L1、L2、L3到MESI,我还可以给你来个cpu缓存行伪共享问题。什么你问的是锁为什么重?那就来上下文切换,内核态用户态,系统调用,再给你引到上一个mq话题,搞个mmap、sendfile零拷贝,扯一波pageCache、内存预分配、文件预热、mlock等。来啊!!!) 小哥哥:说说AQS原理吧 我:(擦竟然不问我synchronized)AQS主要是采用state,通过对state的CAS判断来获取锁和解锁,并且存在等待队列和条件等待队列来park相关线程之后入队等待,有公平和非公平两者模式来唤醒等待的线程。 小哥哥:那为什么需要个AQS? 我:主要是为了封装和抽象,通过封装了公共的方法,减少重复代码。 小哥哥:说说GC调优把 我:GC调优一般具体是通过GC日志的情况来分析。基本上发现minor gc频繁,新生代空间太小了。如果发现晋升的年龄很小,老年代迅速被填满,导致频繁的major gc,并且回收比率又很大,那说明对象的生命周期确实很短也需要调整新生代。如果看full gc很频繁,但是每次回收的内存就一点点,那目测就是内存泄露了。总体上就是根据分代的根本,也就是新生代朝生夕死的事实调整GC,避免分配大对象。具体还是得分析GC日志。 小哥哥:好,那说下mysql like有什么注意点? 我:最左匹配,防止全表扫描而不走索引 小哥哥:那说说mysql查找过程 我:就拿命中索引的说吧,innodb主键是聚簇索引,采用b+树结构,非叶节点存的是主键和指向子节点的指针,叶子节点存的就是整体行数据,整体都是有序的,通过主键扫描根据树查找,最终落到叶子节点,命中然后返回。(其实更细的有mysql的一页有16kb,一页其实有多行记录,命中一页之后还要通过行记录索引通过二分找到行记录) 小哥哥:那知道LSM树么? 我:(LSM,其实我是知道的,而且我还做过笔记,不过当时就是好耳熟啊…然后就没然后了)我说听过,但是不太记得 小哥哥:那cassandra知道么? 我:啥cass的? 小哥哥:就是cassandra 我:(我脑子在想什么卡丝娜的瑞,上面mq被教育过了)我果断的说不知道 (实际上我听过,只知道是个nosql数据库,没用过) 小哥哥:行,那说了这么多我们来写一道题把? 我:(我擦我才想起来还得写题,这不是先上来写题的吗,节奏怎么不对?) 好的好的 小哥哥:LRU知道吧?来实现这个接口 我:(哎我抖了个机灵….想展示一下自己知道的多),我可以用LinkedHashMap嘛,我继承LinkedHashMap,重写removeEldestEntry 小哥哥:不行,给你接口当然只能实现这个接口 我:哦哦好的。(好像弄巧成拙了),那我先说说思路吧,通过链表,存储节点,新插入的节点插入到头部,访问过的节点也移动到头部 小哥哥说:好的你写吧 我:我在草稿纸上画了一下,然后边写边说我的写什么,其实我感觉不说点啥有点奇怪,我就边写边说我在写啥。 我:大概过了10多分钟,我写完了。 小哥哥:看着我的代码,他也捋了一遍思路,口述一下说恩可以,那说说时间复杂度和空间复杂度把 我:我用了HashMap以空间换时间的思路存储了key和node之间的关系,并且有记录头尾节点的引用,并且链表是双向链表,因此插入和查找的时间复杂度都是O(1),空间复杂度是O(n)。 小哥哥:那说说要线程安全的话怎么改造吧 我:简单粗暴就是在每个方法上都加锁了,在竞争不是很激烈的时候挺合适的,再进阶一下,可以使用concurrentHashMap,然后再锁方法内部,移动链表等代码,减少锁的粒度。 小哥哥:行,那差不多了,你有什么想问的么? 我:我刚才的表现怎么样 小哥哥:从刚才的回答可以看出你有一定的积累,包括刚才你说的LinkedHashMap,可以看出你也有所准备的(emmm…好像让小哥哥觉得我能写出这个代码是因为我写过LRU…讲真我只写过继承LinkedHashMap的….从node实体都要自己建的开始我还真没写过..),不过还是需要多看看公众号,多看看一些好的博客,逛逛社区,至于今天的结果我答复不了,还是得会去讨论的。 我:是是是,持续学习,好的。 小哥哥:那今天就到这了。 我:嗯嗯好的好的 结果 说好的半小时左右,这一波下来算上笔试花了1小时25分钟…..结果挂了…. 回顾下刚才的情况,鹿晗那波没答出本地缓存、KafKa推拉都不知道、LSM树竟然不知道、cassandra也不晓得..推断出这个人好像知识面不是很广的样子…难受确实惭愧。 事后我去查了查鹿晗那波为挂了:主要是时间点在17年10.8号,17年的时候微博的报警扩缩容还是人为的,没有自动扩缩容,并且10.8号,国庆期间很多人出去玩了都没打开微博,然后还有很多平时不玩微博的吃瓜群众,一听到这个消息都打开微博,这波冷数据击垮了微博某个系统,导致雪崩。 KafKa 是拉,拉的时候没消息阻塞住,或者等消息达到一定数量拉请求才返回。 LSM(Log Structured Merge Trees),像日志一样顺序追加,顺序写,因此写入性能很高,为了优化读,到一定阶段会排序合并。 cassandra 上网查吧..这里不再赘述。 总而言之还是太菜了… 共勉。
记一次蚂蚁金服面试被虐经历 记一次蚂蚁金服面试被虐经历 本文来自作者投稿,原作者:yes 面试前的小姐姐 来说说前不久蚂蚁金服一面的情况。说来也是巧合,当时在群里有位蚂蚁金服的小姐姐发了个内推,看了下JD感觉可以试试于是就私聊了小姐姐发简历内推了。 我16年也就是大三上就开始实习了,到现在其实不到三年的经验。就我个人而言面试的经验真的是少之又少,不超过一个手掌的数。因此我简历发给小姐姐之后又联系她,让她晚点推让我先找几个公司练练手。 但是小姐姐说她可以先帮我热热身,她也是面试官(小姐姐可真的是太好了!),挑了晚上和小姐姐语音了20多分钟,虽然不是具体的面试内容,但是内容比这个更干!她我说了说一面二面大致的问的方向和注重点,还有一些注意事项: 一面: 小姐姐:上来先会给两道编程题,二选一,不会是很难的算法那种,比较务实。基本上常年在一线编程的话能写的出来。是发个链接给你的邮箱,然后点击链接在线编程,没有代码提示,写不出来基本上就是没了。 我:假如有些方法实在记不起来能在idea写了拷过去吗? 小姐姐:这个你可以跟面试官提,不过就我而言比较减分,并且你idea写代码,面试官可能会把代码拿来跑而不是目测过了就好了。如果没跑过也基本上没了。 我:哦哦好的好的。 小姐姐:然后就是自我介绍,一面着重考察基础方面,比如锁啊、GC啊、常见集合等等。再会根据你的简历,比如我看你简历写了dubbo,那就会问一些dubbo方面的问题。这么一堆谈下来差不多了,一面半小时左右。 我:哦哦好的好的。对了一面如果过了的话得多久才会有通知?周期会很长吗? 小姐姐:基本上2-3个工作日就会有结果了。 二面 小姐姐:二面的话比较考察项目,基本上会先让你描述一些项目整体的架构,从哪里到哪里数据怎么流转,项目的tps、qps等,基本上答不出来就认为你不是项目的核心人员。然后为什么这么设计,有哪些优化点?这是考察你对平日的工作有没有足够的思考。 我:哦哦好的好的(瑟瑟发抖)。 三面、四面 小姐姐:emm….你过了一面二面再说吧。 我:是是是!放眼当下。 其实我是真想先投几个公司先找下节奏的,但是小姐姐都这样说了我就只能直面人生了!过了两天面试官就来电话了,约个几天后的晚上7点,并且指明需要有电脑(小姐姐诚不我欺啊),我问需要摄像头不,答:不需要,能上网就行。 面试正文 其实我也忘记到底约的是7点还是7点半,反正我7点坐在电脑前面等了,内心激动的一批,饭都吃不下等到了7.35,终于等到你还好我没放弃!! 听到电话那头传来的温柔的小哥哥声音,来了他终于来了!我已经打开邮箱等待编程题的到来了! 小哥哥:来先做个自我介绍吧。 我:emm???不是说上来先做两道题吗?额可能是先自我介绍下再做题把?于是我就巴拉巴拉说了20秒,说到在现在公司做一部分前端开发的时候就被打断了。 小哥哥:说说你写前端有什么感触? 我:我想要换工作有很大一部分原因就是因为现在我需要做前端,前端对我而言吸引力不大,虽然对于后端而言前端给予的正反馈更加的明显和及时,但是我更喜欢后端在背后默默输出的感觉。 小哥哥:是的,前端对于后端而言更加的简单,掌握了几个框架基本上就够用了,天花板比较低。 我:是的是的,后端的东西太多了,涉及到的面很广(各位前端听友,上面的话是小哥哥说的,原话,雨我无瓜。我也是身不由己是吧,请海涵哈) 小哥哥:看你简历写了Dubbo、Redis、RocketMq,你挑个你最厉害的说说? 我:(我擦,我个人觉得这个问题看似为我考虑,实则暗藏杀机)redis吧? 我其实大脑快速过滤了一下感觉redis比较稳,我觉得能问的无非是: redis为什么单线程?IO多路复用? redis和memcached的优缺点? redis五个对象?每个对象的底层数据结构? redis的布隆过滤器(我还可以给你引申个布谷鸟过滤器)、hyperLogLog(我还给你说出是基于伯努利实验) redis的过期删除机制?淘汰机制? redis的RDB和AOF? redis的事务? redis的主从?哨兵?集群? redis的分布式锁?redlock?(来嘛martin大神对刚redis作者的内容我都说的出来) redis的一些优化?大key拆分?通过游标分批返回避免key*等命令阻塞?禁止swap?考虑内存碎片等等? 感觉好像挺稳的那就redis吧! 小哥哥:redis集群介绍一下 我:(来了来了!)redis的集群是将一共16384个槽分给集群中节点,每个节点通过gossip消息得知其它节点的信息,并在自身的clusterState中记录了所有的节点的信息和槽数组的分配情况 小哥哥:客户端是如何访问集群的? 我:客户端会先访问集群中的一个节点,如果槽命中直接访问,如果不命中,则会返回MOVED指令,并告知槽实际存在的节点,然后再去访问。(这里其实还有个迁移中的情况,如果访问的槽正在迁移,则返回ask命令,客户端会被引导去目标节点查找) 小哥哥:你们公司是用集群么? 我:是主从 小哥哥:知道关晓彤么? 我:???(什么情况这个跨度这么大吗?) 小哥哥紧接着说:就是和鹿晗那次把微博弄挂了的情况 我:哦哦哦知道知道 小哥哥:微博这么大的公司了,而且出了这么多这种事故?为什么还会挂了? 我:(我擦,为什么这么出了这么多次情况还会挂我咋知道!这么大公司监控服务很到位的啊,并且报警自动扩缩容这一套组合拳下来感觉不应该挂的啊,它为啥挂了…)我弱弱的说了句热点key的问题?太热了顶不住 小哥哥:那怎么处理呢? 我: 首先保障热点 key 过期问题,给不同的热点key分配随机的过期时间,保证过期的平滑。然后可以通过在 Redis 中设置分布式锁,只有获取到锁的请求才能够穿透到数据库,保证同一时间只有一个请求可以穿透到数据库更新缓存。 小哥哥:不是,我不是这个意思,我是问这个热点key的访问要如何解决? 我:可以通过 hash 分 key,把一个 key 拆分成多个 key,分布到不同的节点,防止单点过热。比如一个 key 之前就分到一个节点上,我把 key 做了拆分,就像一致性 hash 的虚拟节点,分散访问。 小哥哥:你说到一致性 hash?那和普通hash有什么区别? 我:一致性hash把hash的空间虚拟成一个圆环,key做hash落在圆环上,按顺时针查找,遇到的第一个缓存节点就命中。通过虚拟节点避免缓存分布不均,并且使得某个节点挂了之后,下面的节点只需要承担一部分的流量而不会因为需要承担所有流量而挂了,然后发生雪崩 小哥哥:好,那我们说回刚才的问题,你刚说的是一种解决方案那还有什么别的方案么? 我:(还有??我真的没了,我思考了十秒钟,一片空白不知道了)不知道了。 其实还有本地缓存,简单点就一个HashMap就行,或者Guava cache或者Ehcache。用本地缓存来应对极热数据。 小哥哥:那好吧,来说说MQ吧 我:(小哥哥有点失望的样子,哎也是不应该但是脑子就是想不起来..)常见的有RocketMQ、KafKa等,RocketMQ更适合业务,注重时延的优化。Kafka因为存在攒一波的思想,吞吐更高,并且适合大数据场景,不适合业务。 小哥哥:攒一波是什么意思? 我:攒一波就是发消息默认不是一条一条发,是等一波再发(其实攒一波思想很常见,例如tcp的纳格算法,pageCache的批量刷盘等等) 小哥哥:那Kafka是哪种模式? 我:什么意思?什么模式? 小哥哥:就是消息不是有推和拉两种模式 我:额…(我不知道,我就知道RocketMQ的,是基于拉的,虽说有个pushConsumer,但是本质上也就是拉,只是broker先hold住了拉的request。我也知道拉模式和推模式的优缺点,只是我当时傻了,我当时脑子想我简历就没写Kafka,为啥问我Kafka不问我RocketMQ,其实我应该先说说推拉模式的优缺点然后说了RocketMQ是采用什么的,然后说下我对Kafka不太熟,只是我当时傻了…)我说推?应该是推吧? 不对不对好像是拉….(我真的是神操作) 小哥哥:不知道就说不知道,不要乱说一通。 我:是是是,我不知道对不起。(是的不知道就直接说不知道,然后应该把自己知道的说出来,弥补下) 小哥哥:说说synchronize和lock区别 我:(来了来了,赶紧弥补下刚才的操作)synchronized是java内置锁,不需要手动的解锁,支持可重入,但是非公平,不可中断,条件单一,在1.6之前性能较差,经过1.6优化只有性能有显著的提升。 lock,基于AQS,拿reentrant为例,需要手动解锁,可重入,支持中断,支持多条件,支持超时操作。 (来快问我synchronized底层和1.6做了什么优化,我来从monitor对象开始说到字节码到monitorenter和monitorexit再到mutex,从偏向锁到轻量级锁到重量级锁,我再说个逃逸分析、锁消除、锁粗化。再引申出个JMM,来个cpu缓存L1、L2、L3到MESI,我还可以给你来个cpu缓存行伪共享问题。什么你问的是锁为什么重?那就来上下文切换,内核态用户态,系统调用,再给你引到上一个mq话题,搞个mmap、sendfile零拷贝,扯一波pageCache、内存预分配、文件预热、mlock等。来啊!!!) 小哥哥:说说AQS原理吧 我:(擦竟然不问我synchronized)AQS主要是采用state,通过对state的CAS判断来获取锁和解锁,并且存在等待队列和条件等待队列来park相关线程之后入队等待,有公平和非公平两者模式来唤醒等待的线程。 小哥哥:那为什么需要个AQS? 我:主要是为了封装和抽象,通过封装了公共的方法,减少重复代码。 小哥哥:说说GC调优把 我:GC调优一般具体是通过GC日志的情况来分析。基本上发现minor gc频繁,新生代空间太小了。如果发现晋升的年龄很小,老年代迅速被填满,导致频繁的major gc,并且回收比率又很大,那说明对象的生命周期确实很短也需要调整新生代。如果看full gc很频繁,但是每次回收的内存就一点点,那目测就是内存泄露了。总体上就是根据分代的根本,也就是新生代朝生夕死的事实调整GC,避免分配大对象。具体还是得分析GC日志。 小哥哥:好,那说下mysql like有什么注意点? 我:最左匹配,防止全表扫描而不走索引 小哥哥:那说说mysql查找过程 我:就拿命中索引的说吧,innodb主键是聚簇索引,采用b+树结构,非叶节点存的是主键和指向子节点的指针,叶子节点存的就是整体行数据,整体都是有序的,通过主键扫描根据树查找,最终落到叶子节点,命中然后返回。(其实更细的有mysql的一页有16kb,一页其实有多行记录,命中一页之后还要通过行记录索引通过二分找到行记录) 小哥哥:那知道LSM树么? 我:(LSM,其实我是知道的,而且我还做过笔记,不过当时就是好耳熟啊…然后就没然后了)我说听过,但是不太记得 小哥哥:那cassandra知道么? 我:啥cass的? 小哥哥:就是cassandra 我:(我脑子在想什么卡丝娜的瑞,上面mq被教育过了)我果断的说不知道 (实际上我听过,只知道是个nosql数据库,没用过) 小哥哥:行,那说了这么多我们来写一道题把? 我:(我擦我才想起来还得写题,这不是先上来写题的吗,节奏怎么不对?) 好的好的 小哥哥:LRU知道吧?来实现这个接口 我:(哎我抖了个机灵….想展示一下自己知道的多),我可以用LinkedHashMap嘛,我继承LinkedHashMap,重写removeEldestEntry 小哥哥:不行,给你接口当然只能实现这个接口 我:哦哦好的。(好像弄巧成拙了),那我先说说思路吧,通过链表,存储节点,新插入的节点插入到头部,访问过的节点也移动到头部 小哥哥说:好的你写吧 我:我在草稿纸上画了一下,然后边写边说我的写什么,其实我感觉不说点啥有点奇怪,我就边写边说我在写啥。 我:大概过了10多分钟,我写完了。 小哥哥:看着我的代码,他也捋了一遍思路,口述一下说恩可以,那说说时间复杂度和空间复杂度把 我:我用了HashMap以空间换时间的思路存储了key和node之间的关系,并且有记录头尾节点的引用,并且链表是双向链表,因此插入和查找的时间复杂度都是O(1),空间复杂度是O(n)。 小哥哥:那说说要线程安全的话怎么改造吧 我:简单粗暴就是在每个方法上都加锁了,在竞争不是很激烈的时候挺合适的,再进阶一下,可以使用concurrentHashMap,然后再锁方法内部,移动链表等代码,减少锁的粒度。 小哥哥:行,那差不多了,你有什么想问的么? 我:我刚才的表现怎么样 小哥哥:从刚才的回答可以看出你有一定的积累,包括刚才你说的LinkedHashMap,可以看出你也有所准备的(emmm…好像让小哥哥觉得我能写出这个代码是因为我写过LRU…讲真我只写过继承LinkedHashMap的….从node实体都要自己建的开始我还真没写过..),不过还是需要多看看公众号,多看看一些好的博客,逛逛社区,至于今天的结果我答复不了,还是得会去讨论的。 我:是是是,持续学习,好的。 小哥哥:那今天就到这了。 我:嗯嗯好的好的 结果 说好的半小时左右,这一波下来算上笔试花了1小时25分钟…..结果挂了…. 回顾下刚才的情况,鹿晗那波没答出本地缓存、KafKa推拉都不知道、LSM树竟然不知道、cassandra也不晓得..推断出这个人好像知识面不是很广的样子…难受确实惭愧。 事后我去查了查鹿晗那波为挂了:主要是时间点在17年10.8号,17年的时候微博的报警扩缩容还是人为的,没有自动扩缩容,并且10.8号,国庆期间很多人出去玩了都没打开微博,然后还有很多平时不玩微博的吃瓜群众,一听到这个消息都打开微博,这波冷数据击垮了微博某个系统,导致雪崩。 KafKa 是拉,拉的时候没消息阻塞住,或者等消息达到一定数量拉请求才返回。 LSM(Log Structured Merge Trees),像日志一样顺序追加,顺序写,因此写入性能很高,为了优化读,到一定阶段会排序合并。 cassandra 上网查吧..这里不再赘述。 总而言之还是太菜了… 共勉。
-
实习生招聘收割阿里、腾讯等大厂Offer后,有些话想和应届生说 本文来自读者投稿,作者是我的一位资深读者,也是我知识星球的球友,最近在春招中收割了很多大厂的Offer。看了他总结后,我发现很多地方和我当年参加校招的时候很相像,甚至比我那个时候还要优秀。分享给大家,和大家一起共勉。 以下是他的原文: 背景 本人211(郑州大学)21届本科毕业生,和大佬相比,我还是一只蒻箕。不过在H大博客和知识星球的帮助下,我终于在20年实习招聘时拿到了阿里(Java)和腾讯(后台转C++)的offer,回想准备面试以及学习的这一路走来,尽管有些崎岖,但终于如愿以偿。 考研or就业 这里不考虑保研的情况,因为如果可以保研的话,我相信大多数人都会选择保研。 其实我的GPA也不低,曾经误以为自己可以保研,但是低估了我们专业的狗血程度,所以就在大二下学期慢慢接受了不能保研的事实。但是由于我还想在大学还没玩够(主要是大学没对象),就想上个研究生,所以在大三上就萌生了考研的念头。为什么我最后没有选择上研究生呢?我相信每个人的处境都不相同,原因也都不尽一样。在这里我说一下大家应该考虑的几个点: 自己更想就业还是更想上研究生 为什么想就业,为什么想上研究生 你对研究生要研究的领域真的感兴趣吗 哪个把握更大一点 学历真能成为你的硬伤吗 … 最后说一句:人生是一个不断选择的过程,每个选择都没有对错,只要你想,无论考研还是就业,都能成功! 学习过程 我是从19年4月从打CTF转到Java的,当时也算是比较幸运,遇到了工程能力比较强的副教授给我们上Java课,并不是给我们讲Java语法,而是从Jvm开始讲起,也算是让我直接对Java入了门。 然后和我同桌(https://blog.csdn.net/qq_42322103 )一起学习Java,看同桌给我分享的黑马的教程(PS 后来发现这些东西全讲的API哈哈哈,但确实让我们对整个Java体系有了了解)。 有空就看,晚上一直学习到10点半才回宿舍睡觉,早上7点半到教室还能再看一会。 然后每看一个章节都把笔记放到CSDN(https://blog.csdn.net/coder_what )上,就这样的学习强度一直持续到了暑假。 期间还做了一个基于BIO+Swing的学生管理系统,也算有些收获。 暑假时我只在家呆了7天,在学校学习了SSM,然后基于SpringBoot和Vue做了一个前后端分离的个人博客系统(http://wxxlamp.cn )。 整个博客的需求分析,设计,编码和运维都是我一个人负责的,俗话说,麻雀虽小,五脏俱全,通过这个博客,我熟悉了中小型软件开发的整个流程,收获也确实不小。 然后由于计划是准备20年实习,所以我在大三上学期就有些懈怠,同时还参加了一个人流量预测比赛。 这里我确实有些遗憾,如果我意识能更早一点,就可以在大三上学期准备实习和面试,然后大三寒假就可以拿到实习资格,但是当时也不太懂,所以就拖到了大三的寒假准备实习。 在准备面试的过程中,这其实是一个磨心态的过程,难免会有自卑和自傲的时候,一定一定要调整好状态,重新出发,“厂子千千万,不行咱就换”。 面试心得 个人认为我准备的比较充分。我准备的具体流程为上牛客找面试题,然后归类总结,最后在通过百度谷歌找出这些问题的答案,自己再进行理解,循环往复,就ok了。下面我列一下一些面试(Java)常见的问题: Java基础 泛型,面向对象和面向过程的区别,语法糖,包装类和基本类型,stream,lambda,多态实现方式,==/equals/hashCode(),static和final,内部类,接口和抽象类,编码方式,异常,IO,反射 Java容器 Collection和Map,HashMap的结构(1.7和1.8),hashMap的几个变量,初始化值,LRU与LinkedHashMap,ArrayList的扩容原理,如何使容器变得线程安全,队列的使用场景 Jvm 编译执行or解释执行,常量池,类加载过程,实例初始化过程,GC算法,Jvm内存空间,常见的Jvm命令如jstat,jhat,jmap,jinfo,内存泄露怎么处理,如何定位while死循环和死锁 Java并发 jmm,volatile,synchronized,并发编程的三个特性(如何保证),Object的几个方法,Thread的几个方法,线程五个状态,JUC包(并发容器,lock,工具类,线程池,原子类),AQS原理,ThreadLocal,线程的,多线程循环打印abc,生产者消费者模式 设计模式 五大原则,工厂模式,迭代器模式,观察者模式,适配器模式,策略模式,代理模式,外观模式,享元模式,单例模式,装饰者模式,组合模式,模板方法模式等 408(计算机学科专业基础综合) 进程线程和协程,内存管理方式,常见linux命令top,ps,cat等,网络模型,nio(epoll,poll,select),bio,aio,虚拟内存,页面替换算法,磁道调度算法,银行家算法,死锁定义,CPU调度算法,哲学家问题,理发师问题,进程内存分配,进程切换过程,内存管理方式 7层模型,url的执行过程,HTTP1,2和HTTPS,TCP和UDP,SYN泛洪,TIME_WAIT处理方式,中间人攻击,TCP的沾包和拆包,XSS,CSXF,DDOS,SQL注入 链表和数组,翻转链表,树的镜像,树的遍历,合并有序数组,topK问题,大数据找中位数,大数据排序,快速找到某个人的排名,红黑树,AVL树,B+树,各种排序,这个刷LeetCode就完事了 MySQL 隔离级别,ACID,ACID如何实现,MVCC,索引,前缀索引,回表,最左原则,聚簇索引,非聚簇索引,覆盖索引,hash索引,索引下推,索引结构,Innodb和MyISAM,间隙锁,行锁,表锁,relog,undolog,binlog Redis 缓存一致性,持久化方式,网络模式,IO方式,性能高的原因,为什么单线程,集群方式,分布式锁,Redis如何保证多条命令单线程执行,Redis的数据结构,跳表 Nginx 负载均衡方式,为什么可以负载均衡,为什么可做反向代理,nginx有什么功能,如何保证缓存时间不一致,怎么设置Nginx SSM spring的启动流程,springboot的启动流程,aop和ioc,springboot的SPI,mybatis的代理模式,#和(,为什么)不可缺少,bean的生命周期,SSM的设计模式,Spring的事物,bean的相互依赖 其他 项目流程,限流器,LRU算法,黑名单算法,项目亮点,项目难点,团队如何协作,如何快速找到互相关注的人,tomcat的启动流程,微服务,RPC流程,MQ,docker,k8s,分布式事物,CASE和CAP 关于面试方面,建议和别人一起对练,包括自我介绍(准备两个,一个技术,一个hr),然后通过简历互相问技术。真正面试的时候,一定要放轻松,然后不会的地方就说不会,会一点的地方一定要把会那一点说出来。不要跟面试官说你准备过什么的,这样就显得太刻意了。 关于简历 个人认为还是不要写的花里胡哨的,WonderCV(https://www.wondercv.com/ )就很不错。简历照片也要来一张好看的,个人觉的白底比较好。 简历最前面的肯定是个人信息(GPA,学校,课程),接着是掌握的技术栈(可以分为Java,DB,框架,其他)。 再后面的板块,就是写自己的项目或者实习经历。接着写自己的获奖情况。最后写自己的个人说明。 如果有个人博客或者Github写的比较好,这当然也是加分项。 参考资料 这里不贴具体的面试题了,大家有需要可以到我的公众号里拿:王星星的魔灯 下面是我面试时候的参考资料,希望对大家有帮助 Google(https://www.google.com ):Google和Baidu无疑对大家的帮助是最大的,遇到问题不要动不动就问别人,问之前要想一想自己能不能通过其他途径搜索到。 Hollis的个人博客/知识星球/公众号(http://www.hollischuang.com ):H哥的博客和直面Java帮我梳理了Java体系,非常感激! 王星星的魔灯(https://blog.csdn.net/coder_what ):这个是我的博客,里面记录了我的成长过程 田小波的技术博客(http://www.tianxiaobo.com/ ):这位大牛的博客我是在百度的过程中偶然发现的,也非常不错 IdeaBuffer(http://ideabuffer.cn/categories/%E5%BC%80%E5%8F%91%E6%89%8B%E5%86%8C/J-U-C/ ):同上 JavaGuide(https://snailclimb.gitee.io/javaguide/#/ ):面经必备 淘宝秒杀系统设计(https://yq.aliyun.com/articles/64762 ):可以对J2EE的秒杀设计有一个非常好的了解 写到最后 其实说实话,我最开始准备春招的时候根本没想过去阿里实习,我记得我同桌之前还问我如果XX(另一个互联网公司)要我我去不去,当时我还跟他说怎么可能不去,XX要我我就谢天谢地了。 我记得在第一面试的时候我牙都是哆嗦的,具体的面经在我公众号上有写。 在面试过程中经历了许多场情绪波动,面试过了高兴,面试失败难过,怀疑自己。 现在想想,其实面试也是一种历练自己的过程,提高自己对情绪的掌控能力,用阿里的方言来说,就是更加皮实了。 面试其实是一种运气,有的人遇到了大牛面试官,可能问的问题比较难,有的可能又比较简单,所以千万不要轻易否定自己。同时,拿到offer之后还要尽早做规划,不能得意忘形,互联网本来就是一个持久学习的行业,不断的充实自己,才能为祖国的健康发展做贡献! 最后给大家分享几点感悟把: 保持自信,时刻告诫自己不要自卑,更不能自傲 给自己列一个计划 早睡早起 坚持坚持坚持 以上,就是作者的原文描述,看下来之后,感觉和我自己准备校招的过程很像,我当年参加校招之前的那个假期,也是只在家里面待了几天而已,其余时间都是在学校进行复习。 学习的方式也是各种刷题,然后根据笔试、面试题中的知识点,自己去翻书、找博客等,逐一趣攻破。 还有就是作者说自己没想过来阿里实习,我当时也一样,我比原作者还差一点,就是本文作者好歹是211院校的,我当时只是个双非二本的一个学生,刚开始也是想着如果能拿到一个稍微出名一点的互联网公司的Offer就满足了,只是后面在复习过程中,不断努力,最终拿到了完全超乎自己预料的Offer
-
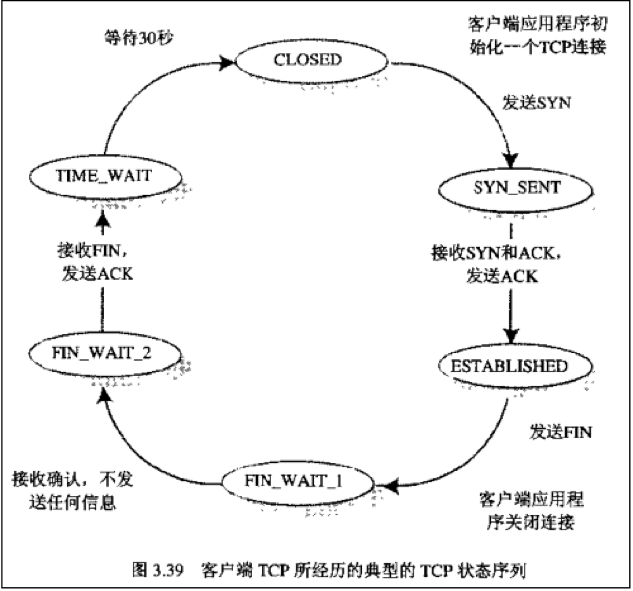
面经 | 我是如何通过校招拿到京东的Offer的。 本文来自粉丝投稿,原作者:红鼻子熊。 版权归Hollis所有。 OFFER:京东2018校招物流研发岗 个人:211小硕 面试时间:2017年秋天 整体:三轮面试,前两轮为技术面试,最后为hr面试 一面 面试时间较长,回答速度也较快,所有问题都进行了完整的回答。形式为电话面试,都是基础,难度一般,不要紧张,回答知识点即可。 内容主要包括jvm相关,网络知识(TCP/IP,DNS),JDK源码(HashMap, ArrayList, HashTable等) JVM部分 这部分主要考的是知识点的串联能力,面试官提出一个问题时,要把该问题相关的知识点都罗列出来(在说之前可以询问面试官是否需要详细讲述该知识点)。 参考书籍:深入理解Java虚拟机-周志明 神书!神书!神书!建议多刷几遍,书中的所有知识点可以通过JAVA运行时区域和JAVA的内存模型与线程两个大模块罗列完全。 常考内容有:GC,JAVA线程实现方式,volatile底层原理,线程安全,锁与CAS等 1. 讲下JAVA的运行时区域 回答:运行时数据区整体分为两类 线程私有和线程共享。 线程私有的包括: 程序计数器 若正在执行的是java方法,则计数器记录的是正在执行的字节码指令的地址 若正在执行的是native方法,则计数器为空 该区域是唯一一个不会导致outofmemoryError的区域 虚拟机栈 描述的是Java方法执行的内存模型:每个方法都会创建一个栈帧用于存储局部变量表,操作数栈,动态链接,方法出口等信息 局部变量表存放了编译期可知的基本数据类型,对象引用,和returnAddress类型(指向一条字节码指令地址),局部变量表的内存空间在编译器确定,在运行期不变 可导致两种异常:线程请求的栈深度大于虚拟机允许的深度-StackOverflowError;虚拟机无法申请到足够的内存-OutOfMemoryError 本地方法栈 和虚拟机栈类似,但它是为Native方法服务的 线程共享的包括: 堆 java堆是被所有线程共享的内存区域,在虚拟机启动时创建,用来分配对象实例和数组 堆是垃圾回收器主要管理的区域,堆可分为新生代和老年代 从内存分配角度看,堆可划分出多个线程私有的分配缓冲区(TLAB) 大小可通过 -Xmx 和 -Xms 控制 方法区 用来存放虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等信息 GC会回收该区域的常量池和进行类型的卸载 *运行时常量池 Class文件的常量池用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后存放在运行时常量池中 还把翻译出来的直接引用也放在运行时常量池中,运行时产生的常量也放在里面 2. 简单说下垃圾回收机制 大致思路: 要进行垃圾回收,首先要判断一个对象是否活着,这就引出了两种方法… 引用计数法和可达性分析法 gc roots 类型 引用类型 两次标记过程 垃圾回收算法 内存分配策略 触发垃圾回收 垃圾回收器 也会回收方法区 回答:要进行垃圾回收,首先要判断对象是否存活,引出了两个方法: 引用计数法 思想:给对象设置引用计数器,没引用该对象一次,计数器就+1,引用失效时,计数器就-1,当任意时候引用计数器的值都为0时,则该对象可被回收 Java不适用原因:无法解决对象互相循环引用的问题 可达性分析法 以GC Roots为起点,从这些起点开始向下搜索,经过的路径称为引用链。若一个对象到GC Roots之间没有任何引用链,则该对象是不可达的。 那么可作为GC Roots的对象有 虚拟机栈(栈帧中的局部变量表)中引用的对象 方法区中类静态属性引用的对象 方法区中常量引用的对象 本地方法栈中JNI(Native方法)引用的对象 在可达性分析过程中,对象引用类型会对对象的生命周期产生影响,JAVA中有这几种类型的引用: 强引用:只要该引用还有效,GC就不会回收 软引用:内存空间足够时不进行回收,在内存溢出发生前进行回收、用SoftReference类实现 弱引用:弱引用关联的对象只能存活到下一次Gc收集、用WeakReference类实现 虚引用:无法通过虚引用获得对象实例,也不会对对象的生存时间产生影响、唯一目的:当该对象被Gc收集时,收到一个系统通知。用PhantomReference类实现 一个对象真正不可用,要经历两次标记过程: 首先进行可达性分析,筛选出与GC Roots没用引用链的对象,进行第一次标记 第一次标记后,再进行一次筛选,筛选条件是是否有必要执行finalize()方法。若对象有没有重写finalize()方法,或者finalize()是否已被jvm调用过,则没必要执行,GC会回收该对象 若有必要执行,则该对象会被放入F-Queue中,由jvm开启一个低优先级的线程去执行它(但不一定等待finalize执行完毕)。 Finalize()是对象最后一次自救的机会,若对象在finalize()中重新加入到引用链中,则它会被移出要回收的对象的集合。其他对象则会被第二次标记,进行回收 JAVA中的垃圾回收算法有: 标记-清除(Mark-Sweep) 两个阶段:标记, 清除 缺点:两个阶段的效率都不高;容易产生大量的内存碎片 复制(Copying) 把内存分成大小相同的两块,当一块的内存用完了,就把可用对象复制到另一块上,将使用过的一块一次性清理掉 缺点:浪费了一半内存 标记-整理(Mark-Compact) 标记后,让所有存活的对象移到一端,然后直接清理掉端边界以外的内存 分代收集 把堆分为新生代和老年代 新生代使用复制算法 将新生代内存分为一块大的Eden区和两块小的Survivor;每次使用Eden和一个Survivor,回收时将Eden和Survivor存活的对象复制到另一个Survivor(HotSpot的比例Eden:Survivor = 8:1) 老年代使用标记-清理或者标记-整理 触发GC又涉及到了内存分配规则: (对象主要分配在Eden,若启动了本地线程分配缓冲,将优先在TLAB上分配) 对象优先在Eden分配 当Eden区没有足够的空间时就会发起一次Minor GC 大对象直接进入老年代 典型的大对象是很长的字符串和数组 长期存活的对象进入老年代 每个对象有年龄计数器,每经过一次GC,计数器值加一,当到达一定程度时(默认15),就会进入老年代 年龄的阈值可通过参数 -XX:MaxTenuringThreshold设置 对象年龄的判定 Survivor空间中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于等于该年龄的对象就可直接进入老年代,无须等到MaxTenuringThreshold要求的年龄 空间分配担保 发生Minor GC前,jvm会检查老年代最大可用的连续空间是否大于新生代所有对象总空间,若大于,则Minor GC是安全的 若不大于,jvm会查看HandlePromotionFailure是否允许担保失败,若不允许,则改为一次Full GC 若允许担保失败,则检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,若大于,则尝试进行Minor GC;若小于,则要改为Full GC 垃圾收集器: Serial(串行收集器) 特性:单线程,stop the world,采用复制算法 应用场景:jvm在Client模式下默认的新生代收集器 优点:简单高效 ParNew 特点:是Serial的多线程版本,采用复制算法 应用场景:在Server模式下常用的新生代收集器,可与CMS配合工作 Parallel Scavenge 特点:并行的多线程收集器,采用复制算法,吞吐量优先,有自适应调节策略 应用场景:需要吞吐量大的时候 SerialOld 特点:Serial的老年代版本,单线程,使用标记-整理算法 Parallel Old Parallel Scavenge的老年代版本,多线程,标记-整理算法 CMS 特点:以最短回收停顿时间为目标,使用标记-清除算法 过程: 初始标记:stop the world 标记GC Roots能直接关联到的对象 并发标记:进行GC Roots Tracing 重新标记:stop the world;修正并发标记期间因用户程序继续运作而导致标记产生变动的 那一部分对象的标记记录 并发清除:清除对象 优点:并发收集,低停顿 缺点: 对CPU资源敏感 无法处理浮动垃圾(并发清除 时,用户线程仍在运行,此时产生的垃圾为浮动垃圾) 产生大量的空间碎片 G1 特点:面向服务端应用,将整个堆划分为大小相同的region。 并行与并发 分代收集 空间整合:从整体看是基于“标记-整理”的,从局部(两个region之间)看是基于“复制”的。 可预测的停顿:使用者可明确指定在一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒。 执行过程: 初始标记:stop the world 标记GC Roots能直接关联到的对象 并发标记:可达性分析 最终标记:修正在并发标记期间因用户程序继续运作而导致标记产生变动的那一部分标记记录 筛选回收:筛选回收阶段首先对各个Region的回收价值和成本进行排序,根据用户所期望的GC停顿时间来制定回收计划 GC自适应调节策略 Parallel Scavenge收集器有一个参数-XX:+UseAdaptiveSizePolicy。当这个参数打开之后,就不需要手工指定新生代的大小、Eden与Survivor区的比例、晋升老年代对象年龄等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种调节方式称为GC自适应的调节策略(GC Ergonomics)。 (垃圾回收器部分重点讲CMS和G1) 最后提一下也会回收方法区: 永久代中主要回收两部分内容:废弃常量和无用的类 废弃常量回收和对象的回收类似 无用的类需满足3个条件 该类的所有实例对象已被回收 加载该类的ClassLoader已被回收 该类的Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法 上面的知识点在你多刷几遍书,脑中形成相应的知识网后能很全面的说出来。 网络部分 网络知识在面试中非常重要,尤其是TCP,DNS,HTTP等知识点。 该部分我的参考书籍是:图解HTTP,图解TCP/IP(对于开发来说,这两本书在网络方面的讲解应该够用了),以及相关博客。 回答该类问题时,依然要从面试官提到的问题进行扩散,把相关的问题自己抛出来进行讲述(在抛出讲述时可以询问面试官是否需要进行详细的讲解) 1. 讲一下TCP三次握手 对于该问题,可以直接关联TCP四次分手进行回答。若是当场面试,可以在纸上画出客户端和服务端的TCP状态序列 (图片来源:当时看的博客,但没能记住具体的博客地址) 然后自己可以抛出相关的问题进行回答,如: 为什么不采用两次握手,SYN半连接攻击,TIME_WAIT数量太多怎么办,为什么连接的时候是3次握手,关闭的时候是4次分手,为什么TIME_WAIT状态需要经过2MSL(最大报文段生存时间)才能回到CLOSE状态等等问题(这些问题在网上都有讲解,这里就不赘述了)。 2. TCP和UDP的区别(很常见的问题): TCP面向连接(如打电话要先拨号建立连接) UDP是无连接的,即发送数据之前不需要建立连接 TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付 TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的 UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等) 每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信 TCP首部开销20字节;UDP的首部开销小,只有8个字节 TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道 3. 讲下ARP原理 根据目标Ip地址借助ARP请求和ARP响应来确定目标的MAC地址 原理:通过广播发送ARP请求,Ip地址一致的主机接收该请求,然后将自己的MAC地址加入的ARP响应包返回给源主机。要进行MAC地址缓存来避免占用网络流量 每个主机都会在自己的ARP缓冲区建立一个ARP列表,表示Ip地址和MAC地址的对应关系 当源主机要发送数据时,首先检查ARP列表中是否有对应Ip地址的目标主机的MAC地址,若有,则直接发送,若无,则向本网段的所有主机发送ARP数据包,该数据包包括的内容有:源Ip地址,源MAC地址,目标主机Ip地址 当本网络的所有主机收到该ARP数据包时,首先检查书包中的Ip地址是否是自己的Ip地址,若不是则丢弃,若是,则首先从数据包中取出源主机的IP和MAC地址写入自己的ARP列表中,若已存在,则覆盖;然后将自己的MAC地址写入ARP响应包中,告诉源主机自己的MAC地址 源主机收到ARP响应包后,将目标主机的IP和MAC地址写入ARP列表中。若源主机一直没有收到ARP响应,则ARP查询失败 (广播发送ARP请求,单播发送ARP响应) 此时,自己可以加上ARP攻击及免费ARP相关知识点(可自行搜索) JDK源码部分 这部分主要在于自己平时的积累,可以跟着相关的博客看源码。常考的内容有String,集合框架,foreach(Iterator及fail-fast机制)等内容。 1. HashMap了解吗,说一下 这里就不详细说了,大致思路是jdk7和jdk8的实现原理及区别(重点有实现的数据结构,存储单元从Entry到Node的转变,加载因子,什么时候扩容,jdk1.8扩容的具体实现方式等等),HashMap和HashTable的区别,HahsMap和HashSet的关系。要结合源码说。 ArrayList了解吗,说一下 重点是底层实现方式,扩容机制,以及LinkedList的底层实现方式;它们之间的区别。要结合源码说 二面 面试时间不长,个别问题回答的有些底虚。主要考察的是知识面的广度和对技术的热爱程度,以及对做过项目的熟悉程度。还是那句话,坦诚地回答问题,不会就是不会,如果假装会但是被接下来地问题问倒的话,那就没戏了。 实习时项目的相关问题 每个人的项目都不同,只列举几个问题 项目是怎样预防sql注入的 回答:用的是mybatis,sql语句中用#{},#{}表示一个占位符号,通过#{}可以实现preparedStatement向占位符中设置值,jdbc有个预编译的过程可以有效预防sql注入,尽量不用${},它是个拼接符,用来拼接sql字符串。 项目中你做到的redis缓存相关的切面配置(简历中有写) 切面分析:@Aspect 切面: 查询前先查询redis,若查询不到,则查数据库,得到数据后存到redis中 目标方法:查询数据库 前置:查询之前先查redis 后置:从数据库中查到的内容放到redis中 切面中的通知定位环绕通知:@Around 然后又问了aop的实现原理(jdk动态代理和cglib字节码增强,在回答时要说出底层源码) 喜欢什么技术 答:分布式,实习时虽然自己做的是企业后台,并没有涉及到很多分布式的内容,但是会经常从同事那里了解一些分布式的技术感觉很有趣 都了解到了哪些分布式的技术 答:进行反向代理和负载均衡的nginx,及实现高可用的keepalived+nginx;内存数据库redis及它的基本数据类型和持久化方式;用于做注册中心的zookeeper和服务治理的dubbo;防止用户重复登录的单点登录;分布式的文件存储系统fastdfs;页面静态化处理的freemarker;以及用于搜索的solr(这部分由于有些技术自己只是会用,不了解底层,所以说的吞吞吐吐,很没底气,其实没必要,大大方方说出来后再说明自己了解的程度即可) 感觉自己哪方面有欠缺 答:spring源码不太了解,另外linux方面有些薄弱,正在补充相关知识。(可以加上自己目前正在看哪些书) jdk9有哪些认识 答:不太清楚,还没了解(内心状态:卧槽,jdk9什么时候出来的) (这个问题可以很好的了解到求职者对技术的热爱程度,平时可以多关注技术的发展方向,版本迭代。这方面可以通过关注一些优质的公众号:如Hollis) 为什么想来互联网公司 答:可能是第一份实习工作的影响吧, 面试官:还有呢? 我:我也说不清楚,就是想去互联网公司(说完之后就想宰了自己) HR面 hr面重要的也是真诚,还有就是表达好自己想去该公司及对该公司的了解 目前有几个offer 答:1个,但是已经拒了 为什么拒了 答:因为它不是互联网公司 你为什么想在互联网公司发展 答:工资高是一方面,另外在互联网公司中一般可以更快接触到新的技术 为什么想来京东 答:因为京东是我关注很久的公司,从京东第一次做秋招视频直播就开始关注了。首先京东是一家互联网公司,其次京东近些年的发展有目共睹,而且京东正在向技术公司转型,相信自己可以学到很多东西。 你有什么缺点 答:压力大时喜欢通过吃东西来排解压力,所以又要减肥什么的很麻烦 还有呢 答:喜欢熬夜 还有呢 答:emmmm,哎呀,想不起来了 (其实,关于优点和缺点的问题应该好好总结一下,不然问的当时容易懵逼) 还有几个问题不太记得了,大概就是实习时自己意见和同事不一样时是怎么解决的。对于这种问题,最好举个实际的例子。 总结 其实网上的大多数面经已经说的很清楚,一定要形成自己的知识树,如果仅仅想通过看面经来通过面试,会很难。自己平常一定要积累知识,把知识点分类进行记录,在面试过程中主动说出面试官所提问题的关联问题的解决方案能够加分,体现自己的知识串联能力。关于要积累哪些知识,Hollis在他的java成神之路已经写的很详细。 书就不详细写了,毕竟自己看的书不算多。
-
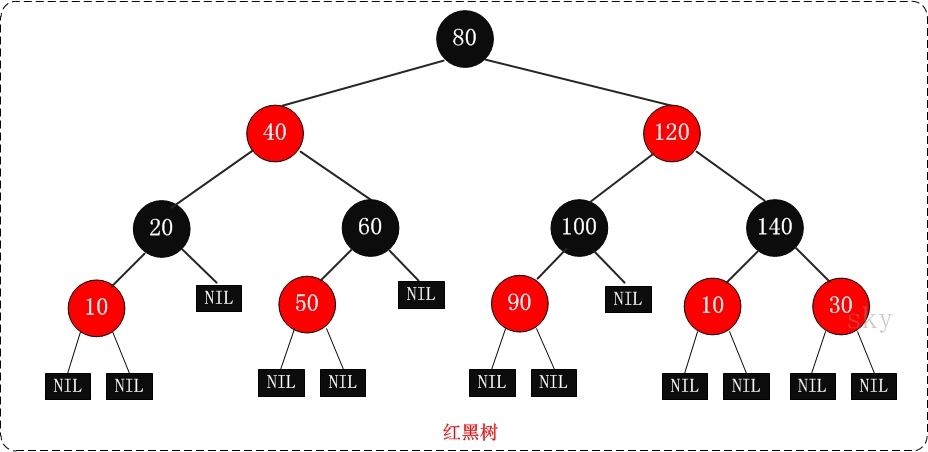
一份还热乎的蚂蚁面经(已拿Offer)!附答案!! 本文来自我的知识星球的球友投稿,他在最近的校招中拿到了蚂蚁金服的实习生Offer,整体思路和面试题目由作者——泽林提供,部分答案由Hollis整理自知识星球《Hollis和他的朋友们》中「直面Java」板块。 经历了漫长一个月的等待,终于在前几天通过面试官获悉已被蚂蚁金服录取,这期间的焦虑、痛苦自不必说,知道被录取的那一刻,一整年的阴霾都一扫而空了。 笔者面的是阿里的Java研发工程师岗,面试流程是3轮技术面+1轮hr面。 意外的一面 一面的时候大概是3月12号,面完等了差不多半个月才突然接到二面面试官的电话。一面可能是简历面,所以问题比较简单。 ArrayList和LinkedList区别 ArrayList 是一个可改变大小的数组.当更多的元素加入到ArrayList中时,其大小将会动态地增长.内部的元素可以直接通过get与set方法进行访问,因为ArrayList本质上就是一个数组. LinkedList 是一个双链表,在添加和删除元素时具有比ArrayList更好的性能.但在get与set方面弱于ArrayList. 当然,这些对比都是指数据量很大或者操作很频繁的情况下的对比,如果数据和运算量很小,那么对比将失去意义. 什么情况会造成内存泄漏 在Java中,内存泄漏就是存在一些被分配的对象,这些对象有下面两个特点: 首先,这些对象是可达的,即在有向图中,存在通路可以与其相连; 其次,这些对象是无用的,即程序以后不会再使用这些对象。 如果对象满足这两个条件,这些对象就可以判定为Java中的内存泄漏,这些对象不会被GC所回收,然而它却占用内存。 什么是线程死锁,如何解决 产生死锁的条件有四个: 1.互斥条件:所谓互斥就是进程在某一时间内独占资源。 2.请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。 3.不剥夺条件:进程已获得资源,在末使用完之前,不能强行剥夺。 4.循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。 线程死锁是因为多线程访问共享资源,由于访问的顺序不当所造成的,通常是一个线程锁定了一个资源A,而又想去锁定资源B;在另一个线程中,锁定了资源B,而又想去锁定资源A以完成自身的操作,两个线程都想得到对方的资源,而不愿释放自己的资源,造成两个线程都在等待,而无法执行的情况。 要解决死锁,可以从死锁的四个条件出发,只要破坏了一个必要条件,那么我们的死锁就解决了。在java中使用多线程的时候一定要考虑是否有死锁的问题哦。 红黑树是什么?怎么实现?时间复杂度 红黑树(Red-Black Tree,简称R-B Tree),它一种特殊的二叉查找树。 红黑树是特殊的二叉查找树,意味着它满足二叉查找树的特征:任意一个节点所包含的键值,大于等于左孩子的键值,小于等于右孩子的键值。 除了具备该特性之外,红黑树还包括许多额外的信息。 红黑树的每个节点上都有存储位表示节点的颜色,颜色是红(Red)或黑(Black)。 红黑树的特性: (1) 每个节点或者是黑色,或者是红色。 (2) 根节点是黑色。 (3) 每个叶子节点是黑色。 (4) 如果一个节点是红色的,则它的子节点必须是黑色的。 (5) 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。 关于它的特性,需要注意的是: 第一,特性(3)中的叶子节点,是只为空(NIL或null)的节点。 第二,特性(5),确保没有一条路径会比其他路径长出俩倍。因而,红黑树是相对是接近平衡的二叉树。  具体实现代码这里不贴了,要实现起来,需要包含的基本操作是添加、删除和旋转。在对红黑树进行添加或删除后,会用到旋转方法。旋转的目的是让树保持红黑树的特性。旋转包括两种:左旋 和 右旋。 红黑树的应用比较广泛,主要是用它来存储有序的数据,它的查找、插入和删除操作的时间复杂度是O(lgn)。 TCP三次握手 三次握手(three times handshake;three-way handshake)所谓的“三次握手”即对每次发送的数据量是怎样跟踪进行协商使数据段的发送和接收同步,根据所接收到的数据量而确定的数据确认数及数据发送、接收完毕后何时撤消联系,并建立虚连接。 为了提供可靠的传送,TCP在发送新的数据之前,以特定的顺序将数据包的序号,并需要这些包传送给目标机之后的确认消息。TCP总是用来发送大批量的数据。当应用程序在收到数据后要做出确认时也要用到TCP。  第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态; 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。 突如其来的二面 一面的时候大概是3月12号,面完等了差不多半个月才突然接到二面面试官的电话。 介绍项目 Storm怎么保证一致性 Storm是一个分布式的流处理系统,利用anchor和ack机制保证所有tuple都被成功处理。如果tuple出错,则可以被重传,但是如何保证出错的tuple只被处理一次呢?Storm提供了一套事务性组件Transaction Topology,用来解决这个问题。 Transactional Topology目前已经不再维护,由Trident来实现事务性topology,但是原理相同。 参考:https://cloud.tencent.com/info/5721fb4532f6a72ed2e563f9449fd025.html 说一下hashmap以及它是否线程安全 HashMap基于哈希表的 Map 接口的实现。HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。HashMap中hash数组的默认大小是16,而且一定是2的指数。Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。 HashMap 实现 Iterator,支持fast-fail。 哈希表是由数组+链表组成的,它是通过把key值进行hash来定位对象的,这样可以提供比线性存储更好的性能。  HashMap不是线程安全的。 十亿条淘宝购买记录,怎么获取出现最多的前十个 这是一道典型的有限内存的海量数据处理的题目。一般这类题目的解答无非是以下几种: 分治,hash映射,堆排序,双层桶划分,Bloom Filter,bitmap,数据库索引,mapreduce等。 具体情形都有很多不同的方案。这类题目可以到网上搜索一下,了解下套路,后面就基本都会了。 平时有没有用linux系统,怎么查看某个进程 ps aux|grep java 查看java进程 ps aux 查看所有进程 ps –ef|grep tomcat 查看所有有关tomcat的进程 ps -ef|grep --color java 高亮要查询的关键字 kill -9 19979 终止线程号位19979的进程 说一下Innodb和MySIAM的区别 MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持。MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持,而InnoDB提供事务支持以及外部键等高级数据库功能。 InnoDB不支持FULLTEXT类型的索引。 InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count(*)语句包含 where条件时,两种表的操作是一样的。 对于AUTO_INCREMENT类型的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中,可以和其他字段一起建立联合索引。 DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。 LOAD TABLE FROM MASTER操作对InnoDB是不起作用的,解决方法是首先把InnoDB表改成MyISAM表,导入数据后再改成InnoDB表,但是对于使用的额外的InnoDB特性(例如外键)的表不适用。 说一下jvm内存模型,介绍一下你了解的垃圾收集器 其实并没有jvm内存模型的概念。应该是Java内存模型或者jvm内存结构,这里面试者一定要听清楚问的是哪个,再回答。 可以参考:JVM内存结构 VS Java内存模型 VS Java对象模型 你说你是大数据方向的,了解哪些大数据框架 作者回答了一些zookeeper、storm、HDFS、Hbase等 其他问题 100个有序的整型,如何打乱顺序? 如何设计一个可靠的UDP协议? 二面大概就是这些,其中storm一致性这个问题被面试官怀疑了一下,就有点紧张,其实没答错,所以还是要对知识掌握得更明确才行。 准备充足的三面 清明节的时候例外地没有回家扫墓,因为知道自己的弱项是操作系统和海量数据题这块,所以想着恶补这方面的知识,不过之后的面试意外的并没有问到这方面的内容。 介绍项目 项目介绍完之后没问太多 介绍一下hashmap HashMap真的是面试高频题,多次面试都问到了,一定要掌握。 介绍一下并发 这里可以把整个并发的体系都说下,包括volatile、synchronized、lock、乐观悲观锁、锁膨胀、锁降级、线程池等 银行账户读写怎么做 我说了读写锁以及可能出现死锁问题 说一下关系型数据库和非关系型数据库的区别 非关系型数据库的优势: 1、性能 NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高 2、可扩展性 同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。 3、使用场景:日志、埋点、论坛、博客等 关系型数据库的优势: 1、 复杂查询 可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询 2、事务支持 使得对于安全性能很高的数据访问要求得以实现。 3、使用场景:所有有逻辑关系的数据存储 如何访问链表中间节点 对于这个问题,我们首先能够想到的就是先遍历一遍整个的链表,然后计算出链表的长度,进而遍历第二遍找出中间位置的数据。这种方式非常简单。 若题目要求只能遍历一次链表,那又当如何解决问题? 可以采取建立两个指针,一个指针一次遍历两个节点,另一个节点一次遍历一个节点,当快指针遍历到空节点时,慢指针指向的位置为链表的中间位置,这种解决问题的方法称为快慢指针方法。 说下进程间通信,以及各自的区别 进程间通信是指在不同进程之间传播或交换信息。方式通常有管道(包括无名管道和命名管道)、消息队列、信号量、共享存储、Socket、Streams等。 访问淘宝网页的一个具体流程,从获取ip地址,到怎么返回相关内容 先通过DNS解析到服务器地址,然后反向代理、负载均衡服务器等,寻找集群中的一台机器来真正执行你的请求。还可以介绍CDN、页面缓存、Cookie以及session等。 这个过程还包括三次握手、HTTP request中包含哪些内容,状态码等,还有OSI七层分层可以介绍。 服务器接到请求后,会执行业务逻辑,执行过程中可以按照MVC来分别介绍。 服务处理过程中是否调用其他RPC服务或者异步消息,这个过程包含服务发现与注册,消息路由。 最后查询数据库,会不会经过缓存?是不是关系型数据库?是会分库分表还是做哪些操作? 对于数据库,分库分表如果数据量大的话是有必要的,一般业务根据一个分表字段进行取模进行分表,而在做数据库操作的时候,也根据同样的规则,决定数据的读写操作对应哪张表。这种也有开源的实现的,如阿里的TDDL就有这种功能。分库分表还涉及到很多技术,比如sequence如何设置 ,如何解决热点问题等。 最后再把处理结果封装成response,返回给客户端。浏览器再进行页面渲染。 焦虑的hr面 之所以说hr面焦虑,是因为面试前我还在看IG的半决赛(实在复习不下),接到电话的时候分外紧张,在一些点上答得很差。 遇到什么挫折 这种问题主要考察面试者遇见困难是否能坚持下去,并且可以看出他的解决问题的能力。 可以简单描述挫折,并说明自己如何克服,最终有哪些收获。 职业规划 表名自己决心,首先自己不准备继续求学了,必须招工作了。然后说下自己不会短期内换行业,或者换工作,自己比较喜欢,希望可以坚持几年看自己的兴趣再规划之类的。 对阿里的认识 这个比较简答,夸就行了。 有什么崇拜的人吗 我说了詹姆斯哈登,hr小姐姐居然笑了。 这个可以说一些IT大牛。 希望去哪里就业 这个问题果断回答该公司所在的城市啊。 其他问题 有什么兴趣爱好,能拿得上台表演的有吗 记忆深刻的事情 总结 提前批更多的是考察基础知识,大公司都有自己在用的框架,你进去后基本上得重新学这些框架,所以对他们来说,基础是否扎实才是考察的关键。 基础包括:操作系统、linxu、数据库、数据结构、算法、java(基础、容器、高并发、jvm)、计算机网络等 建议要投资知识,从寒假到现在,先后买了9个极客时间的课程、订阅了H神的知识星球、当当买了四五本相关技术书籍… 虽然购买的课很多还来不及读(惭愧) 当时我问一个java群的师兄,学不下了怎么办,他说,换种姿势继续学,还别说,有时候失眠的时候,我都在看极客时间或知识星球催眠自己… 要对知识做好总结,虽然以前也有记录简书的习惯,但是大多数时候都是写了不发表,自己做一个记忆的作用,3月份我给自己的要求就是,对每个知识点要做到能够有自己的理解,然后写一篇质量较好的博客总结。 面试建议是,一定要自信,敢于表达,面试的时候我们对知识的掌握有时候很难面面俱到,把自己的思路说出来,而不是直接告诉面试官自己不懂,这也是可以加分的。 最后 总之,可以拿到蚂蚁金服的offer真的很意外,也很幸运,蚂蚁金服从来是我觉得很难达到的目标,但它确实发生了,也许这就是幸福来敲门吧,我可以给到自己或其他人的建议就是,一定要把握好时机。 Don’t ever let somebody tell you you can’t do something, not even me. You got a dream, you gotta protect it. People can’t do something by themselves,they wanna tell you you can not do it. If You want something. Go get it!
-
阿里的简历多久可以投递一次?次数多了有没有影响?可以同时进行吗? 最近,无论是读者群,还是公众号后台,很多人都比较关注以下几个问题: 阿里的简历是半年只能投递一次吗? 阿里的面试可以多个部门同时进行吗? 面试没过,又被系统捞起来了,我该怎么办? 是不是面试越多,成功几率越大? 阿里的一次面试不过,对后续面试有没有影响? 今天,就来简单回答下这几个问题吧。观点只代表我个人理解,并不代表阿里的官方政策。 阿里的面试可以多个部门同时进行吗? 不行 阿里的面试是要走系统流程的,系统上面有严格的控制,一个人在同一时间只能在一个面试流程中,没办法同时面试多个部门。 有些人说自己曾经同时面试过多个部门,这是怎么回事儿? 那肯定是因为有的部门面试时没有把你录入系统,而是直接面的,系统上面是没办法同时进行的。 阿里的简历多久可以投递一次? 据我所知,同一个人在一个月内最多被内部推荐的次数是有限制的,好像是5次左右。 但是除内推外其他形式的应聘应该是没有限制的。 只要没有在流程中,就可以重新投递。 投递之后,如果面试未通过,只要上一个岗位结束了面试流程,就可以继续进行下一次的面试。中间不需要有间隔。 是不是面试越多,成功几率越大? 很多人找工作的时候,会疯狂的海投很多岗位,认为面试次数越多,成功的几率越大? 其实并不完全是这样的。 对于很多大厂来说,所有的面试都是要通过系统进行的,而每一次面试记录都会在系统中被记录下来。 这些面试记录大部分都会包含面试官的评价,详细的甚至面试问的问题都会有。 所以,如果你没有准备好,同时间投递多个岗位,如果有过几次失败的经历了,后面再成功的概率就极低了。 面试没过,又被系统捞起来了,我该怎么办? 有些人投递了简历之后,被一个部门面试后没有通过,过段时间有人打电话过来询问是否再进行面试,这是什么情况?要不要面试? 这其实是被”捞起来”了,就是说面试没通过,简历会进入人才库,员工可以通过人才库搜索找到自己心怡的人员,进行重新发起面试。 首先,捞起来面试的话,也是一次新的面试,面试记录上面也会充分体现出来,和普通的投递没啥区别。 所以,如果你第一次面试没过,并且你觉得自己还差的挺远的,那么当你被捞起来之后,我建议你直接拒绝。 可以说暂不考虑新的职位,或者说没有换工作意向等。 这时候系统上同样会有响应的标注,这样在短期内,就不会被再次捞起来了。 什么时候准备好了,再重新投递就行了。 阿里的一次面试不过,对后续面试有没有影响? 这个问题前面也大概提到了 肯定是有影响的,很多时候,面试官收到一份简历,会首先查看历史面试记录,如果有非常不好的评价,那么基本就直接Pass了。 所以,强烈建议一定要做好准备之后再开始投递简历以及面试,不要抱着试试看的心理。 总结 以上就是大家比较关心的几个问题,我的一些理解和建议。下一次我会再分享以下几个话题: 面试阿里,部门选择重要吗? 投阿里的简历,怎么选择部门? 找人帮忙内推之前,需要问清楚哪几个问题? 阿里面试的周期一般是多久? 大家还有什么其他的问题可以给我留言,会在下一次分享中一并回答。