找到
191
篇与
Java
相关的结果
- 第 33 页
-
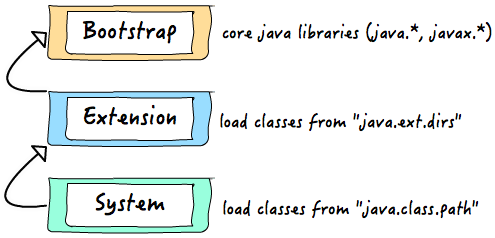
 深度分析Java的ClassLoader机制(源码级别) 写在前面:Java中的所有类,必须被装载到jvm中才能运行,这个装载工作是由jvm中的类装载器完成的,类装载器所做的工作实质是把类文件从硬盘读取到内存中,JVM在加载类的时候,都是通过ClassLoader的loadClass()方法来加载class的,loadClass使用双亲委派模式。 为了更好的理解类的加载机制,我们来深入研究一下ClassLoader和他的loadClass()方法。 源码分析 public abstract class ClassLoader ClassLoader类是一个抽象类,sun公司是这么解释这个类的: /** * A class loader is an object that is responsible for loading classes. The * class ClassLoader is an abstract class. Given the binary name of a class, a class loader should attempt to * locate or generate data that constitutes a definition for the class. A * typical strategy is to transform the name into a file name and then read a * "class file" of that name from a file system. **/ 大致意思如下: class loader是一个负责加载classes的对象,ClassLoader类是一个抽象类,需要给出类的二进制名称,class loader尝试定位或者产生一个class的数据,一个典型的策略是把二进制名字转换成文件名然后到文件系统中找到该文件。 接下来我们看loadClass方法的实现方式: protected Class loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded Class c = findLoadedClass(name); if (c == null) { long t0 = System.nanoTime(); try { if (parent != null) { c = parent.loadClass(name, false); } else { c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } if (c == null) { // If still not found, then invoke findClass in order // to find the class. long t1 = System.nanoTime(); c = findClass(name); // this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { resolveClass(c); } return c; } } 还是来看sun公司对该方法的解释: /** * Loads the class with the specified binary name. The * default implementation of this method searches for classes in the * following order: * * * * Invoke {@link #findLoadedClass(String)} to check if the class * has already been loaded. * * Invoke the {@link #loadClass(String) loadClass} method * on the parent class loader. If the parent is null the class * loader built-in to the virtual machine is used, instead. * * Invoke the {@link #findClass(String)} method to find the * class. * * * * If the class was found using the above steps, and the * resolve flag is true, this method will then invoke the {@link * #resolveClass(Class)} method on the resulting Class object. * * Subclasses of ClassLoader are encouraged to override {@link * #findClass(String)}, rather than this method. * * Unless overridden, this method synchronizes on the result of * {@link #getClassLoadingLock getClassLoadingLock} method * during the entire class loading process. * */ 大致内容如下: 使用指定的二进制名称来加载类,这个方法的默认实现按照以下顺序查找类: 调用findLoadedClass(String)方法检查这个类是否被加载过 使用父加载器调用loadClass(String)方法,如果父加载器为Null,类加载器装载虚拟机内置的加载器调用findClass(String)方法装载类, 如果,按照以上的步骤成功的找到对应的类,并且该方法接收的resolve参数的值为true,那么就调用resolveClass(Class)方法来处理类。 ClassLoader的子类最好覆盖findClass(String)而不是这个方法。 除非被重写,这个方法默认在整个装载过程中都是同步的(线程安全的) 接下来,我们开始分析该方法。 **protected Class loadClass(String name, boolean resolve)** 该方法的访问控制符是\`protected\`,也就是说该方法\*\*同包内和派生类中可用\*\* 返回值类型`Class ,这里用到**泛型**。这里使用通配符?作为泛型实参表示对象可以 接受任何类型(类类型)。因为该方法不知道要加载的类到底是什么类,所以就用了通用的泛型。String name要查找的类的名字,boolean resolve,一个标志,true表示将调用resolveClass(c)`处理该类 throws ClassNotFoundException 该方法会抛出找不到该类的异常,这是一个非运行时异常 synchronized (getClassLoadingLock(name)) 看到这行代码,我们能知道的是,这是一个同步代码块,那么synchronized的括号中放的应该是一个对象。我们来看getClassLoadingLock(name)方法的作用是什么: protected Object getClassLoadingLock(String className) { Object lock = this; if (parallelLockMap != null) { Object newLock = new Object(); lock = parallelLockMap.putIfAbsent(className, newLock); if (lock == null) { lock = newLock; } } return lock; } 以上是getClassLoadingLock(name)方法的实现细节,我们看到这里用到变量parallelLockMap ,根据这个变量的值进行不同的操作,如果这个变量是Null,那么直接返回this,如果这个属性不为Null,那么就新建一个对象,然后在调用一个putIfAbsent(className, newLock);方法来给刚刚创建好的对象赋值,这个方法的作用我们一会讲。那么这个parallelLockMap变量又是哪来的那,我们发现这个变量是ClassLoader类的成员变量: private final ConcurrentHashMap parallelLockMap; 这个变量的初始化工作在ClassLoader的构造函数中: private ClassLoader(Void unused, ClassLoader parent) { this.parent = parent; if (ParallelLoaders.isRegistered(this.getClass())) { parallelLockMap = new ConcurrentHashMap(); package2certs = new ConcurrentHashMap(); domains = Collections.synchronizedSet(new HashSet()); assertionLock = new Object(); } else { // no finer-grained lock; lock on the classloader instance parallelLockMap = null; package2certs = new Hashtable(); domains = new HashSet(); assertionLock = this; } } 这里我们可以看到构造函数根据一个属性ParallelLoaders的Registered状态的不同来给parallelLockMap 赋值。 我去,隐藏的好深,好,我们继续挖,看看这个ParallelLoaders又是在哪赋值的呢?我们发现,在ClassLoader类中包含一个静态内部类private static class ParallelLoaders,在ClassLoader被加载的时候这个静态内部类就被初始化。这个静态内部类的代码我就不贴了,直接告诉大家什么意思,sun公司是这么说的:Encapsulates the set of parallel capable loader types,意识就是说:封装了并行的可装载的类型的集合。 上面这个说的是不是有点乱,那让我们来整理一下: 首先,在ClassLoader类中有一个静态内部类ParallelLoaders,他会指定的类的并行能力,如果当前的加载器被定位为具有并行能力,那么他就给parallelLockMap定义,就是new一个 ConcurrentHashMap(),那么这个时候,我们知道如果当前的加载器是具有并行能力的,那么parallelLockMap就不是Null,这个时候,我们判断parallelLockMap是不是Null,如果他是null,说明该加载器没有注册并行能力,那么我们没有必要给他一个加锁的对象,getClassLoadingLock方法直接返回this,就是当前的加载器的一个实例。如果这个parallelLockMap不是null,那就说明该加载器是有并行能力的,那么就可能有并行情况,那就需要返回一个锁对象。然后就是创建一个新的Object对象,调用parallelLockMap的putIfAbsent(className, newLock)方法,这个方法的作用是:首先根据传进来的className,检查该名字是否已经关联了一个value值,如果已经关联过value值,那么直接把他关联的值返回,如果没有关联过值的话,那就把我们传进来的Object对象作为value值,className作为Key值组成一个map返回。然后无论putIfAbsent方法的返回值是什么,都把它赋值给我们刚刚生成的那个Object对象。 这个时候,我们来简单说明一下getClassLoadingLock(String className)的作用,就是: 为类的加载操作返回一个锁对象。为了向后兼容,这个方法这样实现:如果当前的classloader对象注册了并行能力,方法返回一个与指定的名字className相关联的特定对象,否则,直接返回当前的ClassLoader对象。 Class c = findLoadedClass(name); 在这里,在加载类之前先调用findLoadedClass方法检查该类是否已经被加载过,findLoadedClass会返回一个Class类型的对象,如果该类已经被加载过,那么就可以直接返回该对象(在返回之前会根据resolve的值来决定是否处理该对象,具体的怎么处理后面会讲)。 如果,该类没有被加载过,那么执行以下的加载过程 try { if (parent != null) { c = parent.loadClass(name, false); } else { c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } 如果父加载器不为空,那么调用父加载器的loadClass方法加载类,如果父加载器为空,那么调用虚拟机的加载器来加载类。 如果以上两个步骤都没有成功的加载到类,那么 c = findClass(name); 调用自己的findClass(name)方法来加载类。 这个时候,我们已经得到了加载之后的类,那么就根据resolve的值决定是否调用resolveClass方法。resolveClass方法的作用是: 链接指定的类。这个方法给Classloader用来链接一个类,如果这个类已经被链接过了,那么这个方法只做一个简单的返回。否则,这个类将被按照 Java™规范中的Execution描述进行链接。。。 至此,ClassLoader类以及loadClass方法的源码我们已经分析完了,那么。结合源码的分析,我们来总结一下: 总结 java中的类大致分为三种: 1.系统类 2.扩展类 3.由程序员自定义的类 类装载方式,有两种: 1.隐式装载, 程序在运行过程中当碰到通过new 等方式生成对象时,隐式调用类装载器加载对应的类到jvm中。 2.显式装载, 通过class.forname()等方法,显式加载需要的类 类加载的动态性体现: 一个应用程序总是由n多个类组成,Java程序启动时,并不是一次把所有的类全部加载后再运行,它总是先把保证程序运行的基础类一次性加载到jvm中,其它类等到jvm用到的时候再加载,这样的好处是节省了内存的开销,因为java最早就是为嵌入式系统而设计的,内存宝贵,这是一种可以理解的机制,而用到时再加载这也是java动态性的一种体现 java类装载器 Java中的类装载器实质上也是类,功能是把类载入jvm中,值得注意的是jvm的类装载器并不是一个,而是三个,层次结构如下: 为什么要有三个类加载器,一方面是分工,各自负责各自的区块,另一方面为了实现委托模型,下面会谈到该模型 类加载器之间是如何协调工作的 前面说了,java中有三个类加载器,问题就来了,碰到一个类需要加载时,它们之间是如何协调工作的,即java是如何区分一个类该由哪个类加载器来完成呢。 在这里java采用了委托模型机制,这个机制简单来讲,就是“类装载器有载入类的需求时,会先请示其Parent使用其搜索路径帮忙载入,如果Parent 找不到,那么才由自己依照自己的搜索路径搜索类” 下面举一个例子来说明,为了更好的理解,先弄清楚几行代码: Public class Test{ Public static void main(String[] arg){ ClassLoader c = Test.class.getClassLoader(); //获取Test类的类加载器 System.out.println(c); ClassLoader c1 = c.getParent(); //获取c这个类加载器的父类加载器 System.out.println(c1); ClassLoader c2 = c1.getParent();//获取c1这个类加载器的父类加载器 System.out.println(c2); } } 运行结果: 。。。AppClassLoader。。。 。。。ExtClassLoader。。。 Null 可以看出Test是由AppClassLoader加载器加载的,AppClassLoader的Parent 加载器是 ExtClassLoader,但是ExtClassLoader的Parent为 null 是怎么回事呵,朋友们留意的话,前面有提到Bootstrap Loader是用C++语言写的,依java的观点来看,逻辑上并不存在Bootstrap Loader的类实体,所以在java程序代码里试图打印出其内容时,我们就会看到输出为null。 类装载器ClassLoader(一个抽象类)描述一下JVM加载class文件的原理机制 类装载器就是寻找类或接口字节码文件进行解析并构造JVM内部对象表示的组件,在java中类装载器把一个类装入JVM,经过以下步骤: 1、装载:查找和导入Class文件 2、链接:其中解析步骤是可以选择的 (a)检查:检查载入的class文件数据的正确性 (b)准备:给类的静态变量分配存储空间 (c)解析:将符号引用转成直接引用 3、初始化:对静态变量,静态代码块执行初始化工作 类装载工作由ClassLoder和其子类负责。JVM在运行时会产生三个ClassLoader:根装载器,ExtClassLoader(扩展类装载器)和AppClassLoader,其中根装载器不是ClassLoader的子类,由C++编写,因此在java中看不到他,负责装载JRE的核心类库,如JRE目录下的rt.jar,charsets.jar等。ExtClassLoader是ClassLoder的子类,负责装载JRE扩展目录ext下的jar类包;AppClassLoader负责装载classpath路径下的类包,这三个类装载器存在父子层级关系****,即根装载器是ExtClassLoader的父装载器,ExtClassLoader是AppClassLoader的父装载器。默认情况下使用AppClassLoader装载应用程序的类 Java装载类使用“全盘负责委托机制”。“全盘负责”是指当一个ClassLoder装载一个类时,除非显示的使用另外一个ClassLoder,该类所依赖及引用的类也由这个ClassLoder载入;“委托机制”是指先委托父类装载器寻找目标类,只有在找不到的情况下才从自己的类路径中查找并装载目标类。这一点是从安全方面考虑的,试想如果一个人写了一个恶意的基础类(如java.lang.String)并加载到JVM将会引起严重的后果,但有了全盘负责制,java.lang.String永远是由根装载器来装载,避免以上情况发生 除了JVM默认的三个ClassLoder以外,第三方可以编写自己的类装载器,以实现一些特殊的需求。类文件被装载解析后,在JVM中都有一个对应的java.lang.Class对象,提供了类结构信息的描述。数组,枚举及基本数据类型,甚至void都拥有对应的Class对象。Class类没有public的构造方法,Class对象是在装载类时由JVM通过调用类装载器中的defineClass()方法自动构造的
深度分析Java的ClassLoader机制(源码级别) 写在前面:Java中的所有类,必须被装载到jvm中才能运行,这个装载工作是由jvm中的类装载器完成的,类装载器所做的工作实质是把类文件从硬盘读取到内存中,JVM在加载类的时候,都是通过ClassLoader的loadClass()方法来加载class的,loadClass使用双亲委派模式。 为了更好的理解类的加载机制,我们来深入研究一下ClassLoader和他的loadClass()方法。 源码分析 public abstract class ClassLoader ClassLoader类是一个抽象类,sun公司是这么解释这个类的: /** * A class loader is an object that is responsible for loading classes. The * class ClassLoader is an abstract class. Given the binary name of a class, a class loader should attempt to * locate or generate data that constitutes a definition for the class. A * typical strategy is to transform the name into a file name and then read a * "class file" of that name from a file system. **/ 大致意思如下: class loader是一个负责加载classes的对象,ClassLoader类是一个抽象类,需要给出类的二进制名称,class loader尝试定位或者产生一个class的数据,一个典型的策略是把二进制名字转换成文件名然后到文件系统中找到该文件。 接下来我们看loadClass方法的实现方式: protected Class loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded Class c = findLoadedClass(name); if (c == null) { long t0 = System.nanoTime(); try { if (parent != null) { c = parent.loadClass(name, false); } else { c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } if (c == null) { // If still not found, then invoke findClass in order // to find the class. long t1 = System.nanoTime(); c = findClass(name); // this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { resolveClass(c); } return c; } } 还是来看sun公司对该方法的解释: /** * Loads the class with the specified binary name. The * default implementation of this method searches for classes in the * following order: * * * * Invoke {@link #findLoadedClass(String)} to check if the class * has already been loaded. * * Invoke the {@link #loadClass(String) loadClass} method * on the parent class loader. If the parent is null the class * loader built-in to the virtual machine is used, instead. * * Invoke the {@link #findClass(String)} method to find the * class. * * * * If the class was found using the above steps, and the * resolve flag is true, this method will then invoke the {@link * #resolveClass(Class)} method on the resulting Class object. * * Subclasses of ClassLoader are encouraged to override {@link * #findClass(String)}, rather than this method. * * Unless overridden, this method synchronizes on the result of * {@link #getClassLoadingLock getClassLoadingLock} method * during the entire class loading process. * */ 大致内容如下: 使用指定的二进制名称来加载类,这个方法的默认实现按照以下顺序查找类: 调用findLoadedClass(String)方法检查这个类是否被加载过 使用父加载器调用loadClass(String)方法,如果父加载器为Null,类加载器装载虚拟机内置的加载器调用findClass(String)方法装载类, 如果,按照以上的步骤成功的找到对应的类,并且该方法接收的resolve参数的值为true,那么就调用resolveClass(Class)方法来处理类。 ClassLoader的子类最好覆盖findClass(String)而不是这个方法。 除非被重写,这个方法默认在整个装载过程中都是同步的(线程安全的) 接下来,我们开始分析该方法。 **protected Class loadClass(String name, boolean resolve)** 该方法的访问控制符是\`protected\`,也就是说该方法\*\*同包内和派生类中可用\*\* 返回值类型`Class ,这里用到**泛型**。这里使用通配符?作为泛型实参表示对象可以 接受任何类型(类类型)。因为该方法不知道要加载的类到底是什么类,所以就用了通用的泛型。String name要查找的类的名字,boolean resolve,一个标志,true表示将调用resolveClass(c)`处理该类 throws ClassNotFoundException 该方法会抛出找不到该类的异常,这是一个非运行时异常 synchronized (getClassLoadingLock(name)) 看到这行代码,我们能知道的是,这是一个同步代码块,那么synchronized的括号中放的应该是一个对象。我们来看getClassLoadingLock(name)方法的作用是什么: protected Object getClassLoadingLock(String className) { Object lock = this; if (parallelLockMap != null) { Object newLock = new Object(); lock = parallelLockMap.putIfAbsent(className, newLock); if (lock == null) { lock = newLock; } } return lock; } 以上是getClassLoadingLock(name)方法的实现细节,我们看到这里用到变量parallelLockMap ,根据这个变量的值进行不同的操作,如果这个变量是Null,那么直接返回this,如果这个属性不为Null,那么就新建一个对象,然后在调用一个putIfAbsent(className, newLock);方法来给刚刚创建好的对象赋值,这个方法的作用我们一会讲。那么这个parallelLockMap变量又是哪来的那,我们发现这个变量是ClassLoader类的成员变量: private final ConcurrentHashMap parallelLockMap; 这个变量的初始化工作在ClassLoader的构造函数中: private ClassLoader(Void unused, ClassLoader parent) { this.parent = parent; if (ParallelLoaders.isRegistered(this.getClass())) { parallelLockMap = new ConcurrentHashMap(); package2certs = new ConcurrentHashMap(); domains = Collections.synchronizedSet(new HashSet()); assertionLock = new Object(); } else { // no finer-grained lock; lock on the classloader instance parallelLockMap = null; package2certs = new Hashtable(); domains = new HashSet(); assertionLock = this; } } 这里我们可以看到构造函数根据一个属性ParallelLoaders的Registered状态的不同来给parallelLockMap 赋值。 我去,隐藏的好深,好,我们继续挖,看看这个ParallelLoaders又是在哪赋值的呢?我们发现,在ClassLoader类中包含一个静态内部类private static class ParallelLoaders,在ClassLoader被加载的时候这个静态内部类就被初始化。这个静态内部类的代码我就不贴了,直接告诉大家什么意思,sun公司是这么说的:Encapsulates the set of parallel capable loader types,意识就是说:封装了并行的可装载的类型的集合。 上面这个说的是不是有点乱,那让我们来整理一下: 首先,在ClassLoader类中有一个静态内部类ParallelLoaders,他会指定的类的并行能力,如果当前的加载器被定位为具有并行能力,那么他就给parallelLockMap定义,就是new一个 ConcurrentHashMap(),那么这个时候,我们知道如果当前的加载器是具有并行能力的,那么parallelLockMap就不是Null,这个时候,我们判断parallelLockMap是不是Null,如果他是null,说明该加载器没有注册并行能力,那么我们没有必要给他一个加锁的对象,getClassLoadingLock方法直接返回this,就是当前的加载器的一个实例。如果这个parallelLockMap不是null,那就说明该加载器是有并行能力的,那么就可能有并行情况,那就需要返回一个锁对象。然后就是创建一个新的Object对象,调用parallelLockMap的putIfAbsent(className, newLock)方法,这个方法的作用是:首先根据传进来的className,检查该名字是否已经关联了一个value值,如果已经关联过value值,那么直接把他关联的值返回,如果没有关联过值的话,那就把我们传进来的Object对象作为value值,className作为Key值组成一个map返回。然后无论putIfAbsent方法的返回值是什么,都把它赋值给我们刚刚生成的那个Object对象。 这个时候,我们来简单说明一下getClassLoadingLock(String className)的作用,就是: 为类的加载操作返回一个锁对象。为了向后兼容,这个方法这样实现:如果当前的classloader对象注册了并行能力,方法返回一个与指定的名字className相关联的特定对象,否则,直接返回当前的ClassLoader对象。 Class c = findLoadedClass(name); 在这里,在加载类之前先调用findLoadedClass方法检查该类是否已经被加载过,findLoadedClass会返回一个Class类型的对象,如果该类已经被加载过,那么就可以直接返回该对象(在返回之前会根据resolve的值来决定是否处理该对象,具体的怎么处理后面会讲)。 如果,该类没有被加载过,那么执行以下的加载过程 try { if (parent != null) { c = parent.loadClass(name, false); } else { c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } 如果父加载器不为空,那么调用父加载器的loadClass方法加载类,如果父加载器为空,那么调用虚拟机的加载器来加载类。 如果以上两个步骤都没有成功的加载到类,那么 c = findClass(name); 调用自己的findClass(name)方法来加载类。 这个时候,我们已经得到了加载之后的类,那么就根据resolve的值决定是否调用resolveClass方法。resolveClass方法的作用是: 链接指定的类。这个方法给Classloader用来链接一个类,如果这个类已经被链接过了,那么这个方法只做一个简单的返回。否则,这个类将被按照 Java™规范中的Execution描述进行链接。。。 至此,ClassLoader类以及loadClass方法的源码我们已经分析完了,那么。结合源码的分析,我们来总结一下: 总结 java中的类大致分为三种: 1.系统类 2.扩展类 3.由程序员自定义的类 类装载方式,有两种: 1.隐式装载, 程序在运行过程中当碰到通过new 等方式生成对象时,隐式调用类装载器加载对应的类到jvm中。 2.显式装载, 通过class.forname()等方法,显式加载需要的类 类加载的动态性体现: 一个应用程序总是由n多个类组成,Java程序启动时,并不是一次把所有的类全部加载后再运行,它总是先把保证程序运行的基础类一次性加载到jvm中,其它类等到jvm用到的时候再加载,这样的好处是节省了内存的开销,因为java最早就是为嵌入式系统而设计的,内存宝贵,这是一种可以理解的机制,而用到时再加载这也是java动态性的一种体现 java类装载器 Java中的类装载器实质上也是类,功能是把类载入jvm中,值得注意的是jvm的类装载器并不是一个,而是三个,层次结构如下: 为什么要有三个类加载器,一方面是分工,各自负责各自的区块,另一方面为了实现委托模型,下面会谈到该模型 类加载器之间是如何协调工作的 前面说了,java中有三个类加载器,问题就来了,碰到一个类需要加载时,它们之间是如何协调工作的,即java是如何区分一个类该由哪个类加载器来完成呢。 在这里java采用了委托模型机制,这个机制简单来讲,就是“类装载器有载入类的需求时,会先请示其Parent使用其搜索路径帮忙载入,如果Parent 找不到,那么才由自己依照自己的搜索路径搜索类” 下面举一个例子来说明,为了更好的理解,先弄清楚几行代码: Public class Test{ Public static void main(String[] arg){ ClassLoader c = Test.class.getClassLoader(); //获取Test类的类加载器 System.out.println(c); ClassLoader c1 = c.getParent(); //获取c这个类加载器的父类加载器 System.out.println(c1); ClassLoader c2 = c1.getParent();//获取c1这个类加载器的父类加载器 System.out.println(c2); } } 运行结果: 。。。AppClassLoader。。。 。。。ExtClassLoader。。。 Null 可以看出Test是由AppClassLoader加载器加载的,AppClassLoader的Parent 加载器是 ExtClassLoader,但是ExtClassLoader的Parent为 null 是怎么回事呵,朋友们留意的话,前面有提到Bootstrap Loader是用C++语言写的,依java的观点来看,逻辑上并不存在Bootstrap Loader的类实体,所以在java程序代码里试图打印出其内容时,我们就会看到输出为null。 类装载器ClassLoader(一个抽象类)描述一下JVM加载class文件的原理机制 类装载器就是寻找类或接口字节码文件进行解析并构造JVM内部对象表示的组件,在java中类装载器把一个类装入JVM,经过以下步骤: 1、装载:查找和导入Class文件 2、链接:其中解析步骤是可以选择的 (a)检查:检查载入的class文件数据的正确性 (b)准备:给类的静态变量分配存储空间 (c)解析:将符号引用转成直接引用 3、初始化:对静态变量,静态代码块执行初始化工作 类装载工作由ClassLoder和其子类负责。JVM在运行时会产生三个ClassLoader:根装载器,ExtClassLoader(扩展类装载器)和AppClassLoader,其中根装载器不是ClassLoader的子类,由C++编写,因此在java中看不到他,负责装载JRE的核心类库,如JRE目录下的rt.jar,charsets.jar等。ExtClassLoader是ClassLoder的子类,负责装载JRE扩展目录ext下的jar类包;AppClassLoader负责装载classpath路径下的类包,这三个类装载器存在父子层级关系****,即根装载器是ExtClassLoader的父装载器,ExtClassLoader是AppClassLoader的父装载器。默认情况下使用AppClassLoader装载应用程序的类 Java装载类使用“全盘负责委托机制”。“全盘负责”是指当一个ClassLoder装载一个类时,除非显示的使用另外一个ClassLoder,该类所依赖及引用的类也由这个ClassLoder载入;“委托机制”是指先委托父类装载器寻找目标类,只有在找不到的情况下才从自己的类路径中查找并装载目标类。这一点是从安全方面考虑的,试想如果一个人写了一个恶意的基础类(如java.lang.String)并加载到JVM将会引起严重的后果,但有了全盘负责制,java.lang.String永远是由根装载器来装载,避免以上情况发生 除了JVM默认的三个ClassLoder以外,第三方可以编写自己的类装载器,以实现一些特殊的需求。类文件被装载解析后,在JVM中都有一个对应的java.lang.Class对象,提供了类结构信息的描述。数组,枚举及基本数据类型,甚至void都拥有对应的Class对象。Class类没有public的构造方法,Class对象是在装载类时由JVM通过调用类装载器中的defineClass()方法自动构造的
-
京东热 key 探测框架新版发布,单机 QPS 可达 35 万 对于大型的分布式系统来说,热点数据一直都是一个需要重点关注的事情,比如热卖商品热点新闻等就都是属于热点数据的。 通常情况下,这种热点数据都会被放在缓存里面,但是如果突然有大量流量需要访问同一个特定的数据,就会导致流量过于集中,使得很多物理资源无法支撑,如网络带宽、物理存储空间、数据库连接等。 这也是为什么某某明星官宣之后,微博上面就会出现宕机的情况。有时候这种宕机发生后,其他功能都是可以使用的,只是和这个热点有关的内容会无法访问,这其实就和热点数据有关系了。 一般情况下,我们会把热点数据缓存下来,而缓存一般都需要有个固定的key,所以,很多时候我们也称这类问题为热key问题。 如何发现热点数据 一般情况下,我们是可以通过一些手段来识别并发现热key的,主要有以下几种方式: 根据经验,提前预测 这种方法在大多数情况下还是比较奏效的。比较常见的就是电商系统中,会在做秒杀、抢购等业务开始前就能预测出热key。 但是,这种方式的局限性也很大,就是有些热key是完全没办法预测的,比如明星什么时候要官宣这种事情就无法预测。 实时收集 还有一种热点数据的发现机制,那就是实时的做收集,比如在客户端、服务端或者在代理层,都可以对实时数据进行采集,然后进行统计汇总。 达到一定的数量之后,就会被识别为热key 如何解决热key问题 解决热key问题最主要的方式就是加缓存。通过缓存的方式尽量减少系统交互,使得用户请求可以提前返回。 这样即能提升用户体验,也能减少系统压力。 缓存的方式有很多,有些数据可以缓存在客户的客户端浏览器中,有些数据可以缓存在距离用户就近的DNS中,有些数据可以通过Redis等这类缓存框架进行缓存,还有些数据可以通过服务器本地缓存进行。 这种使用多个缓存的情况,就组成了二级缓存、三级缓存等多级缓存了。总之,通过缓存的方式尽量减少用户的的访问链路的长度。 有了缓存之后,还会带来一个问题,那就是热点数据如果都被缓存在同一个缓存服务器上,那么这个服务器也可能被打挂。 所以,很多人在加了缓存之后, 还可能同时部署多个缓存服务器,如Redis同时部署多个服务器集群。并且实时的将热点数据同步分发到多个缓存服务器集群中,一旦有的集群扛不住了,立刻做切换。 单纯的对于Redis热key缓存来说,Redis是有分片机制的,同一个热key可能会都保存在同一个分片中,所以还可以在多个分片中都把热key同步一份,使得查询可以同时从多个分片进行,减少某一个分片的压力。 因为有分片,还有一种情况,就是有可能多个热key都会分到同一个分片中,为了减少这种情况的发生,可以增加更多的分片来分担流量。 京东的热key探测 前面简单介绍了热key的发现与解决,这种问题其实最明显的发生就是在电商系统或者像微博这种社交系统中。 所以很多公司内部也有很多成熟的方案。 今天想介绍一个京东内部的框架——JD-hotkey ,这是京东 APP 后台热数据探测框架。 这个框架在Gitee上面开源了(https://gitee.com/jd-platform-opensource/hotkey ),官方描述是这样的: 对任意突发性的无法预先感知的热点数据,包括并不限于热点数据(如突发大量请求同一个商品)、热用户(如恶意爬虫刷子)、热接口(突发海量请求同一个接口)等,进行毫秒级精准探测到。 然后对这些热数据、热用户等,推送到所有服务端JVM内存中,以大幅减轻对后端数据存储层的冲击,并可以由使用者决定如何分配、使用这些热key(譬如对热商品做本地缓存、对热用户进行拒绝访问、对热接口进行熔断或返回默认值)。 这些热数据在整个服务端集群内保持一致性,并且业务隔离,worker端性能强悍。 JD-hotkey探测框架,历经多次高压压测和2020年京东618大促考验。在上线运行的这段时间内,每天探测的key数量数十亿计,精准捕获了大量爬虫、刷子用户,另准确探测大量热门商品并毫秒级推送到各个服务端内存,大幅降低了热数据对数据层的查询压力,提升了应用性能。 该框架历经多次压测,8核单机worker端每秒可接收处理16万个key探测任务,16核单机至少每秒平稳处理30万以上,实际压测达到37万,CPU平稳支撑,框架无异常。 简单点说,这个框架的主要功能就是热数据探测并推送至集群各个服务器。这个框架主要适用于以下场景: mysql 热数据本地缓存 redis 热数据本地缓存 黑名单用户本地缓存 爬虫用户限流 接口、用户维度限流 单机接口、用户维度限流限流 集群用户维度限流 集群接口维度限流 在官方文档中,大概介绍了一下这个框架的工作原理,这个框架主要由四个主要部分,分别是ETCD集群、worker集群、client客户端以及dashboard控制台。 下图介绍了一下各个部分的主要功能及简单原理:  这个框架的使用还是相对简单的,主要分为以下几个步骤: 搭建etcd集群 启动dashboard可视化界面 启动worker集群 client启动 详情见 https://gitee.com/jd-platform-opensource/hotkey 中的安装教程部分,这里就不详细介绍了。 近日,这个框架在618稳定版0.2版基础上,引入了proto序列化方式,并优化了传输对象。 worker单机性能从618大促稳定版的20万QPS稳定,30万极限,提升至30万稳定,37万极限。且cpu峰值下降了15%。 该中间件目前在京东内部10余个核心部门接入使用,服务于京东App服务端前台、中台,数据中台等多个核心业务线。 最后,目前关于热key的探测方面,京东做的还是不错的,至少他们开源了一个工具出来,给大家多了一个选择。致敬开源,给京东的开源精神点个赞!
-
2020年Java程序员应该学习的10大技术 对于Java开发人员来说,最近几年的时间中,Java生态诞生了很多东西。每6个月更新一次Java版本,以及发布很多流行的框架,如Spring 5、Spring Security 5和Spring Boot 2等,这些都给我们带来了很大的挑战。 在2019年初,我认为Java 10还是比较新的,但是,在我学习完所有Java 10的特性之前,Java 11、Java 12、Java 12 已经接踵而至,对于工作繁忙的程序员们来说,大多数人都根本没有时间看这些。基本是都是了解一些有用的新特性而已。 Java的版本迭代速度实在是太快了,也带来了很多有趣的特性,如本地变量类型推断、switch表达式、文本块支持等。我在Java 9 ← 2017,2019 Java → 13 ,都发生了什么?中记录了这些变化。 Java系第一大框架,Spring亦是如此,很多人的项目还在用Spring Security 3.1 ,甚至不知道Spring 4.0和Spring Security 4.0都有哪些特性。但是,Spring和Spring Security都已经出到了5.0版本。 以下是我列出的2020年Java开发者应该学习的技术: 1、DevOps (Docker and Jenkins) 过去的一年,越来越多的公司正在转型DevOps,DevOps非常庞大,需要学习很多工具和原理,但你不需要担心。有大神已经分享了DevOps路线图(https://github.com/kamranahmedse/developer-roadmap),可以按照这个路线图以自己的速度学习和掌握DevOps。  如果你是一个有经验的Java程序员,愿意学习环境管理、自动化和整体改进,你也可以成为DevOps工程师。 2、Java 9 – Java 15 相信现在很多Java开发人员主要使用的Java版本还是以Java 8为主,虽然Java 9 – Java 13已经推出了有一段时间。 但是作为Java程序员,我们可能因为某些原因没办法在线上环境真正的进行JDK的升级,但是花一些时间学习Java 9、Java 10、Java 11、Java 12和 Java 13的新特性还是有必要的。 另外,大家可以重点关注一些关键特性,如GC相关的特性、对编码风格有改变的特性等。还有就是Java的LTS版本(Java 8、Java 11)要重点学习。 还要提醒大家一点,在2020年,Oracle还会推出Java 14 和 Java 15!!!如果你在使用Java 7的话,马上就要被”套圈”了! 3、Spring Framework 5 2017年我们见证了Spring和Java生态系统的许多重大升级,Spring 5.0就是其中之一。 Spring 5 的新反应式编程模型、HTTP/2 支持,以及 Spring 通过 Kotlin 对函数式编程的全面支持这些都值得我们好好了解一下。 4、Spring Security 5.0 Spring Security 5.0 提供了许多新功能,并支持 Spring Framework 5.0,总共有 400 多个增强功能和 bug 修复。在Spring Security 5.0.0之前,密码是明文保存,十分不安全。因为这一次发布的是大版本,所以我们决定使用更安全的密码存储方式。 Spring Security 5.0.0的主要亮点在于它只需要最小化的JDK 8、反应式安全特性、OAuth 2.0(OIDC)和现代密码存储。 5、Spring Boot 2 Spring Boot 2.0 基于 Spring 5 Framework ,提供了 异步非阻塞 IO 的响应式 Stream 、非堵塞的函数式 Reactive Web 框架 Spring WebFlux等特性。很多使用过SpringBoot的人都知道,使用SpringBoot搭建Web应用真的是又快又好,相信Spring Boot 2会带来更多惊喜。 6、Hadoop、Spark 和 Kafka 另外在2020年Java程序员需要学习的是大数据相关的知识。特别是Apache Spark 和 Kafka两个框架。  如果你也想在2020年学习大数据,也一定绕不开Hadoop生态。 7、Elasticsearch 全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。维基百科、Stack Overflow、Github 都在使用它。 Elasticsearch是一个基于Lucene库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎,具有HTTP Web接口和无模式JSON文档。Elasticsearch是用Java开发的,并在Apache许可证下作为开源软件发布。 8、ServiceMesh 这两年很火,火的一塌糊涂。在2019年,但凡是程序员相关的大会,如果没有讲ServiceMest的专题,那都不好意思开。 所有人都在说 ServiceMesh; 几乎没人知道怎么落地 ServiceMesh; 但是大家都觉得其他人在大力做 ServiceMesh; 所以大家都宣称自己在做 ServiceMesh; 这个号称下一代微服务架构的概念,现在对于大多数人来说根本不知道是啥。只知道很多大厂宣称自己在做,很多大牛在布道。 9、Serverless 无服务器运算(英语:Serverless computing),又被称为功能即服务(Function-as-a-Service,缩写为 FaaS),是云计算的一种模型。以平台即服务(PaaS)为基础,无服务器运算提供一个微型的架构,终端客户不需要部署、配置或管理服务器服务,代码运行所需要的服务器服务皆由云平台来提供。这东西,听上去就很高大上。 10、Kotlin 如果大家有关注Java 13的新特性的话,一定知道推出了字符串文本块的功能,这个功能其实是借鉴的Kotlin,除此之外,最近几年,Java有很多特性都在借鉴Kotlin,相比较于Java,Kotlin更加简洁,而且Kotlin编出来的代码也可以直接通过JVM运行。 Kotlin是一种在Java虚拟机上运行的静态类型编程语言,它也可以被编译成为JavaScript源代码。Kotlin的设计初衷就是用来生产高性能要求的程序的,所以运行起来和Java也是不相上下。Kotlin可以从 JetBrains InteilliJ Idea IDE这个开发工具以插件形式使用。 总结 以上,就是作者总结的建议Java程序员在2020年学习的一些技术,希望能给爱学习的你一个参考。其中有一些是一定要学习的,还有一些是看大家的精力情况酌情考虑。
-
牢记面向对象五个基本原则 写在前面:面向对象的三个基本要素和五个基本原则,很早以前就知道.但是一直没有当做很重要的东西去理解,以为就是概念性的东西知道就好了.最近再看代码重构的知识.发现要想写出干净的代码,就一定要遵守这五个原则. 单一职责原则(Single-Resposibility Principle) 其核心思想为:一个类,最好只做一件事,只有一个引起它的变化。单一职责原则可以看做是低耦合、高内聚在面向对象原则上的引申,将职责定义为引起变化的原因,以提高内聚性来减少引起变化的原因。职责过多,可能引起它变化的原因就越多,这将导致职责依赖,相互之间就产生影响,从而大大损伤其内聚性和耦合度。通常意义下的单一职责,就是指只有一种单一功能,不要为类实现过多的功能点,以保证实体只有一个引起它变化的原因。 专注,是一个人优良的品质;同样的,单一也是一个类的优良设计。交杂不清的职责将使得代码看起来特别别扭牵一发而动全身,有失美感和必然导致丑陋的系统错误风险。 开放封闭原则(Open-Closed principle) 其核心思想是:软件实体应该是可扩展的,而不可修改的。也就是,对扩展开放,对修改封闭的。开放封闭原则主要体现在两个方面1、对扩展开放,意味着有新的需求或变化时,可以对现有代码进行扩展,以适应新的情况。2、对修改封闭,意味着类一旦设计完成,就可以独立完成其工作,而不要对其进行任何尝试的修改。 实现开开放封闭原则的核心思想就是对抽象编程,而不对具体编程,因为抽象相对稳定。让类依赖于固定的抽象,所以修改就是封闭的;而通过面向对象的继承和多态机制,又可以实现对抽象类的继承,通过覆写其方法来改变固有行为,实现新的拓展方法,所以就是开放的。 “需求总是变化”没有不变的软件,所以就需要用封闭开放原则来封闭变化满足需求,同时还能保持软件内部的封装体系稳定,不被需求的变化影响。 Liskov替换原则(Liskov-Substituion Principle) 其核心思想是:子类必须能够替换其基类。这一思想体现为对继承机制的约束规范,只有子类能够替换基类时,才能保证系统在运行期内识别子类,这是保证继承复用的基础。在父类和子类的具体行为中,必须严格把握继承层次中的关系和特征,将基类替换为子类,程序的行为不会发生任何变化。同时,这一约束反过来则是不成立的,子类可以替换基类,但是基类不一定能替换子类。 Liskov替换原则,主要着眼于对抽象和多态建立在继承的基础上,因此只有遵循了Liskov替换原则,才能保证继承复用是可靠地。实现的方法是面向接口编程:将公共部分抽象为基类接口或抽象类,通过Extract Abstract Class,在子类中通过覆写父类的方法实现新的方式支持同样的职责。 Liskov替换原则是关于继承机制的设计原则,违反了Liskov替换原则就必然导致违反开放封闭原则。 Liskov替换原则能够保证系统具有良好的拓展性,同时实现基于多态的抽象机制,能够减少代码冗余,避免运行期的类型判别。 依赖倒置原则(Dependecy-Inversion Principle) 其核心思想是:依赖于抽象。具体而言就是高层模块不依赖于底层模块,二者都同依赖于抽象;抽象不依赖于具体,具体依赖于抽象。 我们知道,依赖一定会存在于类与类、模块与模块之间。当两个模块之间存在紧密的耦合关系时,最好的方法就是分离接口和实现:在依赖之间定义一个抽象的接口使得高层模块调用接口,而底层模块实现接口的定义,以此来有效控制耦合关系,达到依赖于抽象的设计目标。 抽象的稳定性决定了系统的稳定性,因为抽象是不变的,依赖于抽象是面向对象设计的精髓,也是依赖倒置原则的核心。 依赖于抽象是一个通用的原则,而某些时候依赖于细节则是在所难免的,必须权衡在抽象和具体之间的取舍,方法不是一层不变的。依赖于抽象,就是对接口编程,不要对实现编程。 接口隔离原则(Interface-Segregation Principle) 其核心思想是:使用多个小的专门的接口,而不要使用一个大的总接口。 具体而言,接口隔离原则体现在:接口应该是内聚的,应该避免“胖”接口。一个类对另外一个类的依赖应该建立在最小的接口上,不要强迫依赖不用的方法,这是一种接口污染。 接口有效地将细节和抽象隔离,体现了对抽象编程的一切好处,接口隔离强调接口的单一性。而胖接口存在明显的弊端,会导致实现的类型必须完全实现接口的所有方法、属性等;而某些时候,实现类型并非需要所有的接口定义,在设计上这是“浪费”,而且在实施上这会带来潜在的问题,对胖接口的修改将导致一连串的客户端程序需要修改,有时候这是一种灾难。在这种情况下,将胖接口分解为多个特点的定制化方法,使得客户端仅仅依赖于它们的实际调用的方法,从而解除了客户端不会依赖于它们不用的方法。 分离的手段主要有以下两种:1、委托分离,通过增加一个新的类型来委托客户的请求,隔离客户和接口的直接依赖,但是会增加系统的开销。2、多重继承分离,通过接口多继承来实现客户的需求,这种方式是较好的。 以上就是5个基本的面向对象设计原则,它们就像面向对象程序设计中的金科玉律,遵守它们可以使我们的代码更加鲜活,易于复用,易于拓展,灵活优雅。不同的设计模式对应不同的需求,而设计原则则代表永恒的灵魂,需要在实践中时时刻刻地遵守。就如ARTHUR J.RIEL在那边《OOD启示录》中所说的:“你并不必严格遵守这些原则,违背它们也不会被处以宗教刑罚。但你应当把这些原则看做警铃,若违背了其中的一条,那么警铃就会响起。”
-
[转]Java的可变类型参数 Java1.5增加了新特性:可变参数适用于参数个数不确定,类型确定的情况,java把可变参数当做数组处理。注意:可变参数必须位于最后一项。当可变参数个数多余一个时,必将有一个不是最后一项,所以只支持有一个可变参数。因为参数个数不定,所以当其后边还有相同类型参数时,java无法区分传入的参数属于前一个可变参数还是后边的参数,所以只能让可变参数位于最后一项。 可变参数的特点: (1)、只能出现在参数列表的最后; (2)、位于变量类型和变量名之间,前后有无空格都可以; (3)、调用可变参数的方法时,编译器为该可变参数隐含创建一个数组,在方法体中一数组的形式访问可变参数。 public class Varable { public static void main(String [] args){ System.out.println(add(2,3)); System.out.println(add(2,3,5)); } public static int add(int x,int ...args){ int sum=x; for(int i=0;i



![[转]Java的可变类型参数](http://blog.kuydata.cn/usr/themes/joe/assets/images/thumb/28.jpg?version=1)
