找到
191
篇与
Java
相关的结果
- 第 37 页
-
 Java 7 源码学习系列(三)——BigInteger 在java中,有很多基本数据类型我们可以直接使用,比如用于表示浮点型的float、double,用于表示字符型的char,用于表示整型的int、short、long等。但是,拿整数来说,如果我们想要表示一个非常大的整数,比如说超过64位,那么能表示数字最大的long也无法存取这样的数字时,我们怎么办。以前的做法是把数字存在字符串中,大数之间的四则运算及其它运算都是通过数组完成。JDK也有类似的实现,那就是BigInteger。 什么是BigInteger(定义) BigInteger类的基本结构如下所示: java.lang.Object |_java.lang.Number |_java.math.BigInteger BigInteger已实现的接口:Serializable, Comparable 类定义如下: public class BigInteger extends Number implements Comparable{} BigInteger是不可变的任意精度的整数。所有操作中,都以二进制补码形式表示 BigInteger(如 Java 的基本整数类型)。BigInteger 提供所有 Java 的基本整数操作符的对应物,并提供 java.lang.Math 的所有相关方法。另外,BigInteger 还提供以下运算:模算术、GCD 计算、质数测试、素数生成、位操作以及一些其他操作。 属性 下面看看BigInteger有哪些重点的属性,主要的有下面两个: final int signum signum属性是为了区分:正负数和0的标志位,整数用1表示,负数用-1表示,零用0表示。 final int[] mag mag是magnitude的缩写形式,mag数组是存储BigInteger数值大小的,采用big-endian的顺序,也就是高位字节存入低地址,低位字节存入高地址,依次排列的方式。 我们来分析一下为什么BigInteger中要有这两个成员变量。 我们知道,BigInteger存储大数的方式就是将数字存储在一个整型的数组中(具体怎么存,后面有谈),这样就能解决可以存很多很多位数字的问题。那么,只用一个整型数组的话,如何表示一个整数的正负呢?那么就需要有一个单独的成员变量来标明该数的正负。 构造函数 public BigInteger(byte[] val) { if (val.length == 0) throw new NumberFormatException("Zero length BigInteger"); if (val[0] < 0) { mag = makePositive(val); //这个函数的作用是将负数的byte字节数组转换为正值。 signum = -1; //如果数组第一个值为负数,则将数组变正存入mag,signum赋-1 } else { mag = stripLeadingZeroBytes(val);//如果非负,则可直接去掉前面无效零,再赋给mag signum = (mag.length == 0 ? 0 : 1); } } 将包含 BigInteger 的二进制补码表示形式的 byte 数组转换为 BigInteger。输入数组假定为 big-endian 字节顺序:最高有效字节在第零个元素中。 再来看另外一种构造BigInteger的方式:public BigInteger(String val) 这个构造函数接收一个字符串,然后直接将字符串转换成BigInteger类型。 public static void main(String[] args) { BigInteger bigInteger = new BigInteger("123456789987654321123456789987654321123456789987654321"); System.out.println(bigInteger); } 这看起来很方便,只要我们明确的知道我们想要的数字的字符串形式,就可以直接用他构造一个BigInteger 接着,我们就分析一下这个函数是怎么实现的,难道只是把我们传入的字符串直接存到mag数组里面了么?以下是该构造函数的实现: public BigInteger(String val) { this(val, 10); } 这个函数调用了另外一个构造方法,那么我们就直接分析这个构造方法: public BigInteger(String val, int radix)该构造函数就是把一个字符串val所代表的的大整数转换并保存mag数组中,并且val所代表的字符串可以是不同的进制(radix决定),比如,我们这样构造一个BigInteger:BigInteger bigInteger = new BigInteger("101",2);,那么我们得到的结果就是5。分析该构造函数源码之前,先想一个问题,构造一个大整数开始最主要的问题是如何把一个大数保存到mag数组中,通常我们自己实现的话很有可能是数组每块存一位数(假设大数为10进制),但这样的话想想也知道太浪费空间,因为一个int值可以保存远不止一位十进制数. Java语言里每个int值大小范围是-2^31至2^31-1 即-2147483648~2147483647,因此一个int值最多可保存一个10位十进制的整数,但是为了防止超出范围(2222222222这样的数int已经无法存储),保险的方式就是每个int保存9位的十进制整数.JDK里的mag数组即是这样的保存方式. 因此若一串数为:18927348347389543834934878. 划分之后就为:18927348 | 347389543 | 834934878. mag[0]保存18927348 ,mag[1]保存347389543 ,mag[2]保存834934878 这样划分可以最大利用每一个int值,使得mag数组占用更小的空间.当然这只是第一步. 划分的问题还没有说完,上述构造函数能够支持不同进制的数,最终转换到mag数组里面的数都是十进制,那么不同进制的大数,每次选择划分的位数就不相同,若是2进制,每次就可以选择30位来存储到一个int数中(int值大小范围是-2^31至2^31-1),若是3进制3^19>> 10) + 1); int numWords = (numBits + 31) /32; mag = new int[numWords]; //开始按照digitsPerInt截取字符串里的数 //将不够digitsPerInt[radix]的先取出来转换 int firstGroupLen = numDigits % digitsPerInt[radix]; if (firstGroupLen == 0) firstGroupLen = digitsPerInt[radix]; //把第一段的数字放入mag数组的最后一位 String group = val.substring(cursor, cursor += firstGroupLen); mag[mag.length - 1] = Integer.parseInt(group, radix); if (mag[mag.length - 1] < 0) throw new NumberFormatException("Illegal digit"); //剩下的一段段转换 int superRadix = intRadix[radix]; int groupVal = 0; while (cursor < val.length()) { group = val.substring(cursor, cursor += digitsPerInt[radix]); groupVal = Integer.parseInt(group, radix); if (groupVal < 0) throw new NumberFormatException("Illegal digit"); destructiveMulAdd(mag, superRadix, groupVal); } mag = trustedStripLeadingZeroInts(mag); } 现在我对最后的几行还没有分析,是因为有一个intRadix数组我们还没有解释.intRadix数组其实就是一个保存了对应各种radix的最佳进制的表, 上面我们说过了对于十进制我们选择一次性截取9位数,这样能充分利用一个int变量同时还可保证不超出int的范围,因此intRadix[10]=10^9=1000000000. intRadix[3]=3^19=1162261467. 也就是每次截取的数都不会超过其radix对应的最佳进制.举例 十进制数18927348347389543834934878 其最终转换为: 18927348*(10^9)^2 +347389543*(10^9)+834934878,最终从整体上来看mag数组保存的是一个10^9进制的数. intRadix如下: private static int intRadix[] = {0, 0, 0x40000000, 0x4546b3db, 0x40000000, 0x48c27395, 0x159fd800, 0x75db9c97, 0x40000000, 0x17179149, 0x3b9aca00, 0xcc6db61, 0x19a10000, 0x309f1021, 0x57f6c100, 0xa2f1b6f, 0x10000000, 0x18754571, 0x247dbc80, 0x3547667b, 0x4c4b4000, 0x6b5a6e1d, 0x6c20a40, 0x8d2d931, 0xb640000, 0xe8d4a51, 0x1269ae40, 0x17179149, 0x1cb91000, 0x23744899, 0x2b73a840, 0x34e63b41, 0x40000000, 0x4cfa3cc1, 0x5c13d840, 0x6d91b519, 0x39aa400 }; intRadix[10]=0x3b9aca00 = 1000000000; intRadix[3]=0x4546b3db=1162261467; 我们注意到 numWords = (numBits + 31) /32. 初始数组的大小并不是大整数划分的数目而是将计算大整数对应的二进制位数(加上31确保numWords大于0)然后除以32得到,因此mag数组中每一个int数的32位是被完全利用的,也就是把每个int数当成无符号数来看待.若不完全利用int的32位的话,我们完全可以根据划分的结果来确定mag数组的初始大小,之前的例子:18927348 | 347389543 | 834934878,我们知道10进制数每次选择9位不会越界,我们可以直观的得到mag数组的大小为3,但是这样的话每个int元素仍然有些空闲的位没有利用. 因此我们之前的划分方法只是整个数组初始化的想象中第一步. 这个例子按照numWords = (numBits + 31) /32这样计算最后得到的应当仍是3.但是若是再大一些的数串结果就不一定一样,积少成多,很大的数串时节省的空间就能体现出来啦. Java没有无符号int数,因此mag数组中常常会符号为负的元素. 而最终把原大整数转换为mag数组保存的radix对应的最佳进制数的过程由destructiveMulAdd完成.现在把构造函数的最后一部分的和方法destructiveMulAdd的解析附上: int superRadix = intRadix[radix]; int groupVal = 0; while (cursor < val.length()) { //选取新的一串数 group = val.substring(cursor, cursor += digitsPerInt[radix]); groupVal = Integer.parseInt(group, radix);//转换为十进制整数 if (groupVal < 0) throw new NumberFormatException("Illegal digit"); //mag*superRadix+groupVal.类似于:18927348*10^9+347389543 destructiveMulAdd(mag, superRadix, groupVal); } //去掉mag数组前面的0,使得数组元素以非0开始. mag = trustedStripLeadingZeroInts(mag); private final static long LONG_MASK = 0xffffffffL; // Multiply x array times word y in place, and add word z private static void destructiveMulAdd(int[] x, int y, int z) { // Perform the multiplication word by word //将y与z转换为long类型 long ylong = y & LONG_MASK; long zlong = z & LONG_MASK; int len = x.length; long product = 0; long carry = 0; //从低位到高位分别与y相乘,每次都加上之前的进位,和传统乘法一模一样. for (int i = len-1; i >= 0; i--) { //每次相乘时将x[i]转换为long,这样其32位数就可转变为其真正代表的数 product = ylong * (x[i] & LONG_MASK) + carry; //x[i]取乘积的低32位. x[i] = (int)product; //高32位为进位数,留到下次循环相加 carry = product >>> 32; } // Perform the addition //执行加z //mag最低位转换为long后与z相加 long sum = (x[len-1] & LONG_MASK) + zlong; //mag最低位保留相加结果的低32位. x[len-1] = (int)sum; //高32位当成进位数 carry = sum >>> 32; //和传统加法一样进位数不断向高位加 for (int i = len-2; i >= 0; i--) { sum = (x[i] & LONG_MASK) + carry; x[i] = (int)sum; carry = sum >>> 32; } } 整个过程下来,因为保存的方法和我们脑海中那简单的存储方法会有不同,最终mag数组里的元素跟原先的字符串就会有很大的不同,但实质上还是表示着相同的数,现把18927348347389543834934878例子的构造过程展示出: 初始化之后计算得numBits=87,这样数组初始化大小numWords=3. 进入最终的循环前mag数组:[0] [0] [18927348] 第一次循环后: [0] [4406866] [-1295432089] (1892734810^9+347389543) 第二次循环后: [1026053] [-1675546271] [440884830]. ((1892734810^9+347389543)*10^9+834934878) 最终我们就把18927348347389543834934878 转换成10^9进制的数保存到了mag数组中.虽然最终的结果我们让我们不太熟悉,但是其中数串划分的方法和数组节省空间的思想都是值得学习的 现在有最后一个问题,如何mag数组转换为原来的数串呢?JDK里面是通过不断做除法取余实现的,BigInteger类的实例在调用toString方法的时候会返回原先的数串.代码如下: public String toString(int radix) { if (signum == 0) return "0"; if (radix < Character.MIN_RADIX || radix > Character.MAX_RADIX) radix = 10; // Compute upper bound on number of digit groups and allocate space int maxNumDigitGroups = (4*mag.length + 6)/7; String digitGroup[] = new String[maxNumDigitGroups]; // Translate number to string, a digit group at a time BigInteger tmp = this.abs(); int numGroups = 0; while (tmp.signum != 0) { BigInteger d = longRadix[radix]; MutableBigInteger q = new MutableBigInteger(), a = new MutableBigInteger(tmp.mag), b = new MutableBigInteger(d.mag); MutableBigInteger r = a.divide(b, q); BigInteger q2 = q.toBigInteger(tmp.signum * d.signum); BigInteger r2 = r.toBigInteger(tmp.signum * d.signum); digitGroup[numGroups++] = Long.toString(r2.longValue(), radix); tmp = q2; } // Put sign (if any) and first digit group into result buffer StringBuilder buf = new StringBuilder(numGroups*digitsPerLong[radix]+1); if (signum=0; i--) { // Prepend (any) leading zeros for this digit group int numLeadingZeros = digitsPerLong[radix]-digitGroup[i].length(); if (numLeadingZeros != 0) buf.append(zeros[numLeadingZeros]); buf.append(digitGroup[i]); } return buf.toString(); } private static String zeros[] = new String[64]; static { zeros[63] = "000000000000000000000000000000000000000000000000000000000000000"; for (int i=0; i
Java 7 源码学习系列(三)——BigInteger 在java中,有很多基本数据类型我们可以直接使用,比如用于表示浮点型的float、double,用于表示字符型的char,用于表示整型的int、short、long等。但是,拿整数来说,如果我们想要表示一个非常大的整数,比如说超过64位,那么能表示数字最大的long也无法存取这样的数字时,我们怎么办。以前的做法是把数字存在字符串中,大数之间的四则运算及其它运算都是通过数组完成。JDK也有类似的实现,那就是BigInteger。 什么是BigInteger(定义) BigInteger类的基本结构如下所示: java.lang.Object |_java.lang.Number |_java.math.BigInteger BigInteger已实现的接口:Serializable, Comparable 类定义如下: public class BigInteger extends Number implements Comparable{} BigInteger是不可变的任意精度的整数。所有操作中,都以二进制补码形式表示 BigInteger(如 Java 的基本整数类型)。BigInteger 提供所有 Java 的基本整数操作符的对应物,并提供 java.lang.Math 的所有相关方法。另外,BigInteger 还提供以下运算:模算术、GCD 计算、质数测试、素数生成、位操作以及一些其他操作。 属性 下面看看BigInteger有哪些重点的属性,主要的有下面两个: final int signum signum属性是为了区分:正负数和0的标志位,整数用1表示,负数用-1表示,零用0表示。 final int[] mag mag是magnitude的缩写形式,mag数组是存储BigInteger数值大小的,采用big-endian的顺序,也就是高位字节存入低地址,低位字节存入高地址,依次排列的方式。 我们来分析一下为什么BigInteger中要有这两个成员变量。 我们知道,BigInteger存储大数的方式就是将数字存储在一个整型的数组中(具体怎么存,后面有谈),这样就能解决可以存很多很多位数字的问题。那么,只用一个整型数组的话,如何表示一个整数的正负呢?那么就需要有一个单独的成员变量来标明该数的正负。 构造函数 public BigInteger(byte[] val) { if (val.length == 0) throw new NumberFormatException("Zero length BigInteger"); if (val[0] < 0) { mag = makePositive(val); //这个函数的作用是将负数的byte字节数组转换为正值。 signum = -1; //如果数组第一个值为负数,则将数组变正存入mag,signum赋-1 } else { mag = stripLeadingZeroBytes(val);//如果非负,则可直接去掉前面无效零,再赋给mag signum = (mag.length == 0 ? 0 : 1); } } 将包含 BigInteger 的二进制补码表示形式的 byte 数组转换为 BigInteger。输入数组假定为 big-endian 字节顺序:最高有效字节在第零个元素中。 再来看另外一种构造BigInteger的方式:public BigInteger(String val) 这个构造函数接收一个字符串,然后直接将字符串转换成BigInteger类型。 public static void main(String[] args) { BigInteger bigInteger = new BigInteger("123456789987654321123456789987654321123456789987654321"); System.out.println(bigInteger); } 这看起来很方便,只要我们明确的知道我们想要的数字的字符串形式,就可以直接用他构造一个BigInteger 接着,我们就分析一下这个函数是怎么实现的,难道只是把我们传入的字符串直接存到mag数组里面了么?以下是该构造函数的实现: public BigInteger(String val) { this(val, 10); } 这个函数调用了另外一个构造方法,那么我们就直接分析这个构造方法: public BigInteger(String val, int radix)该构造函数就是把一个字符串val所代表的的大整数转换并保存mag数组中,并且val所代表的字符串可以是不同的进制(radix决定),比如,我们这样构造一个BigInteger:BigInteger bigInteger = new BigInteger("101",2);,那么我们得到的结果就是5。分析该构造函数源码之前,先想一个问题,构造一个大整数开始最主要的问题是如何把一个大数保存到mag数组中,通常我们自己实现的话很有可能是数组每块存一位数(假设大数为10进制),但这样的话想想也知道太浪费空间,因为一个int值可以保存远不止一位十进制数. Java语言里每个int值大小范围是-2^31至2^31-1 即-2147483648~2147483647,因此一个int值最多可保存一个10位十进制的整数,但是为了防止超出范围(2222222222这样的数int已经无法存储),保险的方式就是每个int保存9位的十进制整数.JDK里的mag数组即是这样的保存方式. 因此若一串数为:18927348347389543834934878. 划分之后就为:18927348 | 347389543 | 834934878. mag[0]保存18927348 ,mag[1]保存347389543 ,mag[2]保存834934878 这样划分可以最大利用每一个int值,使得mag数组占用更小的空间.当然这只是第一步. 划分的问题还没有说完,上述构造函数能够支持不同进制的数,最终转换到mag数组里面的数都是十进制,那么不同进制的大数,每次选择划分的位数就不相同,若是2进制,每次就可以选择30位来存储到一个int数中(int值大小范围是-2^31至2^31-1),若是3进制3^19>> 10) + 1); int numWords = (numBits + 31) /32; mag = new int[numWords]; //开始按照digitsPerInt截取字符串里的数 //将不够digitsPerInt[radix]的先取出来转换 int firstGroupLen = numDigits % digitsPerInt[radix]; if (firstGroupLen == 0) firstGroupLen = digitsPerInt[radix]; //把第一段的数字放入mag数组的最后一位 String group = val.substring(cursor, cursor += firstGroupLen); mag[mag.length - 1] = Integer.parseInt(group, radix); if (mag[mag.length - 1] < 0) throw new NumberFormatException("Illegal digit"); //剩下的一段段转换 int superRadix = intRadix[radix]; int groupVal = 0; while (cursor < val.length()) { group = val.substring(cursor, cursor += digitsPerInt[radix]); groupVal = Integer.parseInt(group, radix); if (groupVal < 0) throw new NumberFormatException("Illegal digit"); destructiveMulAdd(mag, superRadix, groupVal); } mag = trustedStripLeadingZeroInts(mag); } 现在我对最后的几行还没有分析,是因为有一个intRadix数组我们还没有解释.intRadix数组其实就是一个保存了对应各种radix的最佳进制的表, 上面我们说过了对于十进制我们选择一次性截取9位数,这样能充分利用一个int变量同时还可保证不超出int的范围,因此intRadix[10]=10^9=1000000000. intRadix[3]=3^19=1162261467. 也就是每次截取的数都不会超过其radix对应的最佳进制.举例 十进制数18927348347389543834934878 其最终转换为: 18927348*(10^9)^2 +347389543*(10^9)+834934878,最终从整体上来看mag数组保存的是一个10^9进制的数. intRadix如下: private static int intRadix[] = {0, 0, 0x40000000, 0x4546b3db, 0x40000000, 0x48c27395, 0x159fd800, 0x75db9c97, 0x40000000, 0x17179149, 0x3b9aca00, 0xcc6db61, 0x19a10000, 0x309f1021, 0x57f6c100, 0xa2f1b6f, 0x10000000, 0x18754571, 0x247dbc80, 0x3547667b, 0x4c4b4000, 0x6b5a6e1d, 0x6c20a40, 0x8d2d931, 0xb640000, 0xe8d4a51, 0x1269ae40, 0x17179149, 0x1cb91000, 0x23744899, 0x2b73a840, 0x34e63b41, 0x40000000, 0x4cfa3cc1, 0x5c13d840, 0x6d91b519, 0x39aa400 }; intRadix[10]=0x3b9aca00 = 1000000000; intRadix[3]=0x4546b3db=1162261467; 我们注意到 numWords = (numBits + 31) /32. 初始数组的大小并不是大整数划分的数目而是将计算大整数对应的二进制位数(加上31确保numWords大于0)然后除以32得到,因此mag数组中每一个int数的32位是被完全利用的,也就是把每个int数当成无符号数来看待.若不完全利用int的32位的话,我们完全可以根据划分的结果来确定mag数组的初始大小,之前的例子:18927348 | 347389543 | 834934878,我们知道10进制数每次选择9位不会越界,我们可以直观的得到mag数组的大小为3,但是这样的话每个int元素仍然有些空闲的位没有利用. 因此我们之前的划分方法只是整个数组初始化的想象中第一步. 这个例子按照numWords = (numBits + 31) /32这样计算最后得到的应当仍是3.但是若是再大一些的数串结果就不一定一样,积少成多,很大的数串时节省的空间就能体现出来啦. Java没有无符号int数,因此mag数组中常常会符号为负的元素. 而最终把原大整数转换为mag数组保存的radix对应的最佳进制数的过程由destructiveMulAdd完成.现在把构造函数的最后一部分的和方法destructiveMulAdd的解析附上: int superRadix = intRadix[radix]; int groupVal = 0; while (cursor < val.length()) { //选取新的一串数 group = val.substring(cursor, cursor += digitsPerInt[radix]); groupVal = Integer.parseInt(group, radix);//转换为十进制整数 if (groupVal < 0) throw new NumberFormatException("Illegal digit"); //mag*superRadix+groupVal.类似于:18927348*10^9+347389543 destructiveMulAdd(mag, superRadix, groupVal); } //去掉mag数组前面的0,使得数组元素以非0开始. mag = trustedStripLeadingZeroInts(mag); private final static long LONG_MASK = 0xffffffffL; // Multiply x array times word y in place, and add word z private static void destructiveMulAdd(int[] x, int y, int z) { // Perform the multiplication word by word //将y与z转换为long类型 long ylong = y & LONG_MASK; long zlong = z & LONG_MASK; int len = x.length; long product = 0; long carry = 0; //从低位到高位分别与y相乘,每次都加上之前的进位,和传统乘法一模一样. for (int i = len-1; i >= 0; i--) { //每次相乘时将x[i]转换为long,这样其32位数就可转变为其真正代表的数 product = ylong * (x[i] & LONG_MASK) + carry; //x[i]取乘积的低32位. x[i] = (int)product; //高32位为进位数,留到下次循环相加 carry = product >>> 32; } // Perform the addition //执行加z //mag最低位转换为long后与z相加 long sum = (x[len-1] & LONG_MASK) + zlong; //mag最低位保留相加结果的低32位. x[len-1] = (int)sum; //高32位当成进位数 carry = sum >>> 32; //和传统加法一样进位数不断向高位加 for (int i = len-2; i >= 0; i--) { sum = (x[i] & LONG_MASK) + carry; x[i] = (int)sum; carry = sum >>> 32; } } 整个过程下来,因为保存的方法和我们脑海中那简单的存储方法会有不同,最终mag数组里的元素跟原先的字符串就会有很大的不同,但实质上还是表示着相同的数,现把18927348347389543834934878例子的构造过程展示出: 初始化之后计算得numBits=87,这样数组初始化大小numWords=3. 进入最终的循环前mag数组:[0] [0] [18927348] 第一次循环后: [0] [4406866] [-1295432089] (1892734810^9+347389543) 第二次循环后: [1026053] [-1675546271] [440884830]. ((1892734810^9+347389543)*10^9+834934878) 最终我们就把18927348347389543834934878 转换成10^9进制的数保存到了mag数组中.虽然最终的结果我们让我们不太熟悉,但是其中数串划分的方法和数组节省空间的思想都是值得学习的 现在有最后一个问题,如何mag数组转换为原来的数串呢?JDK里面是通过不断做除法取余实现的,BigInteger类的实例在调用toString方法的时候会返回原先的数串.代码如下: public String toString(int radix) { if (signum == 0) return "0"; if (radix < Character.MIN_RADIX || radix > Character.MAX_RADIX) radix = 10; // Compute upper bound on number of digit groups and allocate space int maxNumDigitGroups = (4*mag.length + 6)/7; String digitGroup[] = new String[maxNumDigitGroups]; // Translate number to string, a digit group at a time BigInteger tmp = this.abs(); int numGroups = 0; while (tmp.signum != 0) { BigInteger d = longRadix[radix]; MutableBigInteger q = new MutableBigInteger(), a = new MutableBigInteger(tmp.mag), b = new MutableBigInteger(d.mag); MutableBigInteger r = a.divide(b, q); BigInteger q2 = q.toBigInteger(tmp.signum * d.signum); BigInteger r2 = r.toBigInteger(tmp.signum * d.signum); digitGroup[numGroups++] = Long.toString(r2.longValue(), radix); tmp = q2; } // Put sign (if any) and first digit group into result buffer StringBuilder buf = new StringBuilder(numGroups*digitsPerLong[radix]+1); if (signum=0; i--) { // Prepend (any) leading zeros for this digit group int numLeadingZeros = digitsPerLong[radix]-digitGroup[i].length(); if (numLeadingZeros != 0) buf.append(zeros[numLeadingZeros]); buf.append(digitGroup[i]); } return buf.toString(); } private static String zeros[] = new String[64]; static { zeros[63] = "000000000000000000000000000000000000000000000000000000000000000"; for (int i=0; i
-
丢弃掉那些BeanUtils工具类吧,MapStruct真香!!! 在前几天的文章《为什么阿里巴巴禁止使用Apache Beanutils进行属性的copy?》中,我曾经对几款属性拷贝的工具类进行了对比。 然后在评论区有些读者反馈说MapStruct才是真的香,于是我就抽时间了解了一下MapStruct。结果我发现,这真的是一个神仙框架,炒鸡香。 这一篇文章就来简单介绍下MapStruct的用法,并且再和其他几个工具类进行一下对比。 为什么需要MapStruct ? 首先,我们先说一下MapStruct这类框架适用于什么样的场景,为什么市面上会有这么多的类似的框架。 在软件体系架构设计中,分层式结构是最常见,也是最重要的一种结构。很多人都对三层架构、四层架构等并不陌生。 甚至有人说:“计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决,如果不行,那就加两层。” 但是,随着软件架构分层越来越多,那么各个层次之间的数据模型就要面临着相互转换的问题,典型的就是我们可以在代码中见到各种O,如DO、DTO、VO等。 一般情况下,同样一个数据模型,我们在不同的层次要使用不同的数据模型。如在数据存储层,我们使用DO来抽象一个业务实体;在业务逻辑层,我们使用DTO来表示数据传输对象;到了展示层,我们又把对象封装成VO来与前端进行交互。 那么,数据的从前端透传到数据持久化层(从持久层透传到前端),就需要进行对象之间的互相转化,即在不同的对象模型之间进行映射。 通常我们可以使用get/set等方式逐一进行字段映射操作,如: personDTO.setName(personDO.getName()); personDTO.setAge(personDO.getAge()); personDTO.setSex(personDO.getSex()); personDTO.setBirthday(personDO.getBirthday()); 但是,编写这样的映射代码是一项冗长且容易出错的任务。MapStruct等类似的框架的目标是通过自动化的方式尽可能多地简化这项工作。 MapStruct的使用 MapStruct(https://mapstruct.org/ )是一种代码生成器,它极大地简化了基于”约定优于配置”方法的Java bean类型之间映射的实现。生成的映射代码使用纯方法调用,因此快速、类型安全且易于理解。 约定优于配置,也称作按约定编程,是一种软件设计范式,旨在减少软件开发人员需做决定的数量,获得简单的好处,而又不失灵活性。 假设我们有两个类需要进行互相转换,分别是PersonDO和PersonDTO,类定义如下: public class PersonDO { private Integer id; private String name; private int age; private Date birthday; private String gender; } public class PersonDTO { private String userName; private Integer age; private Date birthday; private Gender gender; } 我们演示下如何使用MapStruct进行bean映射。 想要使用MapStruct,首先需要依赖他的相关的jar包,使用maven依赖方式如下: ... 1.3.1.Final ... org.mapstruct mapstruct ${org.mapstruct.version} ... org.apache.maven.plugins maven-compiler-plugin 3.8.1 1.8 1.8 org.mapstruct mapstruct-processor ${org.mapstruct.version} 因为MapStruct需要在编译器生成转换代码,所以需要在maven-compiler-plugin插件中配置上对mapstruct-processor的引用。这部分在后文会再次介绍。 之后,我们需要定义一个做映射的接口,主要代码如下: @Mapper interface PersonConverter { PersonConverter INSTANCE = Mappers.getMapper(PersonConverter.class); @Mappings(@Mapping(source = "name", target = "userName")) PersonDTO do2dto(PersonDO person); } 使用注解 @Mapper定义一个Converter接口,在其中定义一个do2dto方法,方法的入参类型是PersonDO,出参类型是PersonDTO,这个方法就用于将PersonDO转成PersonDTO。 测试代码如下: public static void main(String[] args) { PersonDO personDO = new PersonDO(); personDO.setName("Hollis"); personDO.setAge(26); personDO.setBirthday(new Date()); personDO.setId(1); personDO.setGender(Gender.MALE.name()); PersonDTO personDTO = PersonConverter.INSTANCE.do2dto(personDO); System.out.println(personDTO); } 输出结果: PersonDTO{userName='Hollis', age=26, birthday=Sat Aug 08 19:00:44 CST 2020, gender=MALE} 可以看到,我们使用MapStruct完美的将PersonDO转成了PersonDTO。 上面的代码可以看出,MapStruct的用法比较简单,主要依赖@Mapper注解。 但是我们知道,大多数情况下,我们需要互相转换的两个类之间的属性名称、类型等并不完全一致,还有些情况我们并不想直接做映射,那么该如何处理呢? 其实MapStruct在这方面也是做的很好的。 MapStruct处理字段映射 首先,可以明确的告诉大家,如果要转换的两个类中源对象属性与目标对象属性的类型和名字一致的时候,会自动映射对应属性。 那么,如果遇到特殊情况如何处理呢? 名字不一致如何映射 如上面的例子中,在PersonDO中用name表示用户名称,而在PersonDTO中使用userName表示用户名,那么如何进行参数映射呢。 这时候就要使用@Mapping注解了,只需要在方法签名上,使用该注解,并指明需要转换的源对象的名字和目标对象的名字就可以了,如将name的值映射给userName,可以使用如下方式: @Mapping(source = "name", target = "userName") 可以自动映射的类型 除了名字不一致以外,还有一种特殊情况,那就是类型不一致,如上面的例子中,在PersonDO中用String类型表示用户性别,而在PersonDTO中使用一个Genter的枚举表示用户性别。 这时候类型不一致,就需要涉及到互相转换的问题 其实,MapStruct会对部分类型自动做映射,不需要我们做额外配置,如例子中我们将String类型自动转成了枚举类型。 一般情况下,对于以下情况可以做自动类型转换: 基本类型及其他们对应的包装类型。 基本类型的包装类型和String类型之间 String类型和枚举类型之间 自定义常量 如果我们在转换映射过程中,想要给一些属性定义一个固定的值,这个时候可以使用 constant @Mapping(source = "name", constant = "hollis") 类型不一致的如何映射 还是上面的例子,如果我们需要在Person这个对象中增加家庭住址这个属性,那么我们一般在PersonoDTO中会单独定义一个HomeAddress类来表示家庭住址,而在Person类中,我们一般使用String类型表示家庭住址。 这就需要在HomeAddress和String之间使用JSON进行互相转化,这种情况下,MapStruct也是可以支持的。 public class PersonDO { private String name; private String address; } public class PersonDTO { private String userName; private HomeAddress address; } @Mapper interface PersonConverter { PersonConverter INSTANCE = Mappers.getMapper(PersonConverter.class); @Mapping(source = "userName", target = "name") @Mapping(target = "address",expression = "java(homeAddressToString(dto2do.getAddress()))") PersonDO dto2do(PersonDTO dto2do); default String homeAddressToString(HomeAddress address){ return JSON.toJSONString(address); } } 我们只需要在PersonConverter中在定义一个方法(因为PersonConverter是一个接口,所以在JDK 1.8以后的版本中可以定义一个default方法),这个方法的作用就是将HomeAddress转换成String类型。 default方法:Java 8 引入的新的语言特性,用关键字default来标注,被default所标注的方法,需要提供实现,而子类可以选择实现或者不实现该方法 然后在dto2do方法上,通过以下注解方式即可实现类型的转换: @Mapping(target = "address",expression = "java(homeAddressToString(dto2do.getAddress()))") 上面这种是自定义的类型转换,还有一些类型的转换是MapStruct本身就支持的,如String和Date之间的转换: @Mapping(target = "birthday",dateFormat = "yyyy-MM-dd HH:mm:ss") 以上,简单介绍了一些常用的字段映射的方法,也是我自己在工作中经常遇到的几个场景,更多的情况大家可以查看官方的示例(https://github.com/mapstruct/mapstruct-examples)。 MapStruct的性能 前面说了这么多MapStruct的用法,可以看出MapStruct的使用还是比较简单的,并且字段映射上面的功能很强大,那么他的性能到底怎么样呢? 参考《为什么阿里巴巴禁止使用Apache Beanutils进行属性的copy?》中的示例,我们对MapStruct进行性能测试。 分别执行1000、10000、100000、1000000次映射的耗时分别为:0ms、1ms、3ms、6ms。 可以看到,MapStruct的耗时相比较于其他几款工具来说是非常短的。 那么,为什么MapStruct的性能可以这么好呢? 其实,MapStruct和其他几类框架最大的区别就是:与其他映射框架相比,MapStruct在编译时生成bean映射,这确保了高性能,可以提前将问题反馈出来,也使得开发人员可以彻底的错误检查。 还记得前面我们在引入MapStruct的依赖的时候,特别在maven-compiler-plugin中增加了mapstruct-processor的支持吗? 并且我们在代码中使用了很多MapStruct提供的注解,这使得在编译期,MapStruct就可以直接生成bean映射的代码,相当于代替我们写了很多setter和getter。 如我们在代码中定义了以下一个Mapper: @Mapper interface PersonConverter { PersonConverter INSTANCE = Mappers.getMapper(PersonConverter.class); @Mapping(source = "userName", target = "name") @Mapping(target = "address",expression = "java(homeAddressToString(dto2do.getAddress()))") @Mapping(target = "birthday",dateFormat = "yyyy-MM-dd HH:mm:ss") PersonDO dto2do(PersonDTO dto2do); default String homeAddressToString(HomeAddress address){ return JSON.toJSONString(address); } } 经过代码编译后,会自动生成一个PersonConverterImpl: @Generated( value = "org.mapstruct.ap.MappingProcessor", date = "2020-08-09T12:58:41+0800", comments = "version: 1.3.1.Final, compiler: javac, environment: Java 1.8.0_181 (Oracle Corporation)" ) class PersonConverterImpl implements PersonConverter { @Override public PersonDO dto2do(PersonDTO dto2do) { if ( dto2do == null ) { return null; } PersonDO personDO = new PersonDO(); personDO.setName( dto2do.getUserName() ); if ( dto2do.getAge() != null ) { personDO.setAge( dto2do.getAge() ); } if ( dto2do.getGender() != null ) { personDO.setGender( dto2do.getGender().name() ); } personDO.setAddress( homeAddressToString(dto2do.getAddress()) ); return personDO; } } 在运行期,对于bean进行映射的时候,就会直接调用PersonConverterImpl的dto2do方法,这样就没有什么特殊的事情要做了,只是在内存中进行set和get就可以了。 所以,因为在编译期做了很多事情,所以MapStruct在运行期的性能会很好,并且还有一个好处,那就是可以把问题的暴露提前到编译期。 使得如果代码中字段映射有问题,那么应用就会无法编译,强制开发者要解决这个问题才行。 总结 本文介绍了一款Java中的字段映射工具类,MapStruct,他的用法比较简单,并且功能非常完善,可以应付各种情况的字段映射。 并且因为他是编译期就会生成真正的映射代码,使得运行期的性能得到了大大的提升。 强烈推荐,真的很香!!!
-
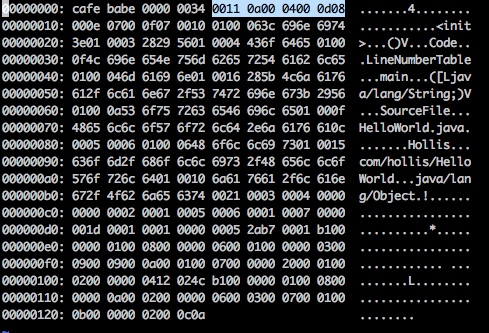
好好说说Java中的常量池之Class常量池 在Java中,常量池的概念想必很多人都听说过。这也是面试中比较常考的题目之一。在Java有关的面试题中,一般习惯通过String的有关问题来考察面试者对于常量池的知识的理解,几道简单的String面试题难倒了无数的开发者。所以说,常量池是Java体系中一个非常重要的概念。 谈到常量池,在Java体系中,共用三种常量池。分别是字符串常量池、Class常量池和运行时常量池。 本文是《好好说说Java中的常量池》系列的第一篇,先来介绍一下到底什么是Class常量池。 什么是Class文件 在Java代码的编译与反编译那些事儿中我们介绍过Java的编译和反编译的概念。我们知道,计算机只认识0和1,所以程序员写的代码都需要经过编译成0和1构成的二进制格式才能够让计算机运行。 我们在《深入分析Java的编译原理》中提到过,为了让Java语言具有良好的跨平台能力,Java独具匠心的提供了一种可以在所有平台上都能使用的一种中间代码——字节码(ByteCode)。 有了字节码,无论是哪种平台(如Windows、Linux等),只要安装了虚拟机,都可以直接运行字节码。 同样,有了字节码,也解除了Java虚拟机和Java语言之间的耦合。这话可能很多人不理解,Java虚拟机不就是运行Java语言的么?这种解耦指的是什么? 其实,目前Java虚拟机已经可以支持很多除Java语言以外的语言了,如Groovy、JRuby、Jython、Scala等。之所以可以支持,就是因为这些语言也可以被编译成字节码。而虚拟机并不关心字节码是有哪种语言编译而来的。 Java语言中负责编译出字节码的编译器是一个命令是javac。 javac是收录于JDK中的Java语言编译器。该工具可以将后缀名为.java的源文件编译为后缀名为.class的可以运行于Java虚拟机的字节码。 如,我们有以下简单的HelloWorld.java代码: public class HelloWorld { public static void main(String[] args) { String s = "Hollis"; } } 通过javac命令生成class文件: javac HelloWorld.java 生成HelloWorld.class文件:  如何使用16进制打开class文件:使用 vim test.class ,然后在交互模式下,输入:%!xxd 即可。 可以看到,上面的文件就是Class文件,Class文件中包含了Java虚拟机指令集和符号表以及若干其他辅助信息。 要想能够读懂上面的字节码,需要了解Class类文件的结构,由于这不是本文的重点,这里就不展开说明了。 读者可以看到,HelloWorld.class文件中的前八个字母是cafe babe,这就是Class文件的魔数(Java中的”魔数”) 我们需要知道的是,在Class文件的4个字节的魔数后面的分别是4个字节的Class文件的版本号(第5、6个字节是次版本号,第7、8个字节是主版本号,我生成的Class文件的版本号是52,这时Java 8对应的版本。也就是说,这个版本的字节码,在JDK 1.8以下的版本中无法运行)在版本号后面的,就是Class常量池入口了。 Class常量池 Class常量池可以理解为是Class文件中的资源仓库。 Class文件中除了包含类的版本、字段、方法、接口等描述信息外,还有一项信息就是常量池(constant pool table),用于存放编译器生成的各种字面量(Literal)和符号引用(Symbolic References)。 由于不同的Class文件中包含的常量的个数是不固定的,所以在Class文件的常量池入口处会设置两个字节的常量池容量计数器,记录了常量池中常量的个数。  当然,还有一种比较简单的查看Class文件中常量池的方法,那就是通过javap命令。对于以上的HelloWorld.class,可以通过 javap -v HelloWorld.class 查看常量池内容如下:  从上图中可以看到,反编译后的class文件常量池中共有16个常量。而Class文件中常量计数器的数值是0011,将该16进制数字转换成10进制的结果是17。 原因是与Java的语言习惯不同,常量池计数器是从0开始而不是从1开始的,常量池的个数是10进制的17,这就代表了其中有16个常量,索引值范围为1-16。 常量池中有什么 介绍完了什么是Class常量池以及如何查看常量池,那么接下来我们就要深入分析一下,Class常量池中都有哪些内容。 常量池中主要存放两大类常量:字面量(literal)和符号引用(symbolic references)。 字面量 前面说过,运行时常量池中主要保存的是字面量和符号引用,那么到底什么字面量? 在计算机科学中,字面量(literal)是用于表达源代码中一个固定值的表示法(notation)。几乎所有计算机编程语言都具有对基本值的字面量表示,诸如:整数、浮点数以及字符串;而有很多也对布尔类型和字符类型的值也支持字面量表示;还有一些甚至对枚举类型的元素以及像数组、记录和对象等复合类型的值也支持字面量表示法。 以上是关于计算机科学中关于字面量的解释,并不是很容易理解。说简单点,字面量就是指由字母、数字等构成的字符串或者数值。 字面量只可以右值出现,所谓右值是指等号右边的值,如:int a=123这里的a为左值,123为右值。在这个例子中123就是字面量。 int a = 123; String s = "hollis"; 上面的代码事例中,123和hollis都是字面量。 本文开头的HelloWorld代码中,Hollis就是一个字面量。 符号引用 常量池中,除了字面量以外,还有符号引用,那么到底什么是符号引用呢。 符号引用是编译原理中的概念,是相对于直接引用来说的。主要包括了以下三类常量: * 类和接口的全限定名 * 字段的名称和描述符 * 方法的名称和描述符 这也就可以印证前面的常量池中还包含一些com/hollis/HelloWorld、main、([Ljava/lang/String;)V等常量的原因了。 Class常量池有什么用 前面介绍了这么多,关于Class常量池是什么,怎么查看Class常量池以及Class常量池中保存了哪些东西。有一个关键的问题没有讲,那就是Class常量池到底有什么用。 首先,可以明确的是,Class常量池是Class文件中的资源仓库,其中保存了各种常量。而这些常量都是开发者定义出来,需要在程序的运行期使用的。 在《深入理解Java虚拟》中有这样的表述: Java代码在进行Javac编译的时候,并不像C和C++那样有“连接”这一步骤,而是在虚拟机加载Class文件的时候进行动态连接。也就是说,在Class文件中不会保存各个方法、字段的最终内存布局信息,因此这些字段、方法的符号引用不经过运行期转换的话无法得到真正的内存入口地址,也就无法直接被虚拟机使用。当虚拟机运行时,需要从常量池获得对应的符号引用,再在类创建时或运行时解析、翻译到具体的内存地址之中。关于类的创建和动态连接的内容,在虚拟机类加载过程时再进行详细讲解。 前面这段话,看起来很绕,不是很容易理解。其实他的意思就是: Class是用来保存常量的一个媒介场所,并且是一个中间场所。在JVM真的运行时,需要把常量池中的常量加载到内存中。 至于到底哪个阶段会做这件事情,以及Class常量池中的常量会以何种方式被加载到具体什么地方,会在本系列文章的后续内容中继续阐述。欢迎关注我的博客(http://www.hollischuang.com) 和公众号(Hollis),即可第一时间获得最新内容。 另外,关于常量池中常量的存储形式,以及数据类型的表示方法本文中并未涉及,并不是说这部分知识点不重要,只是Class字节码的分析本就枯燥,作者不想在一篇文章中给读者灌输太多的理论上的内容。感兴趣的读者可以自行Google学习,如果真的有必要,我也可以单独写一篇文章再深入介绍。 参考资料 《深入理解java虚拟机》 《Java虚拟机原理图解》 1.2.2、Class文件中的常量池详解(上)
-
-
深度分析Java的枚举类型----枚举的线程安全性及序列化问题 写在前面:Java SE5提供了一种新的类型-Java的枚举类型,关键字enum可以将一组具名的值的有限集合创建为一种新的类型,而这些具名的值可以作为常规的程序组件使用,这是一种非常有用的功能。本文将深入分析枚举的源码,看一看枚举是怎么实现的,他是如何保证线程安全的,以及为什么用枚举实现的单例是最好的方式。 枚举是如何保证线程安全的 要想看源码,首先得有一个类吧,那么枚举类型到底是什么类呢?是enum吗?答案很明显不是,enum就和class一样,只是一个关键字,他并不是一个类,那么枚举是由什么类维护的呢,我们简单的写一个枚举: public enum t { SPRING,SUMMER,AUTUMN,WINTER; } 然后我们使用反编译,看看这段代码到底是怎么实现的,反编译(Java的反编译)后代码内容如下: public final class T extends Enum { private T(String s, int i) { super(s, i); } public static T[] values() { T at[]; int i; T at1[]; System.arraycopy(at = ENUM$VALUES, 0, at1 = new T[i = at.length], 0, i); return at1; } public static T valueOf(String s) { return (T)Enum.valueOf(demo/T, s); } public static final T SPRING; public static final T SUMMER; public static final T AUTUMN; public static final T WINTER; private static final T ENUM$VALUES[]; static { SPRING = new T("SPRING", 0); SUMMER = new T("SUMMER", 1); AUTUMN = new T("AUTUMN", 2); WINTER = new T("WINTER", 3); ENUM$VALUES = (new T[] { SPRING, SUMMER, AUTUMN, WINTER }); } } 通过反编译后代码我们可以看到,public final class T extends Enum,说明,该类是继承了Enum类的,同时final关键字告诉我们,这个类也是不能被继承的。当我们使用enmu来定义一个枚举类型的时候,编译器会自动帮我们创建一个final类型的类继承Enum类,所以枚举类型不能被继承,我们看到这个类中有几个属性和方法。 我们可以看到: public static final T SPRING; public static final T SUMMER; public static final T AUTUMN; public static final T WINTER; private static final T ENUM$VALUES[]; static { SPRING = new T("SPRING", 0); SUMMER = new T("SUMMER", 1); AUTUMN = new T("AUTUMN", 2); WINTER = new T("WINTER", 3); ENUM$VALUES = (new T[] { SPRING, SUMMER, AUTUMN, WINTER }); } 都是static类型的,因为static类型的属性会在类被加载之后被初始化,我们在深度分析Java的ClassLoader机制(源码级别)和Java类的加载、链接和初始化两个文章中分别介绍过,当一个Java类第一次被真正使用到的时候静态资源被初始化、Java类的加载和初始化过程都是线程安全的。所以,创建一个enum类型是线程安全的。 为什么用枚举实现的单例是最好的方式 在[转+注]单例模式的七种写法中,我们看到一共有七种实现单例的方式,其中,Effective Java作者Josh Bloch 提倡使用枚举的方式,既然大神说这种方式好,那我们就要知道它为什么好? 1. 枚举写法简单 写法简单这个大家看看[转+注]单例模式的七种写法里面的实现就知道区别了。 public enum EasySingleton{ INSTANCE; } 你可以通过EasySingleton.INSTANCE来访问。 2. 枚举自己处理序列化 我们知道,以前的所有的单例模式都有一个比较大的问题,就是一旦实现了Serializable接口之后,就不再是单例得了,因为,每次调用 readObject()方法返回的都是一个新创建出来的对象,有一种解决办法就是使用readResolve()方法来避免此事发生。但是,为了保证枚举类型像Java规范中所说的那样,每一个枚举类型极其定义的枚举变量在JVM中都是唯一的,在枚举类型的序列化和反序列化上,Java做了特殊的规定。原文如下: Enum constants are serialized differently than ordinary serializable or externalizable objects. The serialized form of an enum constant consists solely of its name; field values of the constant are not present in the form. To serialize an enum constant, ObjectOutputStream writes the value returned by the enum constant’s name method. To deserialize an enum constant, ObjectInputStream reads the constant name from the stream; the deserialized constant is then obtained by calling the java.lang.Enum.valueOf method, passing the constant’s enum type along with the received constant name as arguments. Like other serializable or externalizable objects, enum constants can function as the targets of back references appearing subsequently in the serialization stream. The process by which enum constants are serialized cannot be customized: any class-specific writeObject, readObject, readObjectNoData, writeReplace, and readResolve methods defined by enum types are ignored during serialization and deserialization. Similarly, any serialPersistentFields or serialVersionUID field declarations are also ignored–all enum types have a fixedserialVersionUID of 0L. Documenting serializable fields and data for enum types is unnecessary, since there is no variation in the type of data sent. 大概意思就是说,在序列化的时候Java仅仅是将枚举对象的name属性输出到结果中,反序列化的时候则是通过java.lang.Enum的valueOf方法来根据名字查找枚举对象。同时,编译器是不允许任何对这种序列化机制的定制的,因此禁用了writeObject、readObject、readObjectNoData、writeReplace和readResolve等方法。 我们看一下这个valueOf方法: public static T valueOf(Class enumType,String name) { T result = enumType.enumConstantDirectory().get(name); if (result != null) return result; if (name == null) throw new NullPointerException("Name is null"); throw new IllegalArgumentException( "No enum const " + enumType +"." + name); } 从代码中可以看到,代码会尝试从调用enumType这个Class对象的enumConstantDirectory()方法返回的map中获取名字为name的枚举对象,如果不存在就会抛出异常。再进一步跟到enumConstantDirectory()方法,就会发现到最后会以反射的方式调用enumType这个类型的values()静态方法,也就是上面我们看到的编译器为我们创建的那个方法,然后用返回结果填充enumType这个Class对象中的enumConstantDirectory属性。 所以,JVM对序列化有保证。 3.枚举实例创建是thread-safe(线程安全的) 我们在深度分析Java的ClassLoader机制(源码级别)和Java类的加载、链接和初始化两个文章中分别介绍过,当一个Java类第一次被真正使用到的时候静态资源被初始化、Java类的加载和初始化过程都是线程安全的。所以,创建一个enum类型是线程安全的。