找到
22
篇与
Debug
相关的结果
- 第 3 页
-
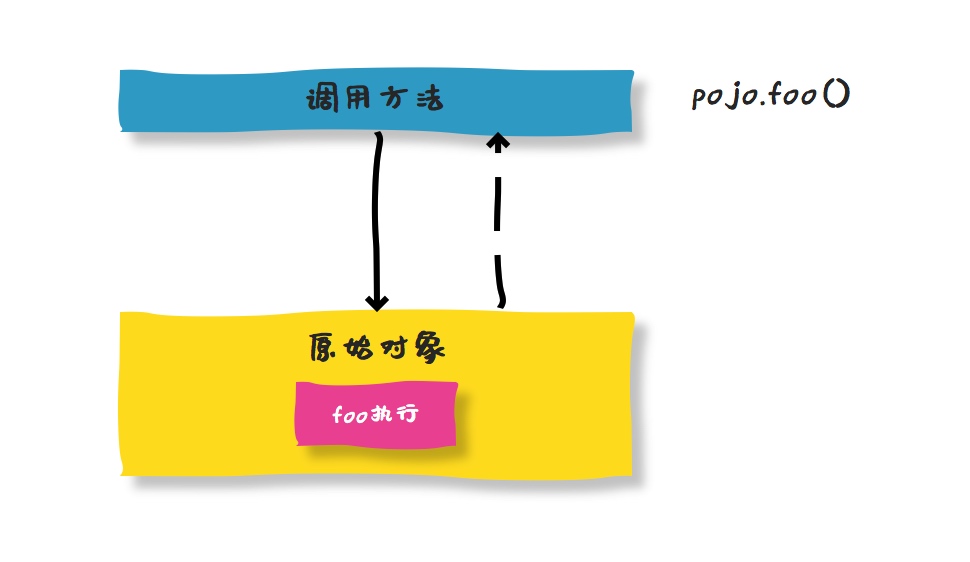
 深坑啊!同一个Spring AOP的坑,我一天踩了两次! 前几天,我刚刚发布过一篇文章《自定义注解!绝对是程序员装逼的利器!!》,介绍过如何使用Spring AOP + 自定义注解来提升代码的优雅性。 很多读者看完之后表示用起来很爽,但是后台也有人留言说自己配置了Spring的AOP之后,发现切面不生效。 其实,这个问题我在用的过程中也遇到过,而且还是同一个问题一天之内遇到了两次。 说明这个问题很容易被忽略,并且这个问题带来的后果可能是极其严重的。那么,我们就来简单回顾一下问题是怎么样的。 问题重现 最初我定义了一个注解,希望可以方便统一的对一些数据库操作做缓存。于是就有了以下代码: 首先,定义一个注解: @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface Cacheable { /** * 策略名称,需要保证唯一 * * @return */ public String keyName(); /** * 超时时长,单位:秒 * * @return */ public int expireTime(); } 然后自定义一个切面,对所有使用了该注解的方法进行切面处理: @Aspect @Component public class CacheableAspect { private static final Logger LOGGER = LoggerFactory.getLogger(FacadeAspect.class); @Around("@annotation(com.hollis.cache.Cacheable)") public Object cache(ProceedingJoinPoint pjp) throws Throwable { // 先查缓存,如果缓存中有值,直接返回。如果缓存中没有,先执行方法,再将返回值存储到缓存中。 } } 然后就可以使用该注解了,使用方法如下: @Component public class StrategyService extends BaseStrategyService { public PricingResponse getFactor(Map pricingParams) { // 做一些参数校验,以及异常捕获相关的事情 return this.loadFactor(tieredPricingParams); } @Override @Cacheable(keyName = "key0001", expireTime = 60 * 60 * 2) private PricingResponse loadFactor(Map pricingParams) { //代码执行 } } 以上,对loadFactor方法增加了切面,为了方便使用,我们还定义了一个getFactor方法,设置为public,方便外部调用。 但是,在调试过程中,我发现我们设置在loadFactor方法上面的切面并没有成功,无法执行切面类。 于是开始排查问题具体是什么。 问题排查 为了排查这个问题,首先是把所有的代码检查一遍,看看切面的代码是不是有问题,有没有可能有手误打错了字之类的。 但是发现都没有。于是就想办法找找问题。 接下来我把loadFactor的访问权限从private改成public,发现没有效果。 然后我尝试着在方法外直接调用loadFactor而不是getFactor。 发现这样做就可以成功的执行到切面里面了。 发现这一现象的时候,我突然恍然大悟,直捶大腿。原来如此,原来如此,就应该是这样的。 我突然就想到了问题的原因。其实原因挺简单的,也是我之前了解到过的原理,但是在问题刚刚发生的时候我并没有想到这里,而是通过debug,发现这个现象之后我才突然想到这个原理。 那么,就来说说为什么会发生这样的问题。 代理的调用方式 我们发现上面的问题关键在于loadFactor方法被调用的方式不同。我们知道,方法的调用通常有以下几种方式: 1、在类内部,通过this进行自调用: public class SimplePojo implements Pojo { public void foo() { // this next method invocation is a direct call on the 'this' reference this.bar(); } public void bar() { // some logic... } } 2、在类外部,通过该类的对象进行调用 public class Main { public static void main(String[] args) { Pojo pojo = new SimplePojo(); // this is a direct method call on the 'pojo' reference pojo.foo(); } } 类关系及调用过程中如下图:  如果是静态方法,也可以通过类直接调用。 3、在类外部,通过该类的代理对象进行调用: public class Main { public static void main(String[] args) { ProxyFactory factory = new ProxyFactory(new SimplePojo()); factory.addInterface(Pojo.class); factory.addAdvice(new RetryAdvice()); Pojo pojo = (Pojo) factory.getProxy(); // this is a method call on the proxy! pojo.foo(); } } 类关系及调用过程中如下图:  那么,Spring的AOP其实是第三种调用方式,就是通过代理对象调用,只有这种调用方式,才能够在真正的对象的执行前后,能够让代理对象也执行相关代码,才能起到切面的作用。 而对于使用this的方式调用,这种只是自调用,并不会使用代理对象进行调用,也就无法执行切面类。 问题解决 那么,我们知道了,想要真正的执行代理,那么就需要通过代理对象进行调用而不是使用this调用的方式。 那么,这个问题的解决办法也就是想办法通过代理对象来调用目标方法即可。 这种问题的解决网上有很多种办法,这里介绍一个相对简单的。其他的更多的办法大家可以在网上找到一些案例。搜索关键词”AOP 自调用”即可。 获取代理对象进行调用 我们需要修改一下前面的StrategyService的代码,修改成以下内容: @Component public class StrategyService{ public PricingResponse getFactor(Map pricingParams) { // 做一些参数校验,以及异常捕获相关的事情 // 这里不使用this.loadFactor而是使用AopContext.currentProxy()调用,目的是解决AOP代理不支持方法自调用的问题 if (AopContext.currentProxy() instanceof StrategyService) { return ((StrategyService)AopContext.currentProxy()).loadFactor(tieredPricingParams); } else { // 部分实现没有被代理过,则直接进行自调用即可 return loadFactor(tieredPricingParams); } } @Override @Cacheable(keyName = "key0001", expireTime = 60 * 60 * 2) private PricingResponse loadFactor(Map oricingParams) { //代码执行 } } 即使用AopContext.currentProxy()获取到代理对象,然后通过代理对象调用对应的方法。 还有个地方需要注意,以上方式还需要将Aspect的expose-proxy设置成true。如果是配置文件修改: 如果是SpringBoot,则修改应用启动入口类的注解: @EnableAspectJAutoProxy(exposeProxy = true) public class Application { } 总结 以上,我们分析并解决了一个Spring AOP不支持方法自调用的问题。 AOP失败这个问题,其实还是很严重的,因为如果发生非预期的失效,那么直接问题就是没有执行切面方法,更严重的后果可能是诸如事务未生效、日志未打印、缓存未查询等各种问题。 所以,还是建议大家看完此文之后,统查一下自己的代码,是否存在方法自调用的情况。这种情况下,任何切面都是无法生效的!
深坑啊!同一个Spring AOP的坑,我一天踩了两次! 前几天,我刚刚发布过一篇文章《自定义注解!绝对是程序员装逼的利器!!》,介绍过如何使用Spring AOP + 自定义注解来提升代码的优雅性。 很多读者看完之后表示用起来很爽,但是后台也有人留言说自己配置了Spring的AOP之后,发现切面不生效。 其实,这个问题我在用的过程中也遇到过,而且还是同一个问题一天之内遇到了两次。 说明这个问题很容易被忽略,并且这个问题带来的后果可能是极其严重的。那么,我们就来简单回顾一下问题是怎么样的。 问题重现 最初我定义了一个注解,希望可以方便统一的对一些数据库操作做缓存。于是就有了以下代码: 首先,定义一个注解: @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface Cacheable { /** * 策略名称,需要保证唯一 * * @return */ public String keyName(); /** * 超时时长,单位:秒 * * @return */ public int expireTime(); } 然后自定义一个切面,对所有使用了该注解的方法进行切面处理: @Aspect @Component public class CacheableAspect { private static final Logger LOGGER = LoggerFactory.getLogger(FacadeAspect.class); @Around("@annotation(com.hollis.cache.Cacheable)") public Object cache(ProceedingJoinPoint pjp) throws Throwable { // 先查缓存,如果缓存中有值,直接返回。如果缓存中没有,先执行方法,再将返回值存储到缓存中。 } } 然后就可以使用该注解了,使用方法如下: @Component public class StrategyService extends BaseStrategyService { public PricingResponse getFactor(Map pricingParams) { // 做一些参数校验,以及异常捕获相关的事情 return this.loadFactor(tieredPricingParams); } @Override @Cacheable(keyName = "key0001", expireTime = 60 * 60 * 2) private PricingResponse loadFactor(Map pricingParams) { //代码执行 } } 以上,对loadFactor方法增加了切面,为了方便使用,我们还定义了一个getFactor方法,设置为public,方便外部调用。 但是,在调试过程中,我发现我们设置在loadFactor方法上面的切面并没有成功,无法执行切面类。 于是开始排查问题具体是什么。 问题排查 为了排查这个问题,首先是把所有的代码检查一遍,看看切面的代码是不是有问题,有没有可能有手误打错了字之类的。 但是发现都没有。于是就想办法找找问题。 接下来我把loadFactor的访问权限从private改成public,发现没有效果。 然后我尝试着在方法外直接调用loadFactor而不是getFactor。 发现这样做就可以成功的执行到切面里面了。 发现这一现象的时候,我突然恍然大悟,直捶大腿。原来如此,原来如此,就应该是这样的。 我突然就想到了问题的原因。其实原因挺简单的,也是我之前了解到过的原理,但是在问题刚刚发生的时候我并没有想到这里,而是通过debug,发现这个现象之后我才突然想到这个原理。 那么,就来说说为什么会发生这样的问题。 代理的调用方式 我们发现上面的问题关键在于loadFactor方法被调用的方式不同。我们知道,方法的调用通常有以下几种方式: 1、在类内部,通过this进行自调用: public class SimplePojo implements Pojo { public void foo() { // this next method invocation is a direct call on the 'this' reference this.bar(); } public void bar() { // some logic... } } 2、在类外部,通过该类的对象进行调用 public class Main { public static void main(String[] args) { Pojo pojo = new SimplePojo(); // this is a direct method call on the 'pojo' reference pojo.foo(); } } 类关系及调用过程中如下图:  如果是静态方法,也可以通过类直接调用。 3、在类外部,通过该类的代理对象进行调用: public class Main { public static void main(String[] args) { ProxyFactory factory = new ProxyFactory(new SimplePojo()); factory.addInterface(Pojo.class); factory.addAdvice(new RetryAdvice()); Pojo pojo = (Pojo) factory.getProxy(); // this is a method call on the proxy! pojo.foo(); } } 类关系及调用过程中如下图:  那么,Spring的AOP其实是第三种调用方式,就是通过代理对象调用,只有这种调用方式,才能够在真正的对象的执行前后,能够让代理对象也执行相关代码,才能起到切面的作用。 而对于使用this的方式调用,这种只是自调用,并不会使用代理对象进行调用,也就无法执行切面类。 问题解决 那么,我们知道了,想要真正的执行代理,那么就需要通过代理对象进行调用而不是使用this调用的方式。 那么,这个问题的解决办法也就是想办法通过代理对象来调用目标方法即可。 这种问题的解决网上有很多种办法,这里介绍一个相对简单的。其他的更多的办法大家可以在网上找到一些案例。搜索关键词”AOP 自调用”即可。 获取代理对象进行调用 我们需要修改一下前面的StrategyService的代码,修改成以下内容: @Component public class StrategyService{ public PricingResponse getFactor(Map pricingParams) { // 做一些参数校验,以及异常捕获相关的事情 // 这里不使用this.loadFactor而是使用AopContext.currentProxy()调用,目的是解决AOP代理不支持方法自调用的问题 if (AopContext.currentProxy() instanceof StrategyService) { return ((StrategyService)AopContext.currentProxy()).loadFactor(tieredPricingParams); } else { // 部分实现没有被代理过,则直接进行自调用即可 return loadFactor(tieredPricingParams); } } @Override @Cacheable(keyName = "key0001", expireTime = 60 * 60 * 2) private PricingResponse loadFactor(Map oricingParams) { //代码执行 } } 即使用AopContext.currentProxy()获取到代理对象,然后通过代理对象调用对应的方法。 还有个地方需要注意,以上方式还需要将Aspect的expose-proxy设置成true。如果是配置文件修改: 如果是SpringBoot,则修改应用启动入口类的注解: @EnableAspectJAutoProxy(exposeProxy = true) public class Application { } 总结 以上,我们分析并解决了一个Spring AOP不支持方法自调用的问题。 AOP失败这个问题,其实还是很严重的,因为如果发生非预期的失效,那么直接问题就是没有执行切面方法,更严重的后果可能是诸如事务未生效、日志未打印、缓存未查询等各种问题。 所以,还是建议大家看完此文之后,统查一下自己的代码,是否存在方法自调用的情况。这种情况下,任何切面都是无法生效的!
-
从漏洞中总结编程规范 最近,分析了很多由自动化工具扫描出来的代码漏洞,很多Bug都是因为我们平时写代码不注意规范导致的。更可怕的是很多时候我们并不知道那样写代码有什么问题。 今天就把这些问题总结一下。 1.非空判断 我们在代码中经常这样写: if(user.getUserName().equals("hollis")){ } 这段代码极有可能在实际运行的时候跑出NullPointerException。无论是user本身为空,还是user.getUserName()为空,都会抛出异常。 所以,在调用一个参数时要确保他是非空的。 上面的代码可以改为: if(user!=null&&"hollis".equals(user.getUserName())){ } 还有,我们可能认为在使用增强for循环进行遍历的时候不会产生空指针异常,但是,事实并不是这样的。 for(User user:userList){ } 代码可以不用判断userList是否为空,也不用判断userList.size()==0。 但是,遍历出来的user并不一定不为空。所以,在增强for循环中使用对象时也要最非空判断。 2.有些分支永远不会被运行到 要避免这种代码: if(true){ }else{ } else没有任何意义。 3.流必须要关闭 无论是什么流,都要在finally中显示的关闭。 4.用StringBuffer代替String 在循环中构建一个String对象时从性能上讲使用StringBuffer来代替String对象 例如: // This is bad String s = ""; for (int i = 0; i < field.length; ++i) { s = s + field[i]; } 应该改为StringBuffer,使用append方法: StringBuffer buf = new StringBuffer(); for (int i = 0; i < field.length; ++i) { buf.append(field[i]); } String s = buf.toString(); 5.不要调用equals方法比较不同类型的类 6.生产代码中建议不要使用System.out及System.err 7.线上代码禁止printStackTrace! 8.多线程下的安全隐患,须使用final static 修饰,避免多线程环境下对象篡改导致的bug。 9.实例方法写入了静态字段,当实例创建多次时静态字段可能会被改变。 10.实现序列化接口或父类实现序列化接口的 子类都需要声明序列化id! new ArrayList(){{ add(datasourceKey); }} 需要添加:private static final long serialVersionUID = 1L; 11.不要在类成员属性中声明simpleDateFormat StringBuilder HashMap 等线程不安全对象! 12.为局部变量赋值,但在其后的没有对她做任何使用。 变量不使用就不要定义 通常,这表明一个错误,因为值从未使用过。 13.不要在方法中对不为空的值进行为空的判断。 14.Switch语句中一个分支执行后又执行了下一个分支。 通常case后面要跟break 或者return语句来跳出。 15.精准度隐患! double最好不要用来进行计算,应该使用bigDecimal 最后,多做一些codeReview!!! 欢迎补充
-
Uncaught TypeError: Cannot call method 'toLowerCase' of undefined 出错代码: $.ajax({ type: "GET", url: 'firstRequest.json?id=' + $(this).val(), async: false, dataType: "json", success: function(data){ if(data.deleteable == "true"){ $.ajax({ type: "GET", url: 'secondRequest.json?id=' + $(this).val(), async: false, dataType: "json", success: function(data){ if(data.result=="success"){ alert("删除成功"); reloadPage(); }else{ alert("删除失败"); } }, error: function(XMLHttpRequest, textStatus, errorThrown) { alert("请求失败!"); } }); }else{ alert("无法删除!!!"); return false; } }, error: function(XMLHttpRequest, textStatus, errorThrown) { alert("请求失败!"); } }); 修改之后代码 var clicked = this; $.ajax({ type: "GET", url: 'firstRequest.json?id=' + $(clicked).val(), async: false, dataType: "json", success: function(data){ if(data.deleteable == "true"){ $.ajax({ type: "GET", url: 'secondRequest.json?id=' + $(clicked).val(), async: false, dataType: "json", success: function(data){ if(data.result=="success"){ alert("删除成功"); reloadPage(); }else{ alert("删除失败"); } }, error: function(XMLHttpRequest, textStatus, errorThrown) { alert("请求失败!"); } }); }else{ alert("无法删除!!!"); return false; } }, error: function(XMLHttpRequest, textStatus, errorThrown) { alert("请求失败!"); } });
-
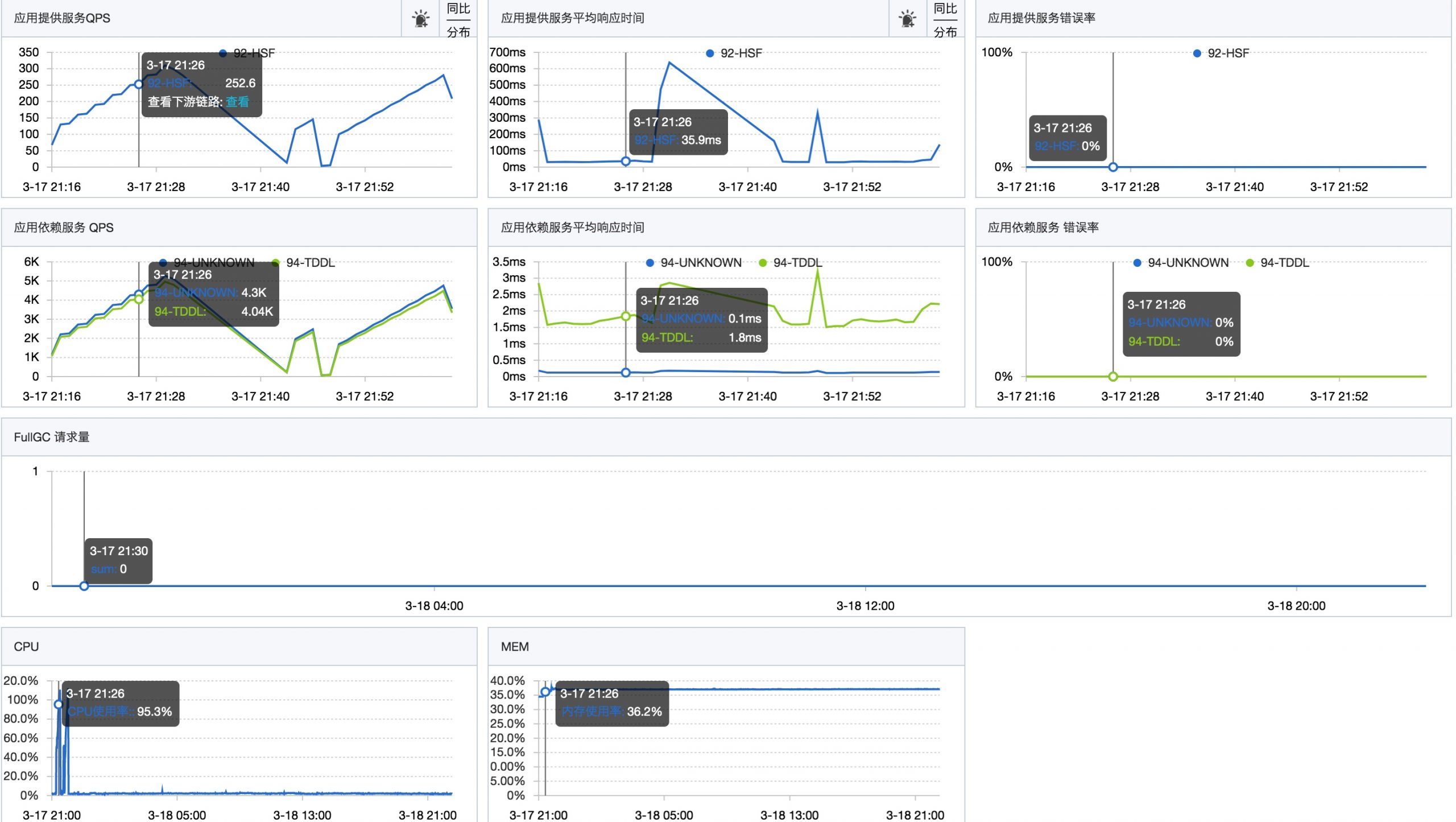
你要偷偷学会排查线上CPU飙高的问题,然后惊艳所有人! 前段时间我们新上了一个新的应用,因为流量一直不大,集群QPS大概只有5左右,写接口的rt在30ms左右。 因为最近接入了新的业务,业务方给出的数据是日常QPS可以达到2000,大促峰值QPS可能会达到1万。 所以,为了评估水位,我们进行了一次压测。压测在预发布环境执行。压测过程中发现,当单机QPS达到200左右时,接口的rt没有明显变化,但是CPU利用率急剧升高,直到被打满。 压测停止后,CPU利用率立刻降了下来。 于是开始排查是什么导致了CPU的飙高。 问题排查与解决 在压测期间,登录到机器,开始排查问题。 本案例的排查过程使用的阿里开源的Arthas工具进行的,不使用arthas,使用JDK自带的命令也是可以。 在开始排查之前,可以先看一下CPU的使用情况,最简单的就是使用top命令直接查看: top - 10:32:38 up 11 days, 17:56, 0 users, load average: 0.84, 0.33, 0.18 Tasks: 23 total, 1 running, 21 sleeping, 0 stopped, 1 zombie %Cpu(s): 95.5 us, 2.2 sy, 0.0 ni, 76.3 id, 0.0 wa, 0.0 hi, 0.0 si, 6.1 st KiB Mem : 8388608 total, 4378768 free, 3605932 used, 403908 buff/cache KiB Swap: 0 total, 0 free, 0 used. 4378768 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 3480 admin 20 0 7565624 2.9g 8976 S 241.2 35.8 649:07.23 java 1502 root 20 0 401768 40228 9084 S 1.0 0.5 39:21.65 ilogtail 181964 root 20 0 3756408 104392 8464 S 0.7 1.2 0:39.38 java 496 root 20 0 2344224 14108 4396 S 0.3 0.2 52:22.25 staragentd 1400 admin 20 0 2176952 229156 5940 S 0.3 2.7 31:13.13 java 235514 root 39 19 2204632 15704 6844 S 0.3 0.2 55:34.43 argusagent 236226 root 20 0 55836 9304 6888 S 0.3 0.1 12:01.91 systemd-journ 可以看到,进程ID为3480的Java进程占用的CPU比较高,基本可以断定是应用代码执行过程中消耗了大量CPU,接下来开始排查具体是哪个线程,哪段代码比较耗CPU。 首先,下载Arthas命令: curl -L http://start.alibaba-inc.com/install.sh | sh 启动 ./as.sh 使用Arthas命令”thread -n 3 -i 1000″查看当前”最忙”(耗CPU)的三个线程: 通过上面的堆栈信息,可以看出,占用CPU资源的线程主要是卡在JDBC底层的TCP套接字读取上。连续执行了很多次,发现很多线程都是卡在这个地方。 通过分析调用链,发现这个地方是我代码中有数据库的insert,并且使用TDDL来创建sequence,在sequence的创建过程中需要和数据库有交互。 但是,基于对TDDL的了解,TDDL每次从数据库中查询sequence序列的时候,默认会取出1000条,缓存在本地,只有用完之后才会再从数据库获取下一个1000条序列。 按理说我们的压测QPS只有300左右,不应该这么频繁的何数据库交互才对。但是,经过多次使用arthas的查看,发现大部分CPU都耗尽在这里。 于是开始排查代码问题。最终发现了一个很傻的问题,那就是我们的sequence创建和使用有问题: public Long insert(T dataObject) { if (dataObject.getId() == null) { Long id = next(); dataObject.setId(id); } if (sqlSession.insert(getNamespace() + ".insert", dataObject) > 0) { return dataObject.getId(); } else { return null; } } public Sequence sequence() { return SequenceBuilder.create() .name(getTableName()) .sequenceDao(sequenceDao) .build(); } /** * 获取下一个主键ID * * @return */ protected Long next() { try { return sequence().nextValue(); } catch (SequenceException e) { throw new RuntimeException(e); } } 是因为,我们每次insert语句都重新build了一个新的sequence,这就导致本地缓存就被丢掉了,所以每次都会去数据库中重新拉取1000条,但是只是用了一条,下一次就又重新取了1000条,周而复始。 于是,调整了代码,把Sequence实例的生成改为在应用启动时初始化一次。这样后面在获取sequence的时候,不会每次都和数据库交互,而是先查本地缓存,本地缓存的耗尽了才会再和数据库交互,获取新的sequence。 public abstract class BaseMybatisDAO implements InitializingBean { @Override public void afterPropertiesSet() throws Exception { sequence = SequenceBuilder.create().name(getTableName()).sequenceDao(sequenceDao).build(); } } 通过实现InitializingBean,并且重写afterPropertiesSet()方法,在这个方法中进行Sequence的初始化。 改完以上代码,提交进行验证。通过监控数据可以看出优化后,数据库的读RT有明显下降: sequence的写操作QPS也有明显下降: 于是我们开始了新的一轮压测,但是发现,CPU的使用率还是很高,压测的QPS还是上不去,于是重新使用Arthas查看线程的情况。 发现了一个新的比较耗费CPU的线程的堆栈,这里面主要是因为我们用到了一个联调工具,该工具预发布默认开启了TDDL的采集(官方文档中描述为预发布默认不开启TDDL采集,但是实际上会采集)。 这个工具在打印日志过程中会进行脱敏,脱敏框架会调用Google的re2j进行正则表达式的匹配。 因为我的操作中TDDL操作比较多,默认采集大量TDDL日志并且进行脱敏处理,确实比较耗费CPU。 所以,通过在预发布中关闭DP对TDDL的采集,即可解决该问题。 总结与思考 本文总结了一次线上CPU飙高的问题排查过程,其实问题都不难,并且还挺傻的,但是这个排查过程是值得大家学习的。 其实在之前自己排查过很多次CPU飙高的问题,这次也是按照老方法进行排查,但是刚开始并没有发现太大的问题,只是以为是流量升高导致数据库操作变多的正常现象。 期间又多方查证(通过arthas查看sequence的获取内容、通过数据库查看最近插入的数据的主键ID等)才发现是TDDL的Sequence的初始化机制有问题。 在解决了这个问题之后,以为彻底解决问题,结果又遇到了DP采集TDDL日志导致CPU飙高,最终再次解决后有了明显提升。 所以,事出反常必有妖,排查问题就是一个抽丝剥茧的过程。
-