找到
191
篇与
Java
相关的结果
- 第 31 页
-
 Java文件解压之TGZ解压 package com.alibaba.intl.batch.dependency; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.InputStream; import java.io.OutputStream; import org.apache.commons.compress.archivers.tar.TarArchiveEntry; import org.apache.commons.compress.archivers.tar.TarArchiveInputStream; import org.apache.commons.compress.compressors.gzip.GzipCompressorInputStream; import org.apache.commons.compress.utils.IOUtils; import org.apache.commons.lang3.StringUtils; /** * 解压工具类 * @author hollis * */ public class PackDecompressor { public static int BUFFER_SIZE = 2048; public static void main(String[] args) throws Exception { unTarGZ("/home/hollis/Downloads/a.tgz", "/home/hollis/Downloads/a"); } public static void unTarGZ(String file,String destDir) throws Exception{ File tarFile = new File(file); unTarGZ(tarFile, destDir); } public static void unTarGZ(File tarFile,String destDir) throws Exception{ if(StringUtils.isBlank(destDir)) { destDir = tarFile.getParent(); } destDir = destDir.endsWith(File.separator) ? destDir : destDir + File.separator; unTar(new GzipCompressorInputStream(new FileInputStream(tarFile)), destDir); } private static void unTar(InputStream inputStream, String destDir) throws Exception { TarArchiveInputStream tarIn = new TarArchiveInputStream(inputStream, BUFFER_SIZE); TarArchiveEntry entry = null; try { while ((entry = tarIn.getNextTarEntry()) != null) { if (entry.isDirectory()) {//是目录 createDirectory(destDir, entry.getName());//创建空目录 } else {//是文件 File tmpFile = new File(destDir + File.separator + entry.getName()); createDirectory(tmpFile.getParent() + File.separator, null);//创建输出目录 OutputStream out = null; try { out = new FileOutputStream(tmpFile); int length = 0; byte[] b = new byte[2048]; while ((length = tarIn.read(b)) != -1) { out.write(b, 0, length); } } finally { IOUtils.closeQuietly(out); } } } } catch (Exception e) { e.printStackTrace(); throw e; } finally { IOUtils.closeQuietly(tarIn); } } public static void createDirectory(String outputDir,String subDir){ File file = new File(outputDir); if(!(subDir == null || subDir.trim().equals(""))){//子目录不为空 file = new File(outputDir + File.separator + subDir); } if(!file.exists()){ file.mkdirs(); } } }
Java文件解压之TGZ解压 package com.alibaba.intl.batch.dependency; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.InputStream; import java.io.OutputStream; import org.apache.commons.compress.archivers.tar.TarArchiveEntry; import org.apache.commons.compress.archivers.tar.TarArchiveInputStream; import org.apache.commons.compress.compressors.gzip.GzipCompressorInputStream; import org.apache.commons.compress.utils.IOUtils; import org.apache.commons.lang3.StringUtils; /** * 解压工具类 * @author hollis * */ public class PackDecompressor { public static int BUFFER_SIZE = 2048; public static void main(String[] args) throws Exception { unTarGZ("/home/hollis/Downloads/a.tgz", "/home/hollis/Downloads/a"); } public static void unTarGZ(String file,String destDir) throws Exception{ File tarFile = new File(file); unTarGZ(tarFile, destDir); } public static void unTarGZ(File tarFile,String destDir) throws Exception{ if(StringUtils.isBlank(destDir)) { destDir = tarFile.getParent(); } destDir = destDir.endsWith(File.separator) ? destDir : destDir + File.separator; unTar(new GzipCompressorInputStream(new FileInputStream(tarFile)), destDir); } private static void unTar(InputStream inputStream, String destDir) throws Exception { TarArchiveInputStream tarIn = new TarArchiveInputStream(inputStream, BUFFER_SIZE); TarArchiveEntry entry = null; try { while ((entry = tarIn.getNextTarEntry()) != null) { if (entry.isDirectory()) {//是目录 createDirectory(destDir, entry.getName());//创建空目录 } else {//是文件 File tmpFile = new File(destDir + File.separator + entry.getName()); createDirectory(tmpFile.getParent() + File.separator, null);//创建输出目录 OutputStream out = null; try { out = new FileOutputStream(tmpFile); int length = 0; byte[] b = new byte[2048]; while ((length = tarIn.read(b)) != -1) { out.write(b, 0, length); } } finally { IOUtils.closeQuietly(out); } } } } catch (Exception e) { e.printStackTrace(); throw e; } finally { IOUtils.closeQuietly(tarIn); } } public static void createDirectory(String outputDir,String subDir){ File file = new File(outputDir); if(!(subDir == null || subDir.trim().equals(""))){//子目录不为空 file = new File(outputDir + File.separator + subDir); } if(!file.exists()){ file.mkdirs(); } } }
-
为什么阿里巴巴禁止开发人员使用isSuccess作为变量名 在日常开发中,我们会经常要在类中定义布尔类型的变量,比如在给外部系统提供一个RPC接口的时候,我们一般会定义一个字段表示本次请求是否成功的。 关于这个”本次请求是否成功”的字段的定义,其实是有很多种讲究和坑的,稍有不慎就会掉入坑里,作者在很久之前就遇到过类似的问题,本文就来围绕这个简单分析一下。到底该如何定一个布尔类型的成员变量。 一般情况下,我们可以有以下四种方式来定义一个布尔类型的成员变量: boolean success boolean isSuccess Boolean success Boolean isSuccess 以上四种定义形式,你日常开发中最常用的是哪种呢?到底哪一种才是正确的使用姿势呢? 通过观察我们可以发现,前两种和后两种的主要区别是变量的类型不同,前者使用的是boolean,后者使用的是Boolean。 另外,第一种和第三种在定义变量的时候,变量命名是success,而另外两种使用isSuccess来命名的。 首先,我们来分析一下,到底应该是用success来命名,还是使用isSuccess更好一点。 success 还是 isSuccess 到底应该是用success还是isSuccess来给变量命名呢?从语义上面来讲,两种命名方式都可以讲的通,并且也都没有歧义。那么还有什么原则可以参考来让我们做选择呢。 在阿里巴巴Java开发手册中关于这一点,有过一个『强制性』规定:  那么,为什么会有这样的规定呢?我们看一下POJO中布尔类型变量不同的命名有什么区别吧。 class Model1 { private Boolean isSuccess; public void setSuccess(Boolean success) { isSuccess = success; } public Boolean getSuccess() { return isSuccess; } } class Model2 { private Boolean success; public Boolean getSuccess() { return success; } public void setSuccess(Boolean success) { this.success = success; } } class Model3 { private boolean isSuccess; public boolean isSuccess() { return isSuccess; } public void setSuccess(boolean success) { isSuccess = success; } } class Model4 { private boolean success; public boolean isSuccess() { return success; } public void setSuccess(boolean success) { this.success = success; } } 以上代码的setter/getter是使用Intellij IDEA自动生成的,仔细观察以上代码,你会发现以下规律: 基本类型自动生成的getter和setter方法,名称都是isXXX()和setXXX()形式的。 包装类型自动生成的getter和setter方法,名称都是getXXX()和setXXX()形式的。 既然,我们已经达成一致共识使用基本类型boolean来定义成员变量了,那么我们再来具体看下Model3和Model4中的setter/getter有何区别。 我们可以发现,虽然Model3和Model4中的成员变量的名称不同,一个是success,另外一个是isSuccess,但是他们自动生成的getter和setter方法名称都是isSuccess和setSuccess。 Java Bean中关于setter/getter的规范 关于Java Bean中的getter/setter方法的定义其实是有明确的规定的,根据JavaBeans(TM) Specification规定,如果是普通的参数propertyName,要以以下方式定义其setter/getter: public get(); public void set( a); 但是,布尔类型的变量propertyName则是单独定义的: public boolean is(); public void set(boolean m);  通过对照这份JavaBeans规范,我们发现,在Model4中,变量名为isSuccess,如果严格按照规范定义的话,他的getter方法应该叫isIsSuccess。但是很多IDE都会默认生成为isSuccess。 那这样做会带来什么问题呢。 在一般情况下,其实是没有影响的。但是有一种特殊情况就会有问题,那就是发生序列化的时候。 序列化带来的影响 关于序列化和反序列化请参考Java对象的序列化与反序列化。我们这里拿比较常用的JSON序列化来举例,看看看常用的fastJson、jackson和Gson之间有何区别: public class BooleanMainTest { public static void main(String[] args) throws IOException { //定一个Model3类型 Model3 model3 = new Model3(); model3.setSuccess(true); //使用fastjson(1.2.16)序列化model3成字符串并输出 System.out.println("Serializable Result With fastjson :" + JSON.toJSONString(model3)); //使用Gson(2.8.5)序列化model3成字符串并输出 Gson gson =new Gson(); System.out.println("Serializable Result With Gson :" +gson.toJson(model3)); //使用jackson(2.9.7)序列化model3成字符串并输出 ObjectMapper om = new ObjectMapper(); System.out.println("Serializable Result With jackson :" +om.writeValueAsString(model3)); } } class Model3 implements Serializable { private static final long serialVersionUID = 1836697963736227954L; private boolean isSuccess; public boolean isSuccess() { return isSuccess; } public void setSuccess(boolean success) { isSuccess = success; } public String getHollis(){ return "hollischuang"; } } 以上代码的Model3中,只有一个成员变量即isSuccess,三个方法,分别是IDE帮我们自动生成的isSuccess和setSuccess,另外一个是作者自己增加的一个符合getter命名规范的方法。 以上代码输出结果: Serializable Result With fastjson :{"hollis":"hollischuang","success":true} Serializable Result With Gson :{"isSuccess":true} Serializable Result With jackson :{"success":true,"hollis":"hollischuang"} 在fastjson和jackson的结果中,原来类中的isSuccess字段被序列化成success,并且其中还包含hollis值。而Gson中只有isSuccess字段。 我们可以得出结论:fastjson和jackson在把对象序列化成json字符串的时候,是通过反射遍历出该类中的所有getter方法,得到getHollis和isSuccess,然后根据JavaBeans规则,他会认为这是两个属性hollis和success的值。直接序列化成json:{“hollis”:”hollischuang”,”success”:true} 但是Gson并不是这么做的,他是通过反射遍历该类中的所有属性,并把其值序列化成json:{“isSuccess”:true} 可以看到,由于不同的序列化工具,在进行序列化的时候使用到的策略是不一样的,所以,对于同一个类的同一个对象的序列化结果可能是不同的。 前面提到的关于对getHollis的序列化只是为了说明fastjson、jackson和Gson之间的序列化策略的不同,我们暂且把他放到一边,我们把他从Model3中删除后,重新执行下以上代码,得到结果: Serializable Result With fastjson :{"success":true} Serializable Result With Gson :{"isSuccess":true} Serializable Result With jackson :{"success":true} 现在,不同的序列化框架得到的json内容并不相同,如果对于同一个对象,我使用fastjson进行序列化,再使用Gson反序列化会发生什么? public class BooleanMainTest { public static void main(String[] args) throws IOException { Model3 model3 = new Model3(); model3.setSuccess(true); Gson gson =new Gson(); System.out.println(gson.fromJson(JSON.toJSONString(model3),Model3.class)); } } class Model3 implements Serializable { private static final long serialVersionUID = 1836697963736227954L; private boolean isSuccess; public boolean isSuccess() { return isSuccess; } public void setSuccess(boolean success) { isSuccess = success; } @Override public String toString() { return new StringJoiner(", ", Model3.class.getSimpleName() + "[", "]") .add("isSuccess=" + isSuccess) .toString(); } } 以上代码,输出结果: Model3[isSuccess=false] 这和我们预期的结果完全相反,原因是因为JSON框架通过扫描所有的getter后发现有一个isSuccess方法,然后根据JavaBeans的规范,解析出变量名为success,把model对象序列化城字符串后内容为{"success":true}。 根据{"success":true}这个json串,Gson框架在通过解析后,通过反射寻找Model类中的success属性,但是Model类中只有isSuccess属性,所以,最终反序列化后的Model类的对象中,isSuccess则会使用默认值false。 但是,一旦以上代码发生在生产环境,这绝对是一个致命的问题。 所以,作为开发者,我们应该想办法尽量避免这种问题的发生,对于POJO的设计者来说,只需要做简单的一件事就可以解决这个问题了,那就是把isSuccess改为success。这样,该类里面的成员变量时success,getter方法是isSuccess,这是完全符合JavaBeans规范的。无论哪种序列化框架,执行结果都一样。就从源头避免了这个问题。 引用以下R大关于阿里巴巴Java开发手册这条规定的评价(https://www.zhihu.com/question/55642203):  所以,在定义POJO中的布尔类型的变量时,不要使用isSuccess这种形式,而要直接使用success! Boolean还是boolean? 前面我们介绍完了在success和isSuccess之间如何选择,那么排除错误答案后,备选项还剩下: boolean success Boolean success 那么,到底应该是用Boolean还是boolean来给定一个布尔类型的变量呢? 我们知道,boolean是基本数据类型,而Boolean是包装类型。关于基本数据类型和包装类之间的关系和区别请参考一文读懂什么是Java中的自动拆装箱 那么,在定义一个成员变量的时候到底是使用包装类型更好还是使用基本数据类型呢? 我们来看一段简单的代码 /** * @author Hollis */ public class BooleanMainTest { public static void main(String[] args) { Model model1 = new Model(); System.out.println("default model : " + model1); } } class Model { /** * 定一个Boolean类型的success成员变量 */ private Boolean success; /** * 定一个boolean类型的failure成员变量 */ private boolean failure; /** * 覆盖toString方法,使用Java 8 的StringJoiner */ @Override public String toString() { return new StringJoiner(", ", Model.class.getSimpleName() + "[", "]") .add("success=" + success) .add("failure=" + failure) .toString(); } } 以上代码输出结果为: default model : Model[success=null, failure=false] 可以看到,当我们没有设置Model对象的字段的值的时候,Boolean类型的变量会设置默认值为null,而boolean类型的变量会设置默认值为false。 即对象的默认值是null,boolean基本数据类型的默认值是false。 在阿里巴巴Java开发手册中,对于POJO中如何选择变量的类型也有着一些规定: 这里建议我们使用包装类型,原因是什么呢? 举一个扣费的例子,我们做一个扣费系统,扣费时需要从外部的定价系统中读取一个费率的值,我们预期该接口的返回值中会包含一个浮点型的费率字段。当我们取到这个值得时候就使用公式:金额*费率=费用 进行计算,计算结果进行划扣。 如果由于计费系统异常,他可能会返回个默认值,如果这个字段是Double类型的话,该默认值为null,如果该字段是double类型的话,该默认值为0.0。 如果扣费系统对于该费率返回值没做特殊处理的话,拿到null值进行计算会直接报错,阻断程序。拿到0.0可能就直接进行计算,得出接口为0后进行扣费了。这种异常情况就无法被感知。 这种使用包装类型定义变量的方式,通过异常来阻断程序,进而可以被识别到这种线上问题。如果使用基本数据类型的话,系统可能不会报错,进而认为无异常。 以上,就是建议在POJO和RPC的返回值中使用包装类型的原因。 但是关于这一点,作者之前也有过不同的看法:对于布尔类型的变量,我认为可以和其他类型区分开来,作者并不认为使用null进而导致NPE是一种最好的实践。因为布尔类型只有true/false两种值,我们完全可以和外部调用方约定好当返回值为false时的明确语义。 后来,作者单独和《阿里巴巴Java开发手册》、《码出高效》的作者——孤尽 单独1V1(qing) Battle(jiao)了一下。最终达成共识,还是尽量使用包装类型。 但是,作者还是想强调一个我的观点,尽量避免在你的代码中出现不确定的null值。 null何罪之有? 关于null值的使用,我在使用Optional避免NullPointerException、9 Things about Null in Java等文中就介绍过。 null是很模棱两可的,很多时候会导致令人疑惑的的错误,很难去判断返回一个null代表着什么意思。 图灵奖得主Tony Hoare 曾经公开表达过null是一个糟糕的设计。  我把 null 引用称为自己的十亿美元错误。它的发明是在1965 年,那时我用一个面向对象语言( ALGOL W )设计了第一个全面的引用类型系统。我的目的是确保所有引用的使用都是绝对安全的,编译器会自动进行检查。但是我未能抵御住诱惑,加入了Null引用,仅仅是因为实现起来非常容易。它导致了数不清的错误、漏洞和系统崩溃,可能在之后 40 年中造成了十亿美元的损失。 当我们在设计一个接口的时候,对于接口的返回值的定义,尽量避免使用Boolean类型来定义。大多数情况下,别人使用我们的接口返回值时可能用if(response.isSuccess){}else{}的方式,如果我们由于忽略没有设置success字段的值,就可能导致NPE(java.lang.NullPointerException),这明显是我们不希望看到的。 所以,当我们要定义一个布尔类型的成员变量时,尽量选择boolean,而不是Boolean。当然,编程中并没有绝对。 总结 本文围绕布尔类型的变量定义的类型和命名展开了介绍,最终我们可以得出结论,在定义一个布尔类型的变量,尤其是一个给外部提供的接口返回值时,要使用success来命名,阿里巴巴Java开发手册建议使用封装类来定义POJO和RPC返回值中的变量。但是这不意味着可以随意的使用null,我们还是要尽量避免出现对null的处理的。
-
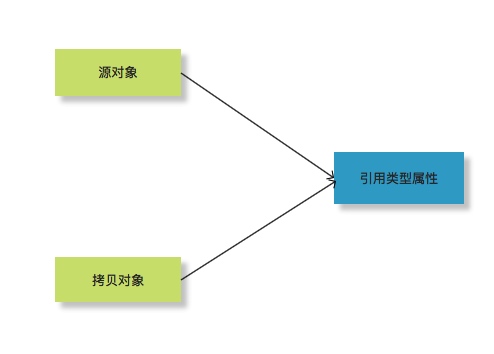
使用各类BeanUtils的时候,切记注意这个坑! 在日常开发中,我们经常需要给对象进行赋值,通常会调用其set/get方法,有些时候,如果我们要转换的两个对象之间属性大致相同,会考虑使用属性拷贝工具进行。 如我们经常在代码中会对一个数据结构封装成DO、SDO、DTO、VO等,而这些Bean中的大部分属性都是一样的,所以使用属性拷贝类工具可以帮助我们节省大量的set和get操作。 市面上有很多类似的工具类,比较常用的有 1、Spring BeanUtils 2、Cglib BeanCopier 3、Apache BeanUtils 4、Apache PropertyUtils 5、Dozer 6、MapStucts 这里面我比较建议大家使用的是MapStructs,我在《丢弃掉那些BeanUtils工具类吧,MapStruct真香!!!》中介绍过原因。这里就不再赘述了。 最近我们有个新项目,要创建一个新的应用,因为我自己分析过这些工具的效率,也去看过他们的实现原理,比较下来之后,我觉得MapStruct是最适合我们的,于是就在代码中引入了这个框架。 另外,因为Spring的BeanUtils用起来也比较方便,所以,代码中对于需要beanCopy的地方主要在使用这两个框架。 我们一般是这样的,如果是DO和DTO/Entity之间的转换,我们统一使用MapStruct,因为他可以指定单独的Mapper,可以自定义一些策略。 如果是同对象之间的拷贝(如用一个DO创建一个新的DO),或者完全不相关的两个对象转换,则使用Spring的BeanUtils。 刚开始都没什么问题,但是后面我在写单测的时候,发现了一个问题。 问题 先来看看我们是在什么地方用的Spring的BeanUtils 我们的业务逻辑中,需要对订单信息进行修改,在更改时,不仅要更新订单的上面的属性信息,还需要创建一条变更流水。 而变更流水中同时记录了变更前和变更后的数据,所以就有了以下代码: //从数据库中查询出当前订单,并加锁 OrderDetail orderDetail = orderDetailDao.queryForLock(); //copy一个新的订单模型 OrderDetail newOrderDetail = new OrderDetail(); BeanUtils.copyProperties(orderDetail, newOrderDetail); //对新的订单模型进行修改逻辑操作 newOrderDetail.update(); //使用修改前的订单模型和修改后的订单模型组装出订单变更流水 OrderDetailStream orderDetailStream = new OrderDetailStream(); orderDetailStream.create(orderDetail, newOrderDetail); 大致逻辑是这样的,因为创建订单变更流水的时候,需要一个改变前的订单和改变后的订单。所以我们想到了要new一个新的订单模型,然后操作新的订单模型,避免对旧的有影响。 但是,就是这个BeanUtils.copyProperties的过程其实是有问题的。 因为BeanUtils在进行属性copy的时候,本质上是浅拷贝,而不是深拷贝。 浅拷贝?深拷贝? 什么是浅拷贝和深拷贝?来看下概念。 1、浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。  2、深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。  我们举个实际例子,来看下为啥我说BeanUtils.copyProperties的过程是浅拷贝。 先来定义两个类: public class Address { private String province; private String city; private String area; //省略构造函数和setter/getter } class User { private String name; private String password; private HomeAddress address; //省略构造函数和setter/getter } 然后写一段测试代码: User user = new User("Hollis", "hollischuang"); user.setAddress(new HomeAddress("zhejiang", "hangzhou", "binjiang")); User newUser = new User(); BeanUtils.copyProperties(user, newUser); System.out.println(user.getAddress() == newUser.getAddress()); 以上代码输出结果为:true 即,我们BeanUtils.copyProperties拷贝出来的newUser中的address对象和原来的user中的address对象是同一个对象。 可以尝试着修改下newUser中的address对象: newUser.getAddress().setCity("shanghai"); System.out.println(JSON.toJSONString(user)); System.out.println(JSON.toJSONString(newUser)); 输出结果: {"address":{"area":"binjiang","city":"shanghai","province":"zhejiang"},"name":"Hollis","password":"hollischuang"} {"address":{"area":"binjiang","city":"shanghai","province":"zhejiang"},"name":"Hollis","password":"hollischuang"} 可以发现,原来的对象也受到了修改的影响。 这就是所谓的浅拷贝! 如何进行深拷贝 发现问题之后,我们就要想办法解决,那么如何实现深拷贝呢? 1、实现Cloneable接口,重写clone() 在Object类中定义了一个clone方法,这个方法其实在不重写的情况下,其实也是浅拷贝的。 如果想要实现深拷贝,就需要重写clone方法,而想要重写clone方法,就必须实现Cloneable,否则会报CloneNotSupportedException异常。 将上述代码修改下,重写clone方法: public class Address implements Cloneable{ private String province; private String city; private String area; //省略构造函数和setter/getter @Override public Object clone() throws CloneNotSupportedException { return super.clone(); } } class User implements Cloneable{ private String name; private String password; private HomeAddress address; //省略构造函数和setter/getter @Override protected Object clone() throws CloneNotSupportedException { User user = (User)super.clone(); user.setAddress((HomeAddress)address.clone()); return user; } } 之后,在执行一下上面的测试代码,就可以发现,这时候newUser中的address对象就是一个新的对象了。 这种方式就能实现深拷贝,但是问题是如果我们在User中有很多个对象,那么clone方法就写的很长,而且如果后面有修改,在User中新增属性,这个地方也要改。 那么,有没有什么办法可以不需要修改,一劳永逸呢? 2、序列化实现深拷贝 我们可以借助序列化来实现深拷贝。先把对象序列化成流,再从流中反序列化成对象,这样就一定是新的对象了。 序列化的方式有很多,比如我们可以使用各种JSON工具,把对象序列化成JSON字符串,然后再从字符串中反序列化成对象。 如使用fastjson实现: User newUser = JSON.parseObject(JSON.toJSONString(user), User.class); 也可实现深拷贝。 除此之外,还可以使用Apache Commons Lang中提供的SerializationUtils工具实现。 我们需要修改下上面的User和Address类,使他们实现Serializable接口,否则是无法进行序列化的。 class User implements Serializable class Address implements Serializable 然后在需要拷贝的时候: User newUser = (User) SerializationUtils.clone(user); 同样,也可以实现深拷贝啦~!
-
为什么阿里巴巴禁止使用Apache Beanutils进行属性的copy? 在日常开发中,我们经常需要给对象进行赋值,通常会调用其set/get方法,有些时候,如果我们要转换的两个对象之间属性大致相同,会考虑使用属性拷贝工具进行。 如我们经常在代码中会对一个数据结构封装成DO、SDO、DTO、VO等,而这些Bean中的大部分属性都是一样的,所以使用属性拷贝类工具可以帮助我们节省大量的set和get操作。 市面上有很多类似的工具类,比较常用的有 1、Spring BeanUtils 2、Cglib BeanCopier 3、Apache BeanUtils 4、Apache PropertyUtils 5、Dozer 那么,我们到底应该选择哪种工具类更加合适呢?为什么阿里巴巴Java开发手册中提到禁止使用Apache BeanUtils呢?  由于篇幅优先,关于这几种工具类的用法及区别,还有到底是什么是浅拷贝和深拷贝不在本文的讨论范围内。 本文主要聚焦于对比这几个类库的性能问题。 性能对比 No Data No BB,我们就来写代码来对比下这几种框架的性能情况。 代码示例如下: 首先定义一个PersonDO类: public class PersonDO { private Integer id; private String name; private Integer age; private Date birthday; //省略setter/getter } 再定义一个PersonDTO类: public class PersonDTO { private String name; private Integer age; private Date birthday; } 然后进行测试类的编写: 使用Spring BeanUtils进行属性拷贝: private void mappingBySpringBeanUtils(PersonDO personDO, int times) { StopWatch stopwatch = new StopWatch(); stopwatch.start(); for (int i = 0; i < times; i++) { PersonDTO personDTO = new PersonDTO(); org.springframework.beans.BeanUtils.copyProperties(personDO, personDTO); } stopwatch.stop(); System.out.println("mappingBySpringBeanUtils cost :" + stopwatch.getTotalTimeMillis()); } 其中的StopWatch用于记录代码执行时间,方便进行对比。 使用Cglib BeanCopier进行属性拷贝: private void mappingByCglibBeanCopier(PersonDO personDO, int times) { StopWatch stopwatch = new StopWatch(); stopwatch.start(); for (int i = 0; i < times; i++) { PersonDTO personDTO = new PersonDTO(); BeanCopier copier = BeanCopier.create(PersonDO.class, PersonDTO.class, false); copier.copy(personDO, personDTO, null); } stopwatch.stop(); System.out.println("mappingByCglibBeanCopier cost :" + stopwatch.getTotalTimeMillis()); } 使用Apache BeanUtils进行属性拷贝: private void mappingByApacheBeanUtils(PersonDO personDO, int times) throws InvocationTargetException, IllegalAccessException { StopWatch stopwatch = new StopWatch(); stopwatch.start(); for (int i = 0; i < times; i++) { PersonDTO personDTO = new PersonDTO(); BeanUtils.copyProperties(personDTO, personDO); } stopwatch.stop(); System.out.println("mappingByApacheBeanUtils cost :" + stopwatch.getTotalTimeMillis()); } 使用Apache PropertyUtils进行属性拷贝: private void mappingByApachePropertyUtils(PersonDO personDO, int times) throws InvocationTargetException, IllegalAccessException, NoSuchMethodException { StopWatch stopwatch = new StopWatch(); stopwatch.start(); for (int i = 0; i < times; i++) { PersonDTO personDTO = new PersonDTO(); PropertyUtils.copyProperties(personDTO, personDO); } stopwatch.stop(); System.out.println("mappingByApachePropertyUtils cost :" + stopwatch.getTotalTimeMillis()); } 然后执行以下代码: public static void main(String[] args) throws InvocationTargetException, IllegalAccessException, NoSuchMethodException { PersonDO personDO = new PersonDO(); personDO.setName("Hollis"); personDO.setAge(26); personDO.setBirthday(new Date()); personDO.setId(1); MapperTest mapperTest = new MapperTest(); mapperTest.mappingBySpringBeanUtils(personDO, 100); mapperTest.mappingBySpringBeanUtils(personDO, 1000); mapperTest.mappingBySpringBeanUtils(personDO, 10000); mapperTest.mappingBySpringBeanUtils(personDO, 100000); mapperTest.mappingBySpringBeanUtils(personDO, 1000000); mapperTest.mappingByCglibBeanCopier(personDO, 100); mapperTest.mappingByCglibBeanCopier(personDO, 1000); mapperTest.mappingByCglibBeanCopier(personDO, 10000); mapperTest.mappingByCglibBeanCopier(personDO, 100000); mapperTest.mappingByCglibBeanCopier(personDO, 1000000); mapperTest.mappingByApachePropertyUtils(personDO, 100); mapperTest.mappingByApachePropertyUtils(personDO, 1000); mapperTest.mappingByApachePropertyUtils(personDO, 10000); mapperTest.mappingByApachePropertyUtils(personDO, 100000); mapperTest.mappingByApachePropertyUtils(personDO, 1000000); mapperTest.mappingByApacheBeanUtils(personDO, 100); mapperTest.mappingByApacheBeanUtils(personDO, 1000); mapperTest.mappingByApacheBeanUtils(personDO, 10000); mapperTest.mappingByApacheBeanUtils(personDO, 100000); mapperTest.mappingByApacheBeanUtils(personDO, 1000000); } 得到结果如下: 工具类 执行1000次耗时 执行10000次耗时 执行100000次耗时 执行1000000次耗时 Spring BeanUtils 5ms 10ms 45ms 169ms Cglib BeanCopier 4ms 18ms 45ms 91ms Apache PropertyUtils 60ms 265ms 1444ms 11492ms Apache BeanUtils 138ms 816ms 4154ms 36938ms Dozer 566ms 2254ms 11136ms 102965ms 画了一张折线图更方便大家进行对比  综上,我们基本可以得出结论,在性能方面,Spring BeanUtils和Cglib BeanCopier表现比较不错,而Apache PropertyUtils、Apache BeanUtils以及Dozer则表现的很不好。 所以,如果考虑性能情况的话,建议大家不要选择Apache PropertyUtils、Apache BeanUtils以及Dozer等工具类。 很多人会不理解,为什么大名鼎鼎的Apache开源出来的的类库性能确不高呢?这不像是Apache的风格呀,这背后导致性能低下的原因又是什么呢? 其实,是因为Apache BeanUtils力求做得完美, 在代码中增加了非常多的校验、兼容、日志打印等代码,过度的包装导致性能下降严重。 总结 本文通过对比几种常见的属性拷贝的类库,分析得出了这些工具类的性能情况,最终也验证了《阿里巴巴Java开发手册》中提到的”Apache BeanUtils 效率低”的事实。 但是本文只是站在性能这一单一角度进行了对比,我们在选择一个工具类的时候还会有其他方面的考虑,比如使用成本、理解难度、兼容性、可扩展性等,对于这种拷贝类工具类,我们还会考虑其功能是否完善等。 就像虽然Dozer性能比较差,但是他可以很好的和Spring结合,可以通过配置文件等进行属性之间的映射等,也受到了很多开发者的喜爱。 本文用到的第三方类库的maven依赖如下: commons-beanutils commons-beanutils 1.9.4 commons-logging commons-logging 1.1.2 org.springframework org.springframework.beans 3.1.1.RELEASE cglib cglib-nodep 2.2.2 net.sf.dozer dozer 5.5.1 org.slf4j slf4j-api 1.7.7 org.slf4j jul-to-slf4j 1.7.7 org.slf4j jcl-over-slf4j 1.7.7 org.slf4j log4j-over-slf4j 1.7.7 org.slf4j slf4j-jdk14 1.7.7
-
同步容器(如Vector)并不是所有操作都线程安全!~ 转移:http://www.hollischuang.com/archives/3935 转移:http://www.hollischuang.com/archives/3935 转移:http://www.hollischuang.com/archives/3935 转移:http://www.hollischuang.com/archives/3935 转移:http://www.hollischuang.com/archives/3935 之前在公众号中问了这个问题:对于线程安全的集合类(例如Vector)的任何操作是不是都能保证线程安全? 三天之内收到120+回复,其中表示不清楚的大概有10人左右,认为可以保证线程安全的有大概70人左右,认为不能保证线程安全的有50人左右,这其中能给出明确解释的有5人。 分别是: @赵鹏: size方法和get方法,如果集合的长度变化了,可能抛出异常, @aold619: 去网上查了资料:“有条件的线程安全 我们在 7 月份的文件“ 并发集合类”中讨论了有条件的线程安全。有条件的线程安全类对于单独的操作可以是线程安全的,但是某些操作序列可能需要外部同步。条件线程安全的最常见的例子是遍历由 Hashtable 或者 Vector 或者返回的迭代器 — 由这些类返回的 fail-fast 迭代器假定在迭代器进行遍历的时候底层集合不会有变化。为了保证其他线程不会在遍历的时候改变集合,进行迭代的线程应该确保它是独占性地访问集合以实现遍历的完整性。通常,独占性的访问是由对锁的同步保证的 — 并且类的文档应该说明是哪个锁(通常是对象的内部监视器(intrinsic monitor))。 如果对一个有条件线程安全类进行记录,那么您应该不仅要记录它是有条件线程安全的,而且还要记录必须防止哪些操作序列的并发访问。用户可以合理地假设其他操作序列不需要任何额外的同步。” @闫晓琦: 答,不是,经常会出现数组越界报错 @逆风飞扬: vector单个的方法 synchronized并不代表vector组合的方法调用具有原子性。有组合的操作还是需要针对vector进行加锁。 @慕容: 不是,线程安全集合只能保证单个操作安全,复合操作同样不安全 那么这个问题的正解应该是什么的。 问:对于线程安全的集合类(例如Vector)的任何操作是不是都能保证线程安全? 答:同步容器中的所有自带方法都是线程安全的,因为方法都使用synchronized关键字标注。但是,对这些集合类的复合操作无法保证其线程安全性。需要客户端通过主动加锁来保证 如果你看过JDK的源码,那么你会发现,像Vector这样的同步容器的所有共有方法全都是synchronized的。也就是说,我们可以在多线程场景中放心的使用单独这些方法,因为这些方法本身的确是线程安全的。那么为什么又说复合操作无法保证线程安全呢?这里举个栗子,我们定义如下删除Vector中最后一个元素方法: public Object deleteLast(Vector v){ int lastIndex = v.size()-1; v.remove(lastIndex); } 上面这个方法是一个复合方法,包括size()和remove(),乍一看上去好像并没有什么问题,无论是size()方法还是remove()方法都是线程安全的,那么整个deleteLast方法应该也是线程安全的。但是时,如果多线程调用该方法的过程中有,remove方法有可能抛出ArrayIndexOutOfBoundsException。我们看一下remove方法具体实现,什么情况下会抛出这个异常呢。 public synchronized E remove(int index) { modCount++; if (index >= elementCount) throw new ArrayIndexOutOfBoundsException(index); E oldValue = elementData(index); int numMoved = elementCount - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--elementCount] = null; // Let gc do its work return oldValue; } 从上面代码中可以看出,当index >= elementCount时,会抛出ArrayIndexOutOfBoundsException,也就是说,当当前索引值不再有效的时候,将会抛出这个异常。因为removeLast方法,有可能被多个线程同时执行,当线程一通过index()获得索引值为10,在尝试通过remove()删除该索引位置的元素之前,线程2把该索引位置的值删除掉了,这时线程一在执行时便会抛出异常。 为了避免出现类似问题,可以尝试加锁: public void deleteLast() { synchronized (v) { int index = v.size() - 1; v.remove(index); } } 如上,我们在deleteLast中,对v进行加锁,即可保证同一时刻,不会有其他线程删除掉v中的元素。 至此,我们已经解释清楚了我们的问题。 问:对于线程安全的集合类(例如Vector)的任何操作是不是都能保证线程安全? 答:同步容器中的所有自带方法都是线程安全的,因为方法都使用synchronized关键字标注。但是,对这些集合类的复合操作无法保证其线程安全性。需要客户端通过主动加锁来保证。 由于我们自己已知Vector等同步容器是线程安全的,所以我们通常在多线程场景中会直接拿来使用,并不会考虑太多,从而可能导致问题。 所以,我们在使用同步容器的时候,如果只使用其中的自带方法,那么可以放心使用,因为他们是线程安全的,但是如果我们想做复合操作,尤其是涉及到删除容器中的元素时,一定要注意是否需要客户端主动加锁。 下面,我们考虑以下代码,如果在多线程场景中使用会不会出现线程安全问题: for (int i = 0; i < v.size(); i++) { System.out.println(v.get(i)); } 显然,以上代码在迭代的过程中,并不会出现线程安全问题。但是,如果在程序中还有以下代码有可能被同时调用呢? for (int i = 0; i < v.size(); i++) { v.remove(i); } 由于,不同线程在同一时间操作同一个Vector,其中包括删除操作,那么就同样有可能发生线程安全问题。所以,在使用同步容器的时候,如果涉及到多个线程同时执行删除操作,就要考虑下是否需要加锁。